
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



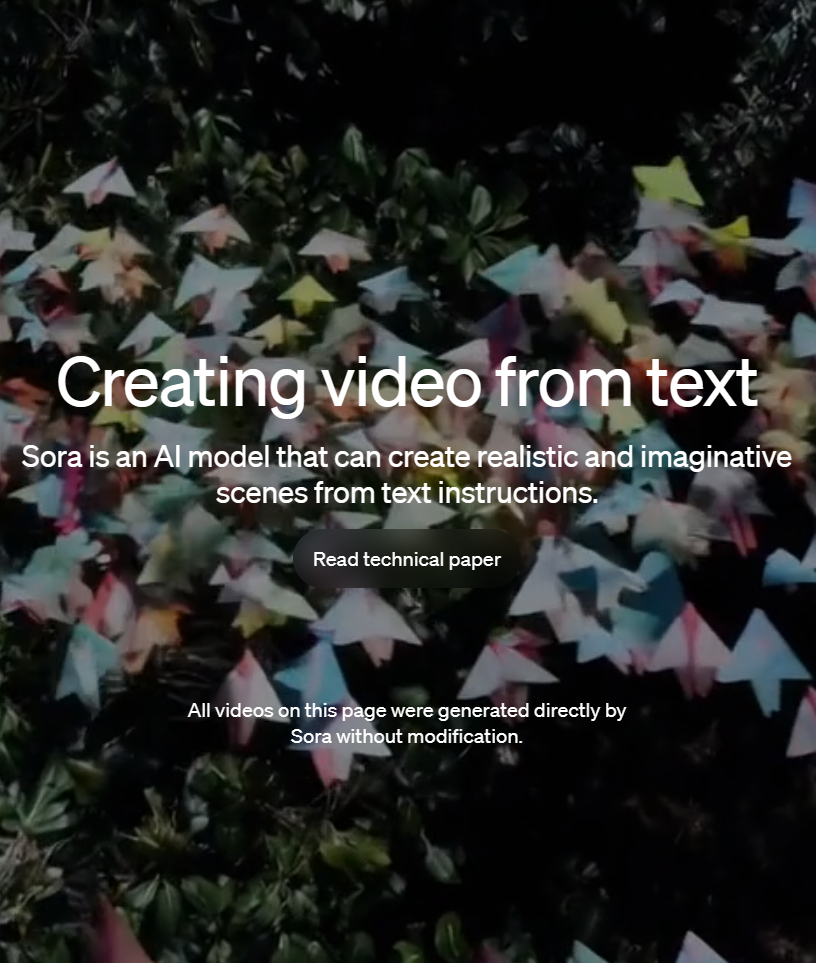
OpenAI宣布发布全新的Diffusion大模型Sora,这是一个可以生成最长60秒视频的视频生成大模型,最大的特点是可以生成非常逼真的电影画面版的视频。
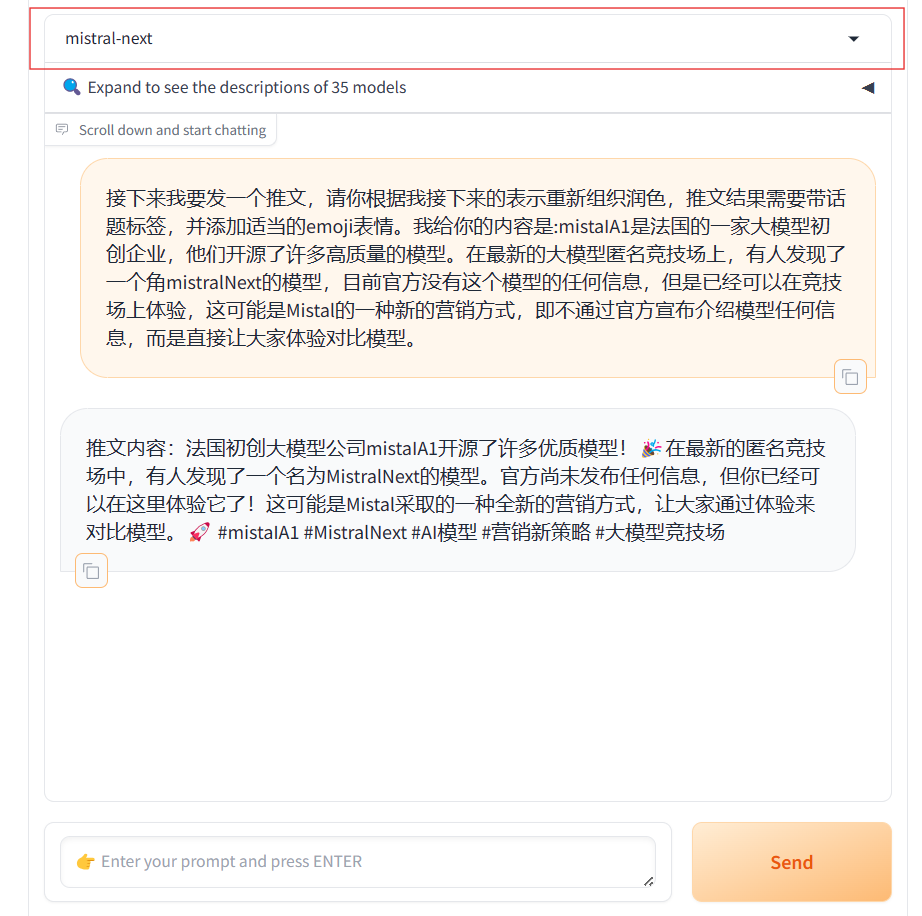
MistralAI又悄悄地上线了另一个模型,即Mistral Next。相比之前的发布预训练种子引起大家猜测的方式,本次MistralAI又把模型发布玩出了花,他们没有公布任何信息,选择直接上架LM-SYS的大模型竞技场Chat Arena,让大家直接体验对比。
今天阿里巴巴开源了他们家第二代的Qwen系列大语言模型(准确说是1.5代),从官方给出的测评结果看,Qwen1.5系列大模型相比较第一代有非常明显的进步,其中720亿参数规模版本的Qwen1.5-72B-Chat在各项评测结果中都非常接近GPT-4的模型,在MT-Bench的得分中甚至超过了此前最为神秘但最接近GPT-4水平的Mistral-Medium模型。
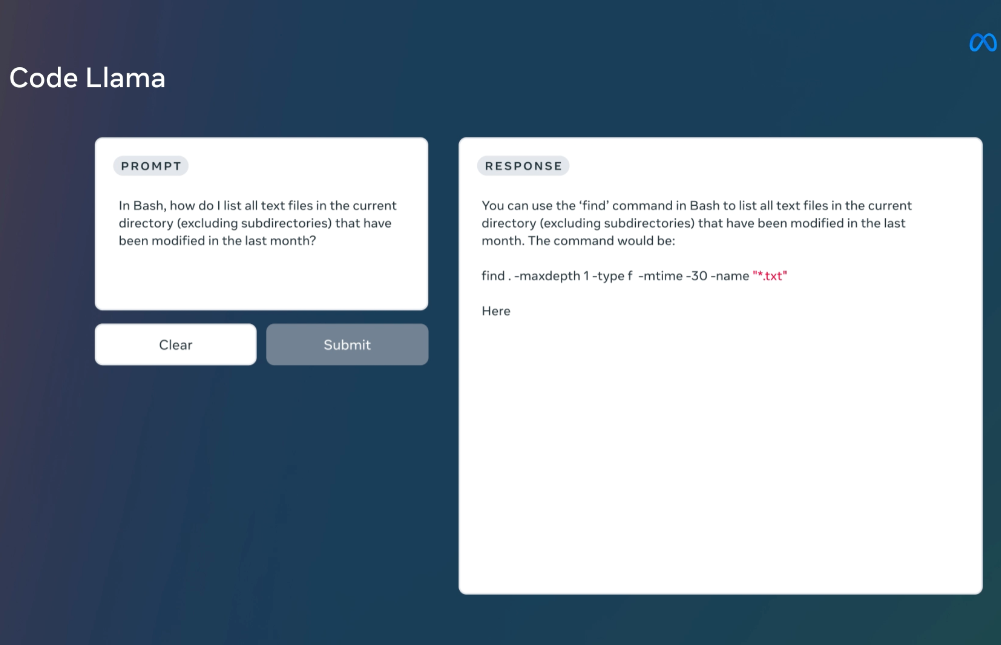
MetaAI发布的LLaMA系列开源大语言模型已经是开源大模型领域最重要的力量了。相当多的所谓开源大模型都是基于这个模型微调得到。在上个月,LLaMA2发布,吸引了全球非常多的关注,也有相当多的后续模型基于LLaMA2进行优化。而今天MetaAI再次开源全新的编程大模型——CodeLLaMA系列,这是MetaAI第一次发布编程大模型,本次发布的CodeLLaMA共有9个版本,分别是CodeLLaMA系列、针对Python优化的CodeLLaMA-Python系列和针对指令优化的CodeLLaMA-Inst

决定向量检索准确性的核心是向量大模型的能力,即文本转成embedding向量是否准确。今天,OpenAI宣布了他们第三代向量大模型text-embedding,模型能力增强的同时价格下降!

OpenAI的CEO Sam最近参加了世界经济论坛,发表了几场演讲。有网友听了完整的Sam的4-5场演讲,并从中抽取了Sam关于GPT-5相关的论述。从中我们可以看到未来GPT-5可能的样子。这里为大家总结翻译一下。
GGML是在大模型领域常见的一种文件格式。HuggingFace上著名的开发者Tom Jobbins经常发布带有GGML名称字样的大模型。通常是模型名+GGML后缀,那么这个名字的模型是什么?GGML格式的文件名的大模型是什么样的大模型格式?如何使用?本文将简单介绍。

OpenAI在2023年3月份发布了GPT-4,10个月过去了,目前也没有任何一家产品或者模型可以打败GPT-4。但是,很多人都对2024年抱有非常好的期待,认为2024年会出现能与GPT-4竞争的大模型。包括MistralAI的CEO也说他们会在2024年发布性能媲美GPT-4的大模型。但是,Google前AI研究人员,GalileoAI的联合创始人认为2024年也不会出现这种情况。

2022年11月底,ChatGPT横空出世,全球都被这样一个“好像”有智能的产品吸引力。随后,工业界、科研机构开始疯狂投入大模型。在2023年,这个被称为大模型元年的年份,有很多令人瞩目的AI产品与模型发布。2023年,DataLearner收集了大量的大模型,并发布了很多大模型相关的技术博客,在即将结束的2023年,我们以这个『2023年最令人瞩目的AI产品』结束本年的技术分享。
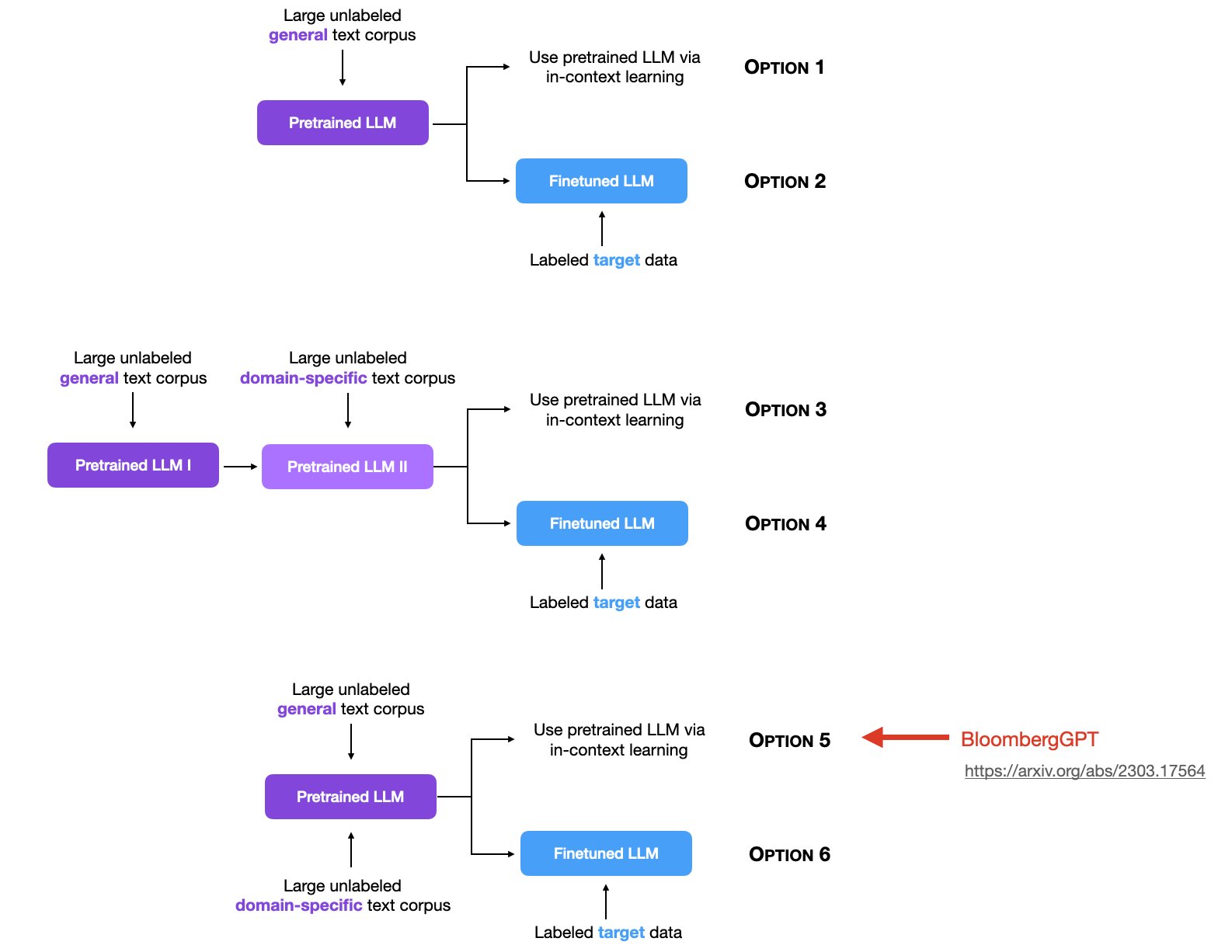
Sebastian Raschka是LightningAI的首席科学家,也是前威斯康星大学麦迪逊分校的统计学助理教授。他在大模型领域有非常深的简介,也贡献了许多有价值的内容。在最新的一期统计中,他总结了6种大模型的使用方法,引起了广泛的讨论。其中,关于使用领域数据集做无监督预训练是目前讨论较少,但十分重要的一个方向。

大模型的微调是当前很多人都在做的事情。微调可以让大语言模型适应特定领域的任务,识别特定的指令等。但是大模型的微调需要的显存较高,而且比较难以估计。与推理不同,微调过程微调方法的选择以及输入序列的长度、批次大小都会影响微调显存的需求。本文根据LLaMA Factory的数据总结一下大模型微调的显存要求。
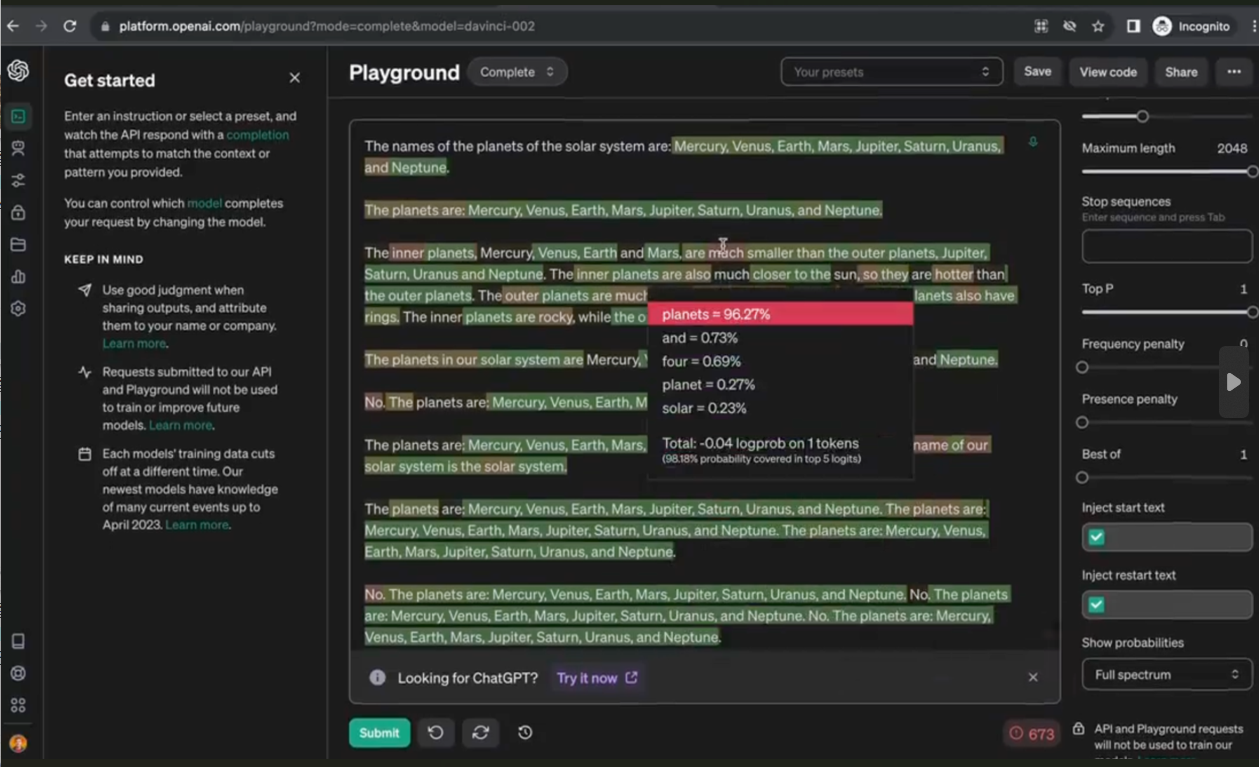
在最新的OpenAI官方接口文档中,新增了top_logprobs和logprobs这2个参数。这2个参数是一起配合使用的。后者是一个布尔类型,表明模型的返回结果中是否增加输出每个token的概率,而top_logprobs参数是一个整数类型,取值范围是0-5之间。如果top_logprobs设置为true,那么模型会根据top_logprobs的设置结果,返回输出结果中每个token及其后续的n个单词的概率。

Google Gemini是Google最新发布的大模型系列。这是一系列的多模态的大模型,谷歌官方宣布在各项评分中Gemini超过了GPT-4V。但是,谷歌的宣传视频过于夸张被很多人质疑造假嫌疑,导致被全网嘲讽。而今天,Google官方的Gemini多模态接口开放,DataLearnerAI第一时间申请测试,结果让人惊喜。

最近一段时间,很多人普遍反映GPT-4变得懒散和愚笨,很多此前可以回答的问题在最近一段时间都无法回答,或者回答比较简单。为此,OpenAI官方也在前几天发布信息说的确收到了这样的信息,但是模型并没有在最近一个多月更新过,所以他们也在好奇是什么原因。而今天的一些测试表明,GPT-4模型会像人一样在不同的时间段有不同的效率。
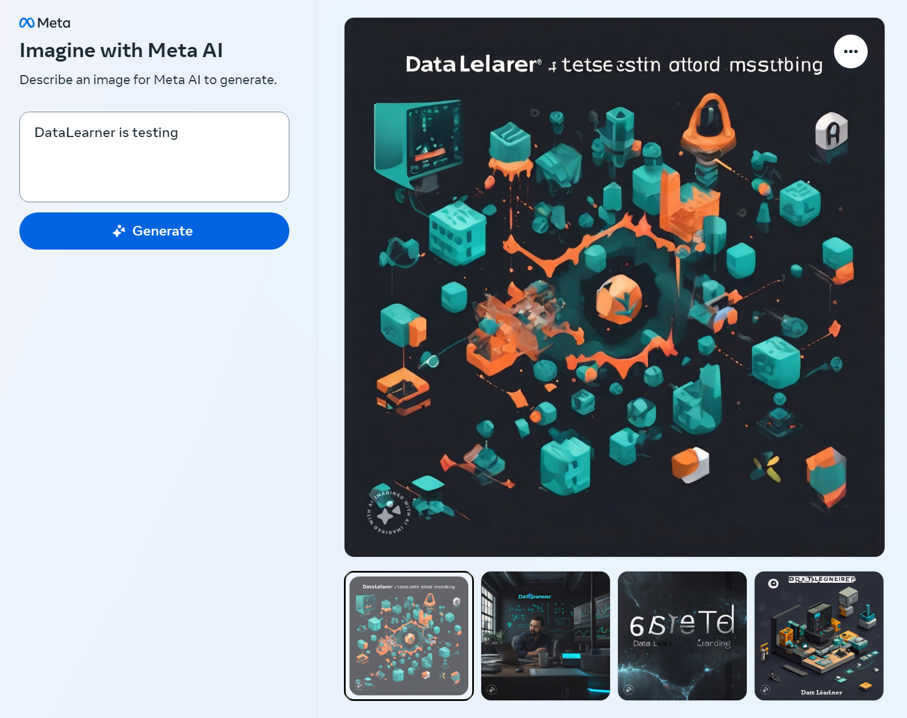
在2023年的9月26日,MetaAI发布了一个Emu大模型,这是一个文本生成图像大模型,基于28亿参数的U-Net进行预训练得到,然后使用几千张高质量图像进行质量微调(Quality-Tuning)来提高模型的效果。不过,Emu模型并没有开源。但是,上周,Meta官方发布了一个全新的独立的文本生成图像系统Imagine,可以免费创作图像,质量很高。