
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




OpenAI最新发布了GPT-3.5-Turbo-Instruct,这是一款强大的指令遵循大模型。尽管官方没有发布官方博客介绍,但我们将在本文中详细探讨这一模型的特点以及其在人工智能领域的价值。
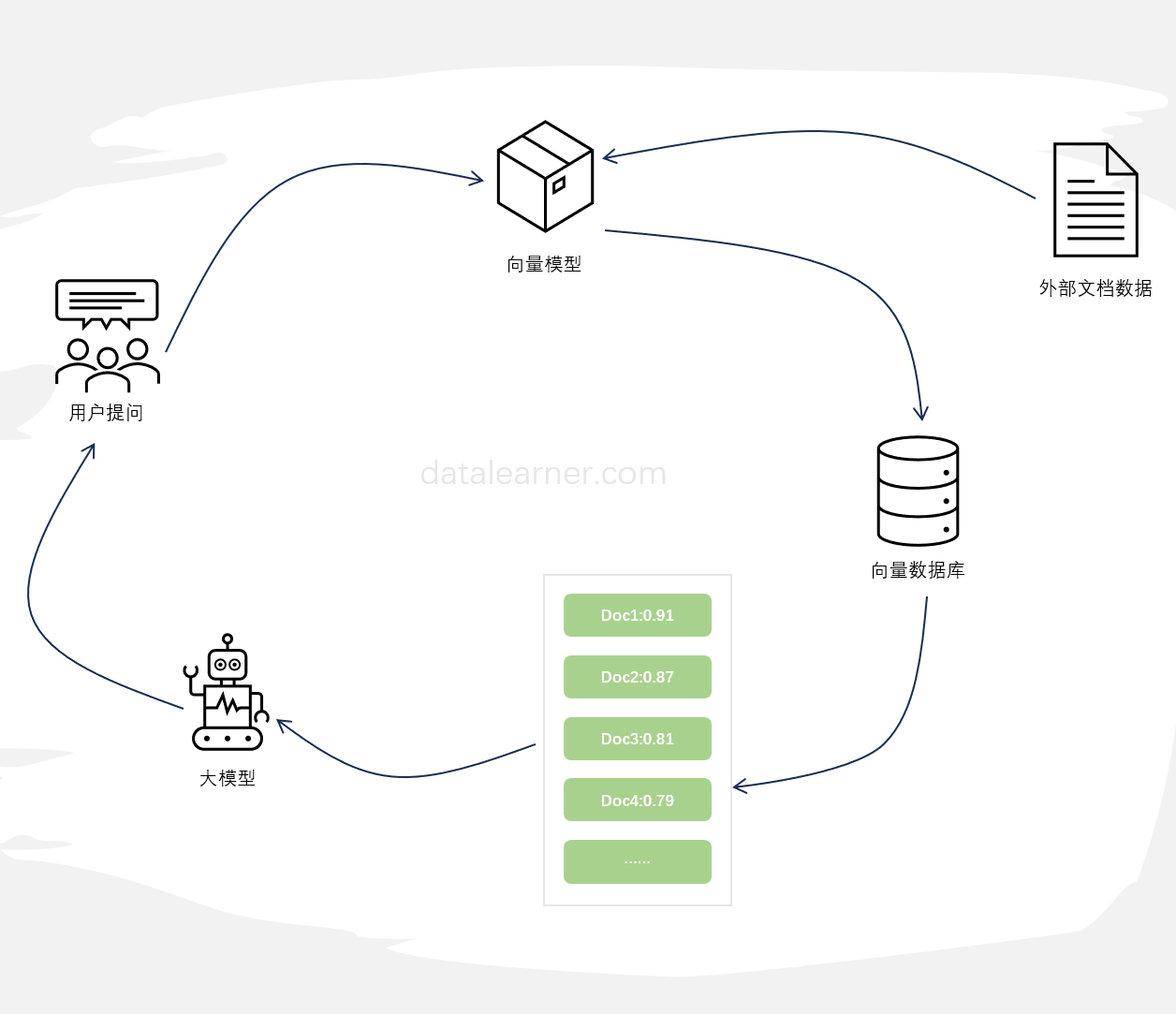
检索增强生成(Retrieval-augmented generation,RAG)是一种将外部知识检索与大型语言模型生成相结合的方法,通常用于问答系统。当前使用大模型基于外部知识检索结果进行问答是当前大模型与外部知识结合最典型的方式,也是检索增强生成最新的应用。然而,近期的研究表明,这种方式并不总是最佳选择,特别是当检索到的文档数量较多时,这种方式很容易出现回答不准确的情况。为此,LangChain最新推出了LongContextReorder,推出了一种新思路解决这个问题。

大模型的长输入在很多场景下都有非常重要的应用,如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。昨天,斯坦福大学、加州伯克利大学和Samaya AI的研究人员联合发布的一个论文中有一个非常有意思的发现:当相关信息出现在输入上下文的开始或结束时,大模型的性能通常最高,而当大模型必须访问长上下文中间的相关信息时,性能显著下降。本文将简单介绍一下这个现象。
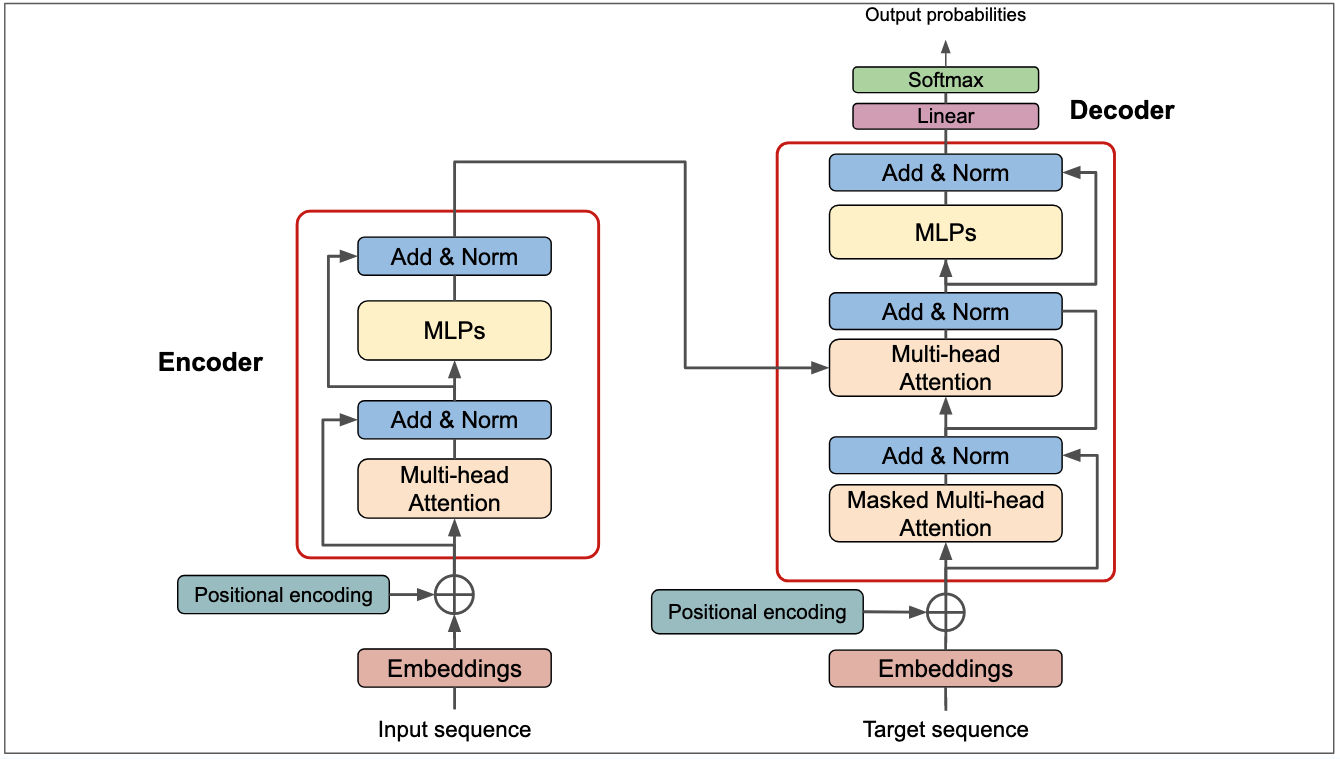
CMU的工程人工智能硕士学位的研究生Jean de Nyandwi近期发表了一篇博客,详细介绍了当前大语言模型主流架构Transformer的历史发展和当前现状。这篇博客非常长,超过了1万字,20多个图,涵盖了Transformer之前的架构和发展。此外,这篇长篇介绍里面的公式内容并不多,所以对于害怕数学的童鞋来说也是十分不错。本文是其翻译版本,欢迎大家仔细学习。

在当今的人工智能领域,大型语言模型(LLM)已成为备受瞩目的研究方向之一。它们能够理解和生成人类语言,为各种自然语言处理任务提供强大的能力。然而,这些模型的训练不仅仅是将数据输入神经网络,还包括一个复杂的管线,其中包括预训练、监督微调和对齐三个关键步骤。本文将详细介绍这三个步骤,特别关注强化学习与人类反馈(RLHF)的作用和重要性。
百川智能是前搜狗创始人王小川创立的一个大模型创业公司,主要的目标是提供大模型底座来提供各种服务。虽然成立很晚(在2023年4月份成立),但是三个月后便发布开源了Baichuan系列开源模型,并上架了Baichun-53B的大模型聊天服务。这些模型受到了广泛的关注和很高的平均。而2个月后,百川智能再次开源第二代baichuan系列大模型,其能力提升明显。

大模型对显卡资源的消耗是很大的。但是,具体每个模型消耗多少显存,需要多少资源大模型才能比较好的运行是很多人关心的问题。此前,DataLearner曾经从理论上给出了大模型显存需求的估算逻辑,详细说明了大模型在预训练阶段、微调阶段和推理阶段所需的显存资源估计,而HuggingFace的官方库Accelerate直接推出了一个在线大模型显存消耗资源估算工具Model Memory Calculator,直接可以估算在HuggingFace上托管的模型的显存需求。

当前的大语言模型主要是预训练大模型,在大规模无监督数据上训练之后,再经过有监督微调和对齐之后就可以完成很多任务。尽管如此,面对垂直领域的应用,大模型依然需要微调才能获得更好地应用结果。而大模型的微调有很多方式,包括指令微调、有监督微调、提示工程等。其中,指令微调(Instruction Tuning)作为改进模型可控性最重要的一类方法,缺少深入的研究。浙江大学研究人员联合Shannon AI等单位发布了一篇最新的关于指令微调的综述,详细描述指令微调的各方面内容。

大语言模型(Large Language Model,LLM)已经在很多领域都产生了巨大的影响。但是其中最为大家所期待的功能之一就是基于idea生成PPT、Word文档等。此前微软Office Copilot已经吸引了很多人的关注,但目前依然没有开放。而今天DataLearnerAI发现了一个类似的产品,来自洛杉矶初创企业Gamma的产品目前已经支持基于文本生成PPT、Word和网页应用了,本文带大家简单体验一下这个产品。

据传,Meta公司即将推出一款名为Code LLaMA的开源AI模型,用于生成编程代码。这一新模型被视为与OpenAI的Codex模型竞争的产品,并建立在Meta最近发布的LLaMA 2上。以下是关于这一新技术的详细分析。

随着近年来GPT-3、ChatGPT等大模型的兴起,高质量的数据集在模型训练中扮演着越来越重要的角色。但是当前领先的预训练模型使用的数据集细节往往不公开,开源数据的匮乏制约着研究社区的进一步发展。特别是大规模中文数据集十分缺乏,对中文大模型以及业界模型的中文支持都有很大的影响。此次,上海人工智能实验室发布的这个数据集包含了丰富的中文,对于大模型的中文能力提升十分有价值。

当谈及人工智能的巨大进步,大模型的崛起无疑是其中的一个重要里程碑。这些大模型,如GPT-3,已经展现出令人惊叹的语言生成和理解能力,但是为了让它们在特定任务上发挥最佳性能,大模型微调(Fine-tuning)是一种非常优秀的方法。微调是一种将预训练的大型模型进一步优化,以适应特定任务或领域的过程。但微调并不是很简单,今天吴恩达联合Lamini推出了全新的大模型微调短课《Finetuning Large Language Models》。

OpenAI在2023年8月份发布了GPT-3.5的微调接口,并表示会在2023年秋天开放16K的gpt-3.5-turbo-16k模型和GPT-4的微调(参考:[重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口](https://www.datalearner.com/blog/1051692752268726 "重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口"))。然而,微调并不是一个简单的问题,如何对大模型微调以及如果微调出现问题

SQLCoder 是 Defog 团队推出的一款前沿的语言模型,专门用于将自然语言问题转化为 SQL 查询。这是一个拥有150亿参数的模型,其性能略微超过了 gpt-3.5-turbo 在自然语言到 SQL 生成任务上,并且显著地超越了所有流行的开源模型。更令人震惊的是,尽管 SQLCoder 的大小只有 text-davinci-003 的十分之一,但其性能却远超后者。

开源大语言模型的发展非常迅速,其强大的能力也吸引了很多人的尝试与体验。尽管预训练大语言模型的使用并不复杂,但是,因为其对GPU资源的消耗很大,导致很多人并不能很好地运行加载模型,也做了很多浪费时间的工作。其中一个比较的的问题就是很多人并不知道自己的显卡支持多大参数规模的模型运行。本文将针对这个问题做一个非常简单的介绍和估算。