
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




前几天,北京智源人工智能研究院引入了一个名为WuDaoMM的大规模多模态语料库,总共包含超过6.5亿对图像-文本。具体来说,约有6亿对数据是从图像和标题呈现弱相关的多个网页中收集的,另外5000万对强相关的图像-文本是从一些高质量的图片网站中收集的。
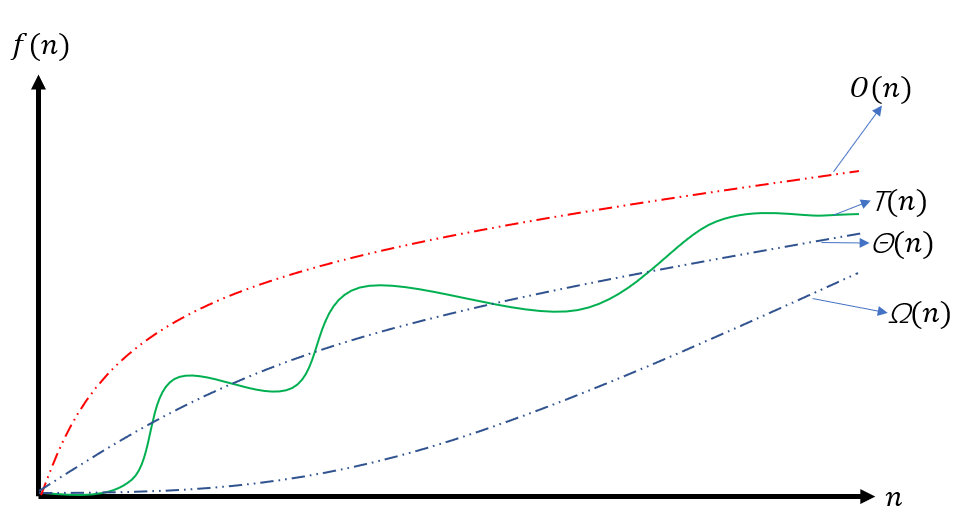
在程序设计和编程中,我们经常会看到关于时间复杂度的讨论。比如为什么A方法比B方法好?是因为A方法的时间复杂度低。那么,这里的时间复杂度如何去理解,又怎么计算呢?常见的O(n)的含义是什么?本文将简单的解释这个概念。
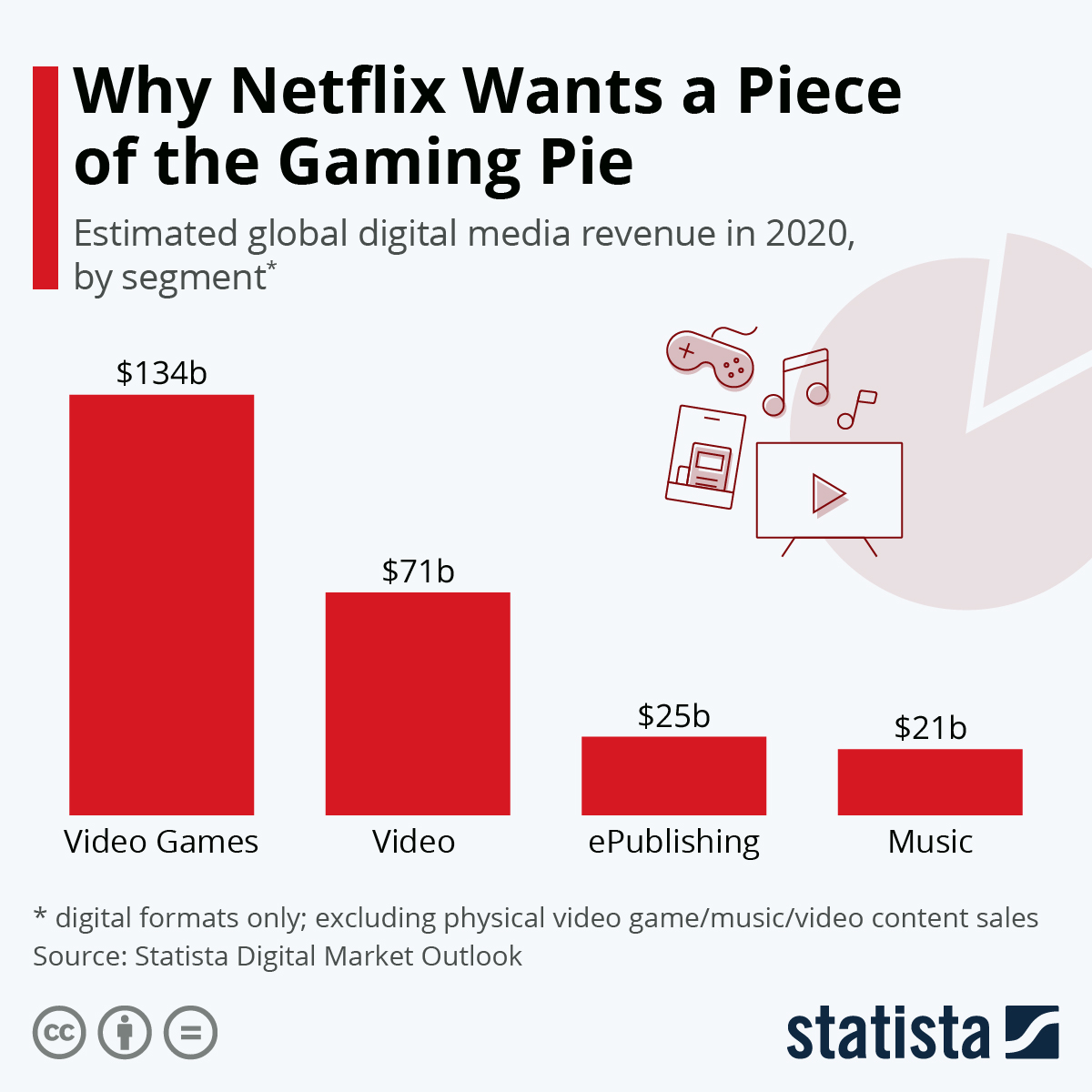
Netflix是一家网络视频服务公司,国内的爱奇艺、腾讯视频都与此类似。前几年大火的《纸牌屋》也就是这家公司提供的。当时最热吵的就是说Netflix凭借大数据选择的剧本形式与演员,让搞数据科学的人风光了好一阵。最近很火的《鱿鱼游戏》也是在Netflix全球独家播出。那么,网络视频搞得这么火热的Netflix为啥要开始搞游戏呢?这里有几个统计数据图可以解释Netflix这样做的原因。
当数据量达到一定程度,单机的处理能力会无法达到性能的要求,采用并行计算,并利用多台服务器进行分布式处理可能会提升数据处理的速度,达到性能要求。然而如果使用不当,并行处理可能并不会提升处理的速度。这篇博客介绍了Dask中关于并行处理的一些效率方面的建议,尽管是针对Dask的说明,但对于所有的并行处理来说都是适用的。

数据结构中,自平衡二叉查找树搜索效率高,但是需要通过旋转和变色维护平衡。而列表虽然简单,但是对元素的查找需要比对列表中的每个元素,查找速度较慢。为了兼顾列表的简单易用,并提高查找效率,跳跃列表(Skip List)应运而生。

红黑树(Red-Black Tree)也是一种自平衡二叉查找树,与AVL不同的是它依靠节点颜色来维护树的平衡,在自平衡操作的时候,依赖变色和旋转两种操作来进行。
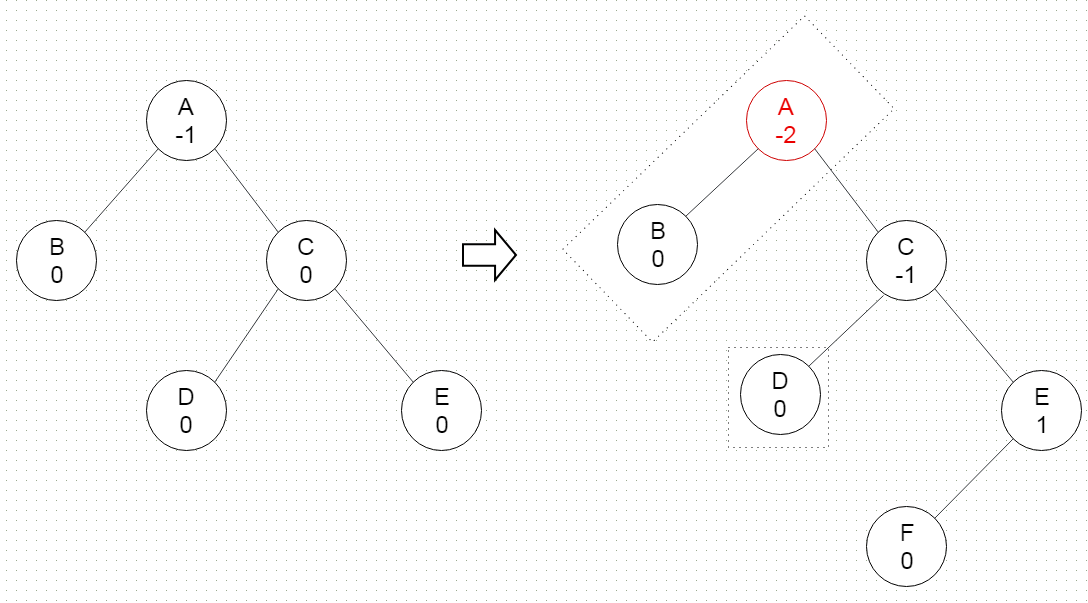
在前面的内容中,我们已经介绍了平衡二叉树。其中提到了AVL树,这是一种非常著名的平衡二叉树。这是第一个发明类似自平衡机制的二叉树数据结构。在AVL树中,任何节点的两个子树的高度最多相差一个。如果在任何时候它们相差多于一个,则重新平衡以恢复此属性。
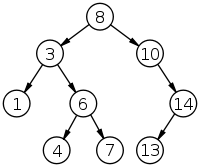
二叉查找树是一种特殊的二叉树结构,它改善了二叉树的查找效率,二叉查找树相比于其他数据结构的优势在于查找、插入的时间复杂度较低。与一般的二叉树的主要区别就是它对子节点的键值排序有一定要求。
平衡二叉树(Balanced Binary Tree)是二叉树(Binary Tree)中最重要的一种树结构。由于它保证了一个良好的二叉树形结构,使得其查找、搜索和删除等操作的效率大大提高,是应用最广泛的二叉树。
随着互联网的高速发展,人类进入了一个信息爆炸的时代,每个人的生活都充满了结构化和非结构化的数据。另外,随着以博客、社交网络、基于位置的服务LBS为代表的新型信息发布方式的不断涌现,以及云计算、物联网技术的兴起,数据正以前所未有的速度在不断地增长和积累,数据已经渗透到当今每一个行业和业务职能领域成为重要的产生因素,以数据为驱动的大数据时代已经不可避免地到来。本文主要围绕大数据特征、处理系统、以及大数据分析来阐述大数据环境下的数据分析在思想、流程、方法等方面的转变,以及围绕此主题而出现的相关关键技术与方法。
今日推荐
Claude开始转向收费模式!推出Claude Pro,定价20美元一个月解锁PDF理解最强大模型的能力~
PandasTutor——一个用于可视化pandas操作的神器
MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!
平衡二叉树之AVL树(Adelson-Velsky and Landis Tree)简介及Java实现
国产大模型进展神速!清华大学NLP小组发布顶尖多模态大模型:VisCPM,支持文本生成图片与多模态对话,图片理解能力优秀!