
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



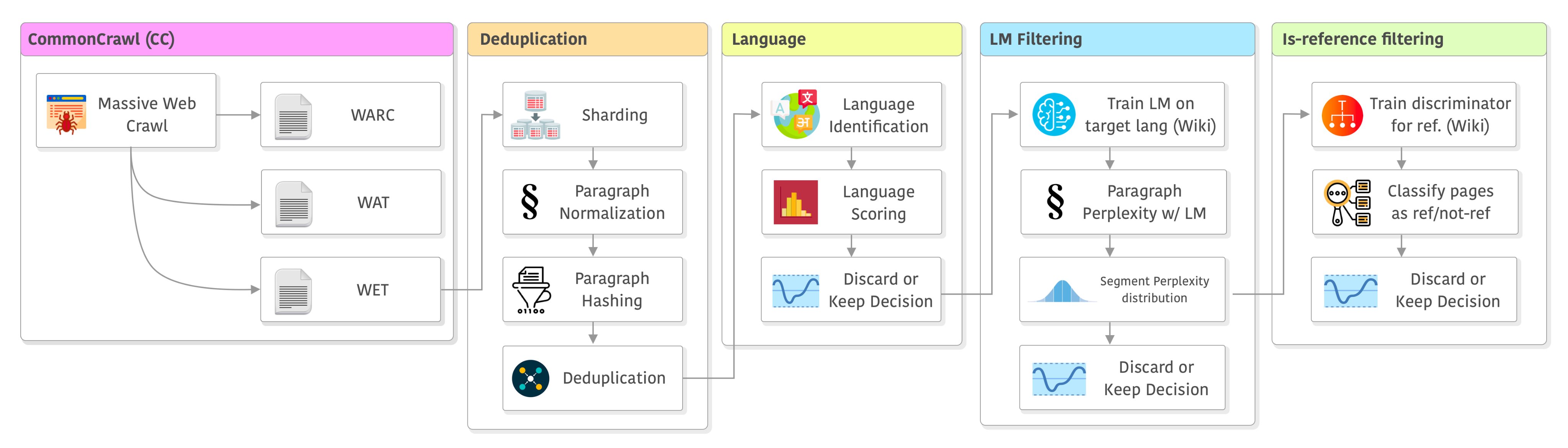
大语言模型的训练是一个十分复杂的技术,不仅涉及到模型的开发与部署,还涉及到数据的获取。与常规的算法模型不同的是,大语言模型通常需要大量的数据处理步骤。本文是根据英国一位自动工程师总结的大语言模型训练之前的数据处理步骤和决策过程。

当数据量达到一定程度,单机的处理能力会无法达到性能的要求,采用并行计算,并利用多台服务器进行分布式处理可能会提升数据处理的速度,达到性能要求。然而如果使用不当,并行处理可能并不会提升处理的速度。这篇博客介绍了Dask中关于并行处理的一些效率方面的建议,尽管是针对Dask的说明,但对于所有的并行处理来说都是适用的。
今日推荐
为什么大语言模型的训练和推理要求比较高的精度,如FP32、FP16?浮点运算的精度概念详解
仅需一行代码即可微调大语言模型——LightningAI发布全新Python库Lit-Parrot
一个基于Python的机器学习项目——各种Kaggle比赛的解决方案
手把手教你本地部署清华大学的ChatGLM-6B模型——Windows+6GB显卡本地部署
人工智能初创企业Hugging Face是什么样的企业——HuggingFace简介
抛弃RLHF?MetaAI发布最新大语言模型训练方法:LIMA——仅使用Prompts-Response来微调大模型
Saleforce发布最新的开源语言-视觉处理深度学习库LAVIS