
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




大模型的进展非常快,但是如何在移动端部署和使用依然是一个非常大的挑战。今天,CerebrasAI联合Opentensor一起开源了一个30亿参数规模的模型BTLM-3B-8K,官方宣称其性能接近70亿参数规模的大模型,但是运行的资源却很低,最低量化版本只需要不到4GB显存即可。

大模型虽然效果很好,但是对资源的消耗却非常高。更麻烦的其实不是训练过程慢,而是峰值内存(显存)的消耗直接决定了我们的硬件是否可以来针对大模型进行训练。最近LightningAI官方总结了使用Fabric降低大模型训练内存的方法。但是,它也适用于其它场景。因此,本文总结一下相关的方法。
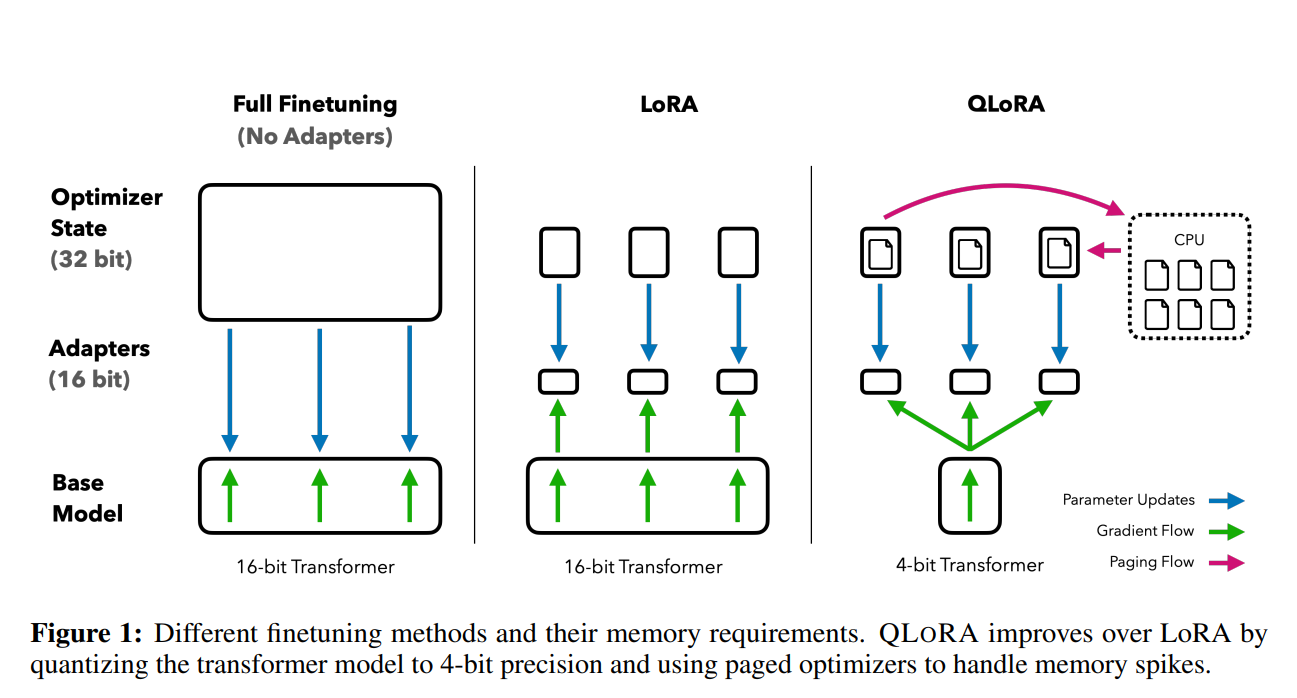
前段时间,康奈尔大学开源了LLMTune框架(https://www.datalearner.com/blog/1051684078977779 ),这是一个可以在48G显存的显卡上微调650亿参数的LLaMA模型的框架,不过它们采用的方法是将650亿参数的LLaMA模型进行4bit量化之后进行微调的。今天华盛顿大学的NLP小组则提出了QLoRA方法,依然是支持在48G显存的显卡上微调650亿参数的LLaMA模型,不过根据论文的描述,基于QLoRA方法微调的模型结果性能基本没有损失!
今日推荐
Gamma函数(伽玛函数)的一阶导数、二阶导数公式推导及java程序
回归模型中的交互项简介(Interactions in Regression)
如何提高大语言模型作为Agent的能力?清华大学与智谱AI推出AgentTuning方案
AI Agent进展再进一步!Anthropic发布大模型上下文连接访问协议MCP:让任何资源快速变成大模型的工具,突破大模型的能力边界!
OpenAI官方教程:如何针对大模型微调以及微调后模型出现的常见问题分析和解决思路~以GPT-3.5微调为例
最像OpenAI的企业Anthropic的重大产品更新:GPT-4最强竞争模型Claude2发布!免费!具有更强的代码能力与更长的上下文!
当前业界最优秀的8个编程大模型简介:从最早的DeepMind的AlphaCode到最新的StarCoder全解析~