
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



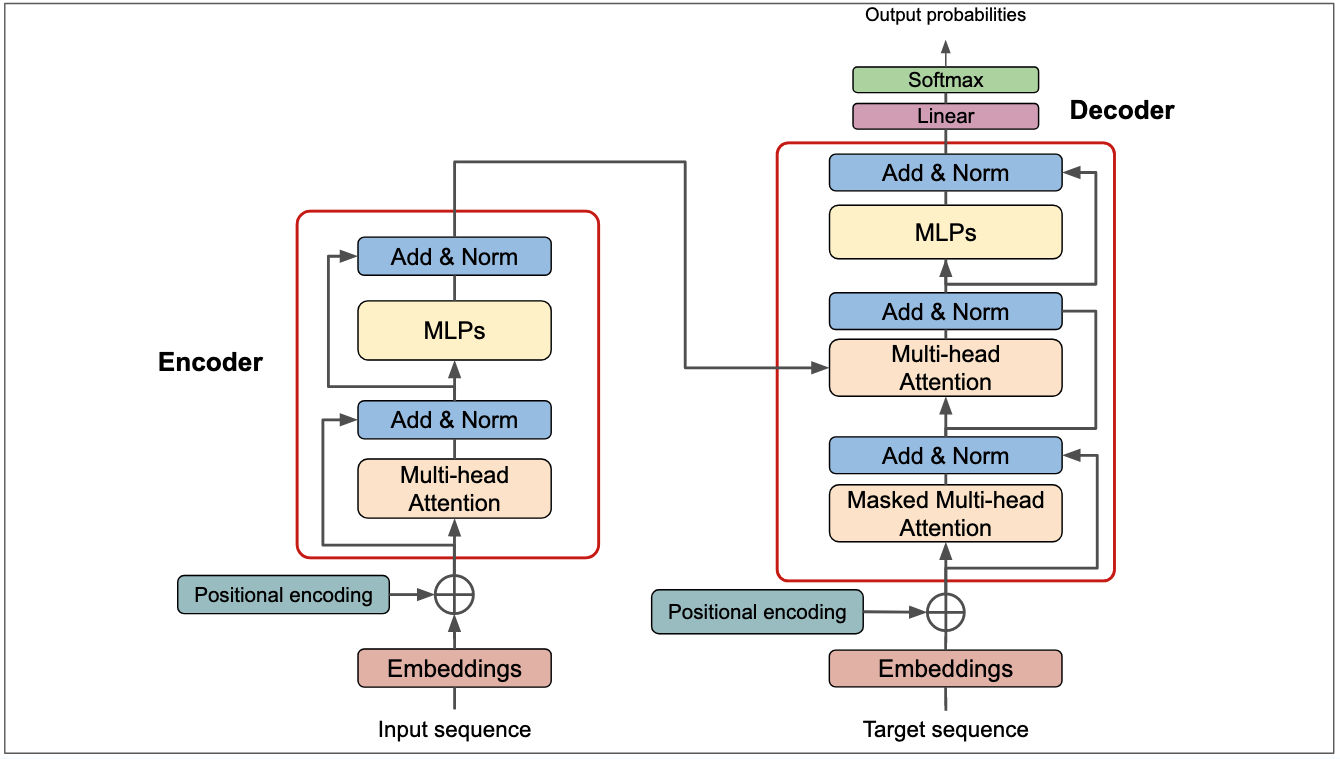
CMU的工程人工智能硕士学位的研究生Jean de Nyandwi近期发表了一篇博客,详细介绍了当前大语言模型主流架构Transformer的历史发展和当前现状。这篇博客非常长,超过了1万字,20多个图,涵盖了Transformer之前的架构和发展。此外,这篇长篇介绍里面的公式内容并不多,所以对于害怕数学的童鞋来说也是十分不错。本文是其翻译版本,欢迎大家仔细学习。

Batch Normalization(BN)是深度学习领域最重要的技巧之一,最早由Google的研究人员提出。这个技术可以大大提高深度学习网络的收敛速度。简单来说,BN就是将每一层网络进行归一化,就可以提高整个网络的训练速度,并打乱训练数据,提升精度。但是,BN的使用可以在很多地方,很多人最大的困惑是放在激活函数之前还是激活函数之后使用,著名机器学习领域的博主Santiago总结了这部分需要注意的内容。
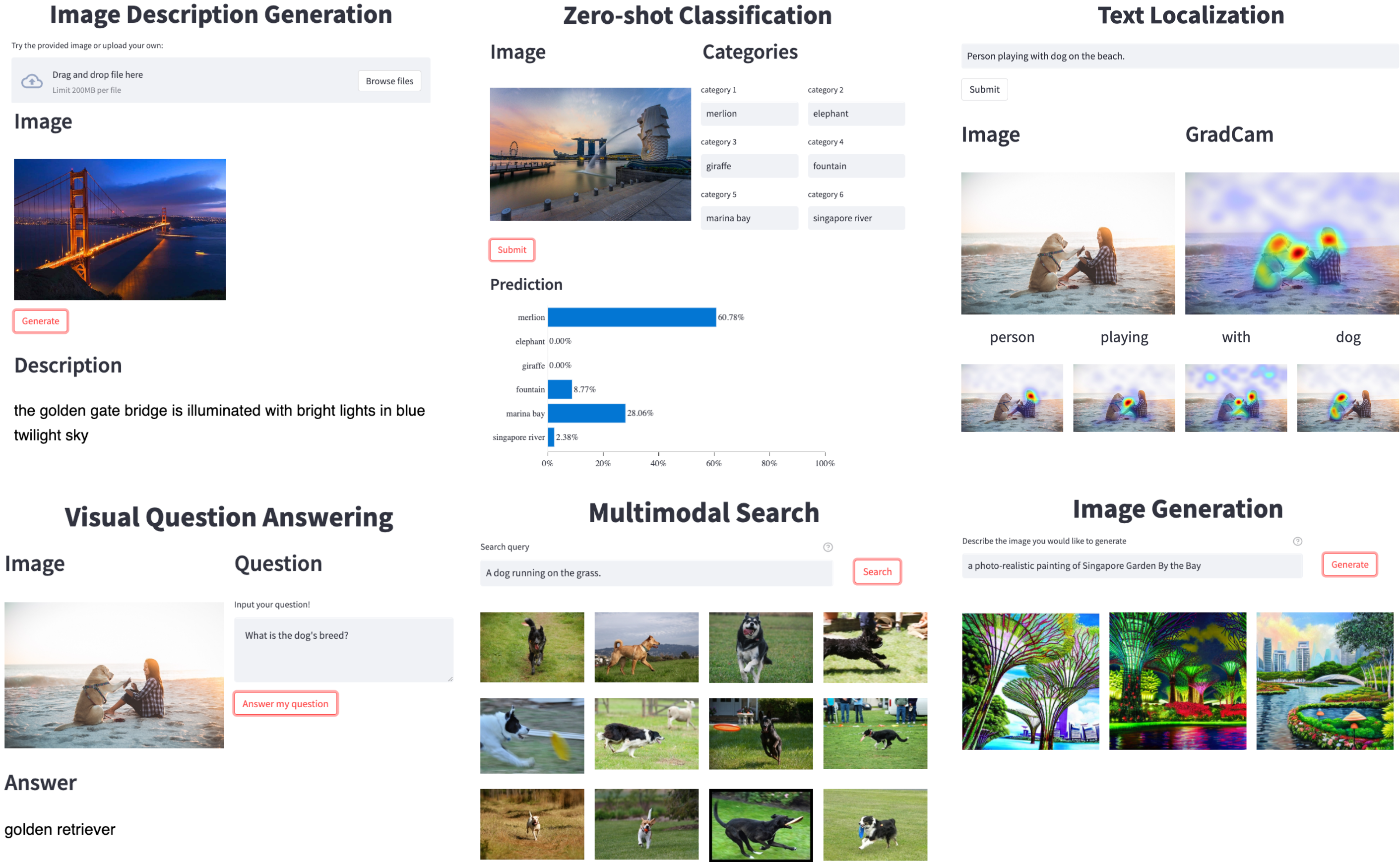
Salesforce的研究人员开发了LAVIS(LAnguage-VISION的缩写),这是一个开源的库,用于在丰富的常见任务和数据集系列上训练和评估最先进的语言-视觉模型,并用于在定制的语言-视觉数据上进行现成的推理。

Stable Diffusion是最近很火的Text-to-Image预训练模型(详细信息:https://www.datalearner.com/ai-resources/pretrained-models/stable-diffusion )。而现在,相关的视频教程已经出现。fast.ai的团队宣布了一门新的深度学习课程《From Deep Learning Foundations to Stable Diffusion》上线!

重磅福利,斯坦福大学在去年秋季开设了应该是全球第一个transformers相关的课程,授课人员来自OpenAI、Google Brain、Facebook人工智能实验室、DeepMind甚至是牛津大学的业界与学术界的一线大牛。而这两天,这门课相关视频也都公开了,大家可以去观看学习了!
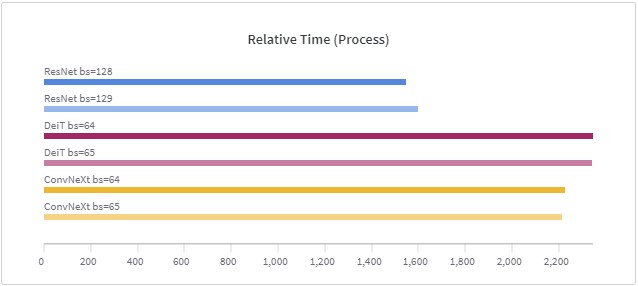
在深度学习训练中,由于数据太大,现在的训练一般是按照一个批次的数据进行训练。批次大小(batch size)的设置在很多论文或者教程中都提示要设置为$2^n$,例如16、32等,这样可能会在现有的硬件中获得更好的性能。但是,目前似乎没有人进行过实际的测试,例如32的batch size与33的batch size性能到底有多大差别?德国的Thomas Bierhance做了一系列实验,以验证批次大小设置为2的幂次方是不是真的可以加速。

指标(metrics)和损失函数(loss function)在深度学习和机器学习里面非常常见,很多时候他们的公式都似乎是一样的,在编写程序的时候,二者的区别好像也不是很大。那为什么还会有这两种不同的概念出现呢?本文将简单介绍一下二者的区别和应用。


就在儿童节前一天,Hugging Face发布了一个最新的深度学习模型评估库Evaluate。对于机器学习模型而言,评估是最重要的一个方面。但是Hugging Face认为当前模型评估方面非常分散且没有很好的文档。导致评估十分困难。因此,Hugging Face发布了这样一个Python的库,用以简化大家评估的步骤与时间。
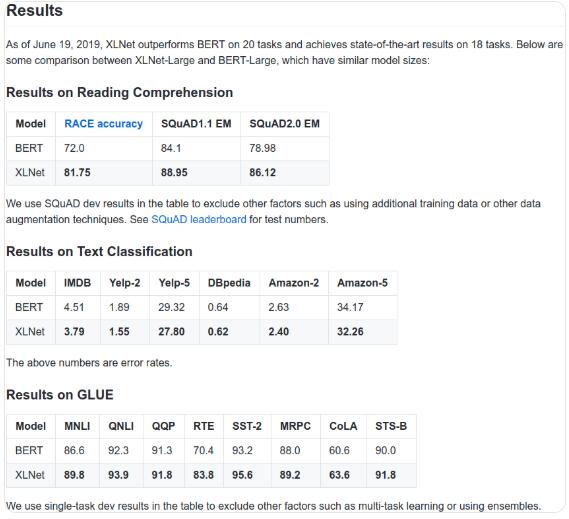
前几天刚刚发布的XLNet彻底火了,原因是它在20多项任务中超越了BERT。这是一个非常让人惊讶的结果。之前我们也说过,在斯坦福问答系统中,XLNet也取得了目前单模型第一的成绩(总排名第四,前三个模型都是集成模型)。

关注深度学习或者NLP的童鞋应该都知道openAI的GPT-3模型,这是一个非常厉害的模型,在很多任务上都取得了极其出色的成绩。然而,OpenAI的有限开放政策让这个模型的应用被限定在很窄的范围内。甚至由于大陆不在OpenAI的API开放国家,大家几乎都无法使用和体验。而五一假期期间,FaceBook的研究人员Susan Zhang等人发布了一个开源的大预言模型,其参数规模1750亿,与GPT-3几乎一样。

Google旗下自动驾驶公司Waymo的研究人员Mingxing Tan发现了一个可以替代Cross-Entropy Loss的新的损失函数:PolyLoss,这是发表在ICLR 22的一篇新论文。什么都不变的情况下,只需要将损失函数的代码替换成PolyLoss,那么模型在图像分类、图像检测等任务的性能就会有很好的提升!
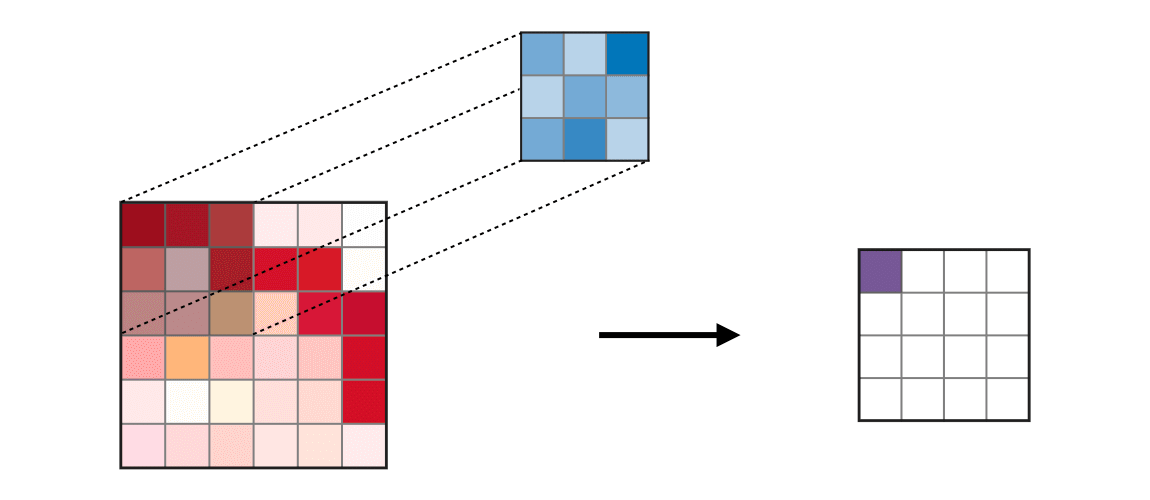
CS 230 ― Deep Learning是斯坦福大学视觉实验室(Stanford Vision Lab)的Shervine Amidi老师开设的深度学习课程,他在课程网站上挂了一个关于深度学习示意图的网站,这里面包含了各种深度学习相关概念的示意图和动图,十分简单明了。

Batch Normalization(BN)是一种深度学习的layer(层)。它可以帮助神经网络模型加速训练,并同时使得模型变得更加稳定。尽管BN的效果很好,但是它的原理却依然没有十分清晰。本文总结一些相关的讨论,来帮助我们理解BN背后的原理。
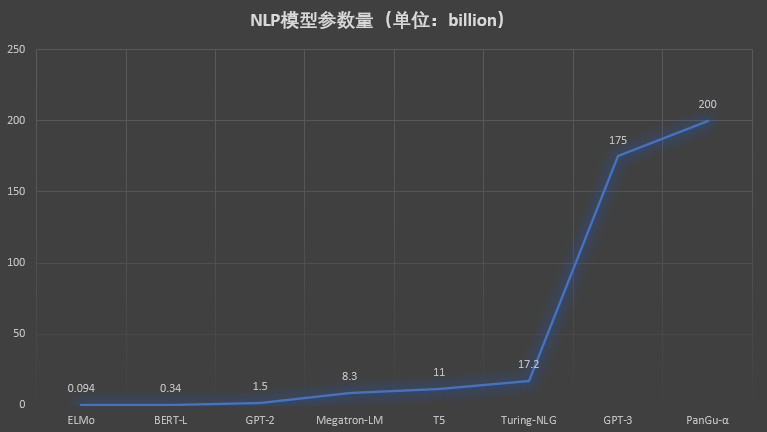
这几年深度学习的发展给人工智能相关应用的落地带来了很大的促进。随着NLP、CV相关领域的算法的发展,算法层面的创新已经逐渐慢了下来,但是工程方面的研究依然非常火热。从底层的硬件的创新,到平台框架的发展,为支撑超大规模模型训练与移动端小规模算法推断而创造的软硬件体系也在飞速革新。本文将总结深度学习平台框架软件及下层的硬件支撑系统。