
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



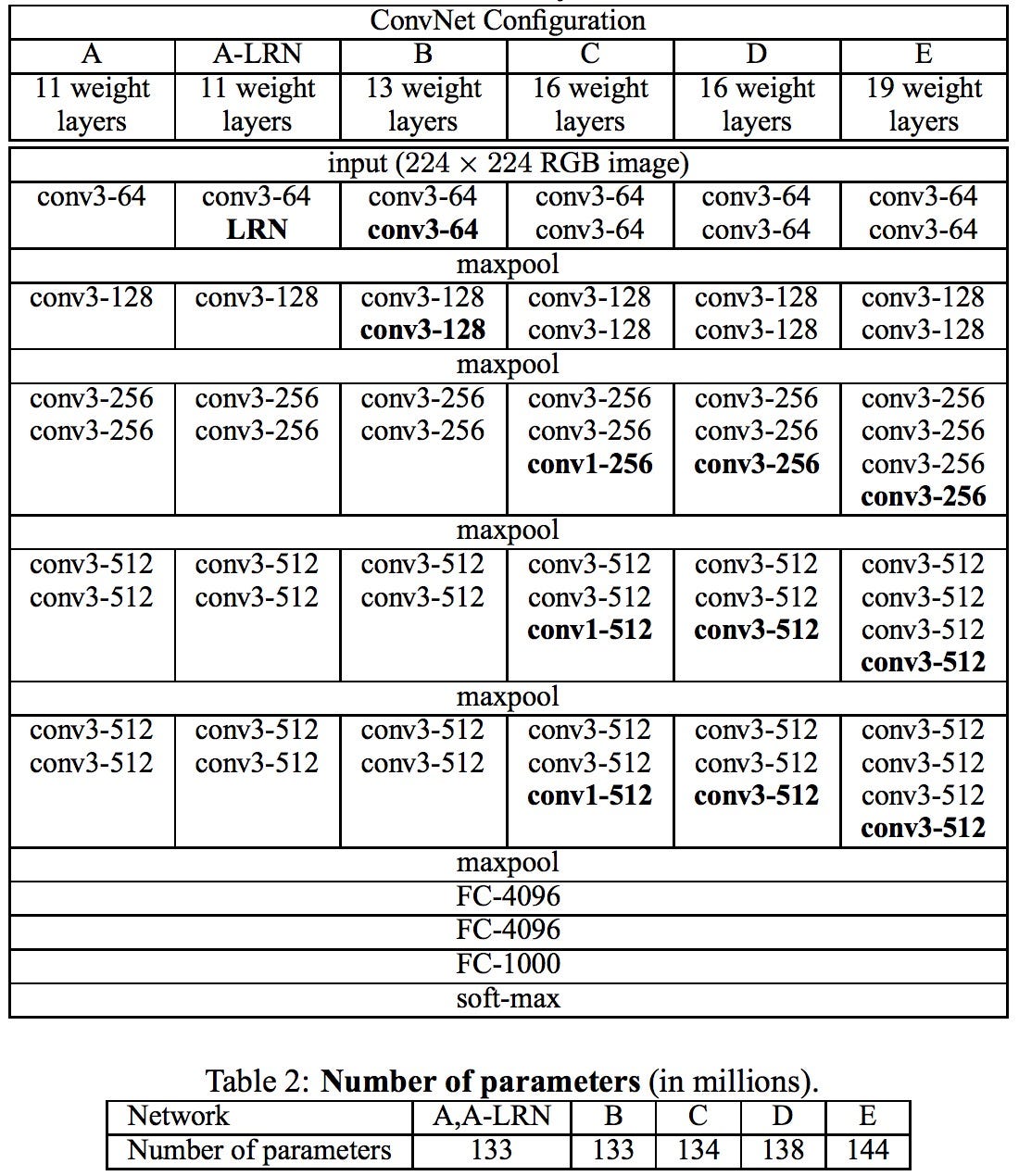
VGGNet(Visual Geometry Group)是2014年又一个经典的卷积神经网络。VGGNet最主要的目标是试图回答“如何设计网络结构”的问题。随着AlexNet提出,很多人开始利用卷积神经网络来解决图像识别的问题。一般的做法都是重复几层卷积网络,每个卷积网络之后接一些池化层,最后再加上几个全连接层。而VGGNet的提出,给这些结构设计带来了一些标准参考。
1998年,LeCun提出了LeNet-5网络用来解决手写识别的问题。LeNet-5被誉为是卷积神经网络的“Hello Word”,足以见到这篇论文的重要性。在此之前,LeCun最早在1989年提出了LeNet-1,并在接下来的几年中继续探索,陆续提出了LeNet-4、Boosted LeNet-4等。本篇博客将详解LeCun的这篇论文,并不是完全翻译,而是总结每一部分的精华内容。
之前面的博客中,我们已经描述了基本的RNN模型。但是基本的RNN模型有一些缺点难以克服。其中梯度消失问题(Vanishing Gradients)最难以解决。为了解决这个问题,GRU(Gated Recurrent Unit)神经网络应运而生。本篇博客将描述GRU神经网络的工作原理。GRU主要思想来自下面两篇论文:
在前面的博客中,我们已经介绍了基本的RNN模型和GRU深度学习网络,在这篇博客中,我们将介绍LSTM模型,LSTM全称是Long Short-Time Memory,也是RNN模型的一种。

使用预训练模型处理NLP任务是目前深度学习中一个非常火热的领域。本文总结了8个顶级的预训练模型,并提供了每个模型相关的资源(包括官方文档、Github代码和别人已经基于这些模型预训练好的模型等)。
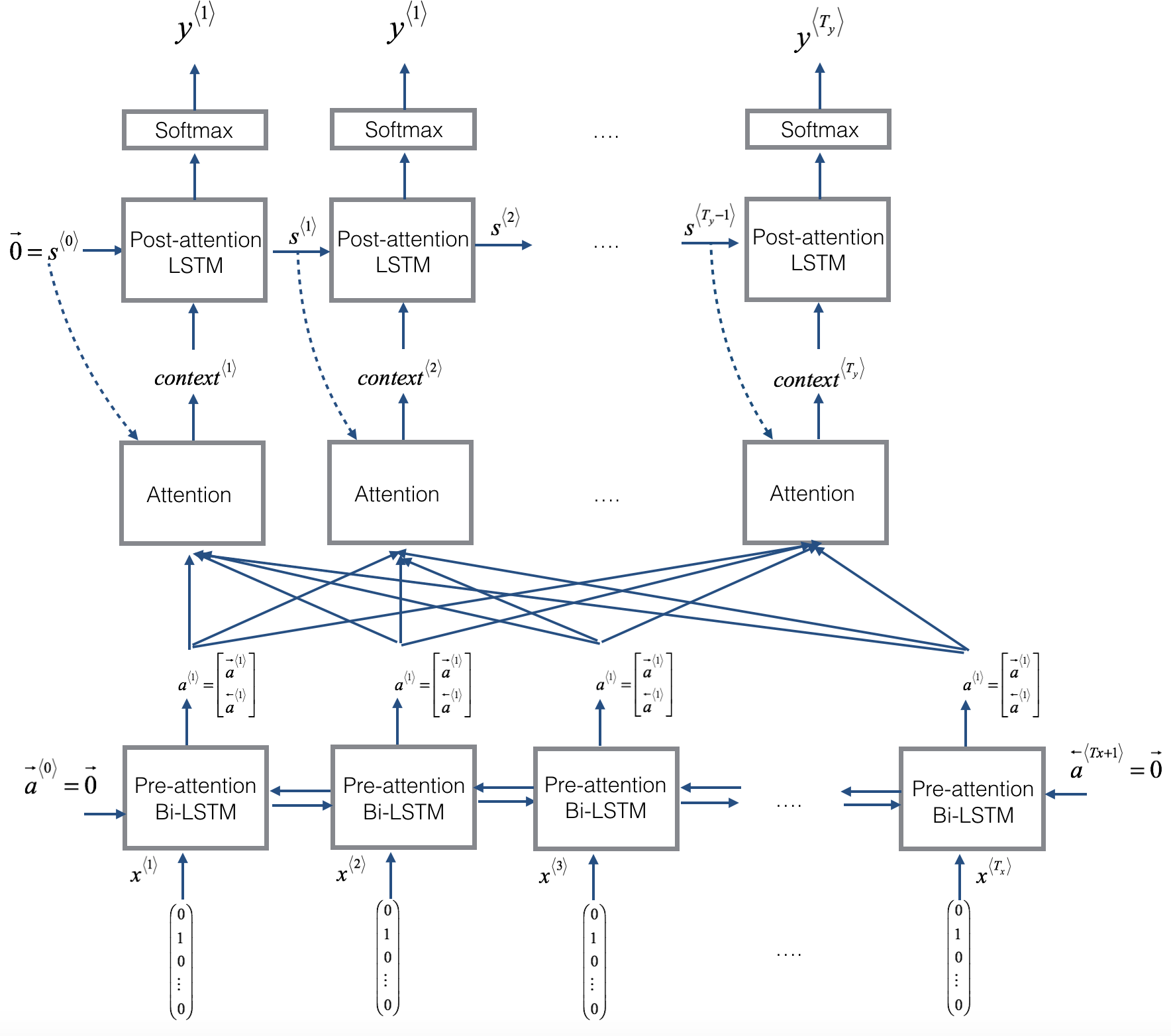
Encoder-Decoder的深度学习架构是目前非常流行的神经网络架构,在许多的任务上都取得了很好的成绩。在之前的博客中,我们也详细介绍了该架构(参见深度学习之Encoder-Decoder架构)。本篇博客将详细讲述Attention机制。

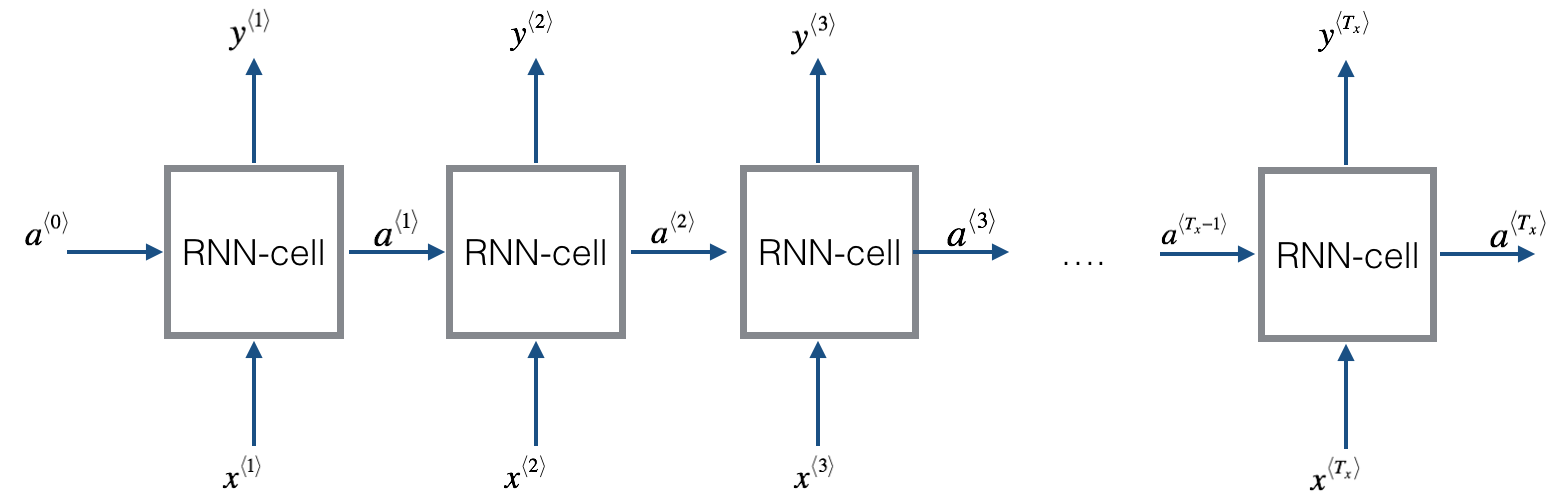
深度学习中Sequence to Sequence (Seq2Seq) 模型的目标是将一个序列转换成另一个序列。包括机器翻译(machine translate)、会话识别(speech recognition)和时间序列预测(time series forcasting)等任务都可以理解成是Seq2Seq任务。RNN(Recurrent Neural Networks)是深度学习中最基本的序列模型。
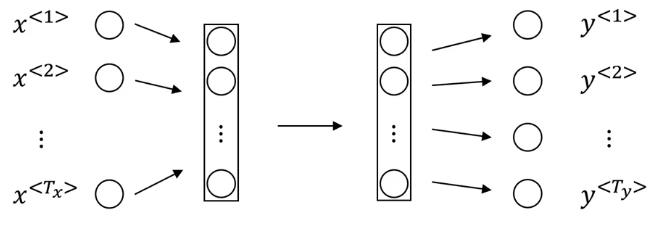
序列数据是生活中很常见的一种数据,如一句话、一段时间某个广告位的流量、一连串运动视频的截图等。在这些数据中也有着很多数据挖掘的需求。RNN就是解决这类问题的一种深度学习方法。其全称是Recurrent Neural Networks,中文是递归神经网络。主要解决序列数据的数据挖掘问题。
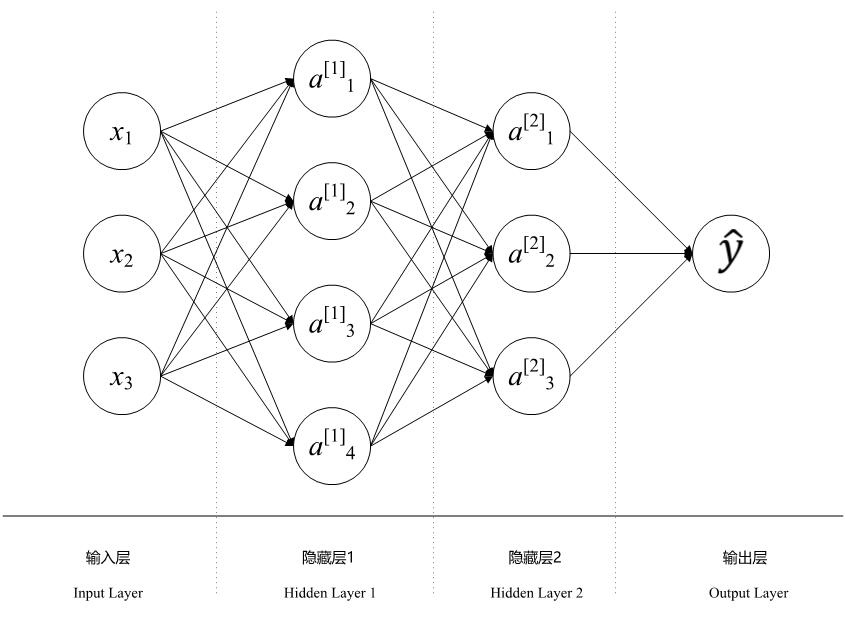
深度学习中的符号很多,但是大多数情况下,大家都使用同一套符号来表示。这篇博客主要以一个简单的神经网络为例,说明深度学习的标准符号以及相关的维度表示。主要来源是吴恩达的coursera课程。


当我们训练深度学习神经网络的时候通常希望能获得最好的泛化性能(generalization performance,即可以很好地拟合数据)。但是所有的标准深度学习神经网络结构如全连接多层感知机都很容易过拟合:当网络在训练集上表现越来越好,错误率越来越低的时候,实际上在某一刻,它在测试集的表现已经开始变差。早停法就是一种防止深度学习网络模型过拟合的方法。
