
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




随着NLP预训练模型的发展,大语言模型在各个领域的作用也越来越大。几个月前,GitHub基于OpenAI的GPT-3训练的Copilot效果十分惊艳,可惜现在已经开始收费。而最近,清华大学也发布了一个代码补全神器——CodeGeeX。
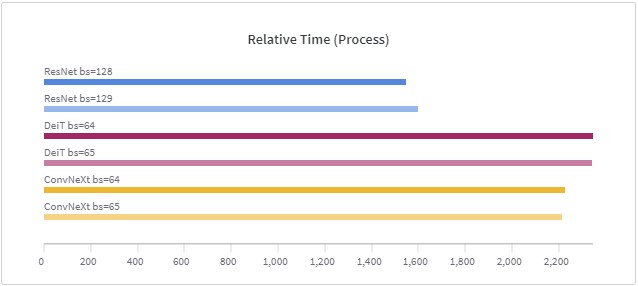
在深度学习训练中,由于数据太大,现在的训练一般是按照一个批次的数据进行训练。批次大小(batch size)的设置在很多论文或者教程中都提示要设置为$2^n$,例如16、32等,这样可能会在现有的硬件中获得更好的性能。但是,目前似乎没有人进行过实际的测试,例如32的batch size与33的batch size性能到底有多大差别?德国的Thomas Bierhance做了一系列实验,以验证批次大小设置为2的幂次方是不是真的可以加速。

前几天初创AI企业Nebuly开源了一个AI加速库nebulgym,它最大的特点是不更改你现有AI模型的代码,但是可以将训练速度提升2倍。
大规模的text-to-image模型没有公开预训练结果,OpenAI的意思就是我这玩意太厉害,随便放出来可能会被你们做坏事,而谷歌训练这个应该就是为了云服务挣钱,所以都没有公开可用的版本供大家玩耍。虽然业界有基于论文的实现,但是训练模型需要耗费大量的资源,没有开放的预训练结果,我们普通个人也很难玩起来。但是,大神Sahar提供了一个免费使用开源实现的text-to-image预训练模型的方式。
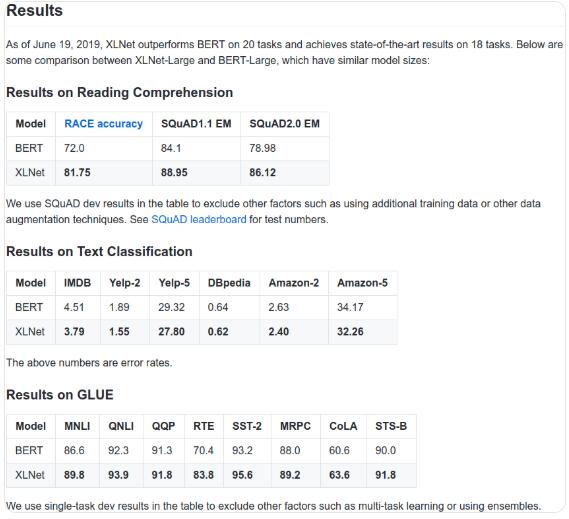
前几天刚刚发布的XLNet彻底火了,原因是它在20多项任务中超越了BERT。这是一个非常让人惊讶的结果。之前我们也说过,在斯坦福问答系统中,XLNet也取得了目前单模型第一的成绩(总排名第四,前三个模型都是集成模型)。
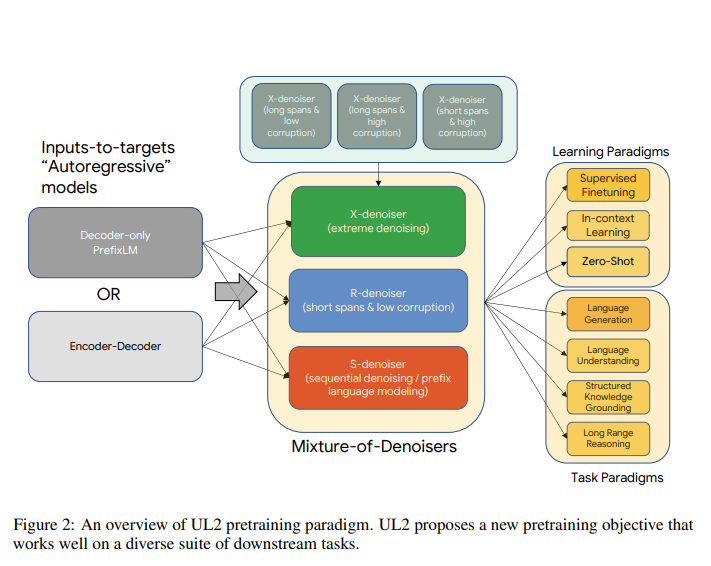
如今,自然语言处理的预训练模型被广泛运用在各个领域。各大企业和组织都在追求各种大型的预训练模型。但是当你问我们应该使用哪一个预训练模型来解决问题的时候,通常没有统一的答案,一般来说它取决于下游的任务,也就是说需要根据任务类型来选择模型。 而谷歌认为这不是一个正确的方向,因此,本周,谷歌提出了一个新的NLP预训练模型框架——Unifying Language Learning Paradigms(简称UL2)来尝试使用一个模型解决多种任务。

使用预训练模型处理NLP任务是目前深度学习中一个非常火热的领域。本文总结了8个顶级的预训练模型,并提供了每个模型相关的资源(包括官方文档、Github代码和别人已经基于这些模型预训练好的模型等)。
