
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




大模型的长输入在很多场景下都有非常重要的应用,如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。昨天,斯坦福大学、加州伯克利大学和Samaya AI的研究人员联合发布的一个论文中有一个非常有意思的发现:当相关信息出现在输入上下文的开始或结束时,大模型的性能通常最高,而当大模型必须访问长上下文中间的相关信息时,性能显著下降。本文将简单介绍一下这个现象。
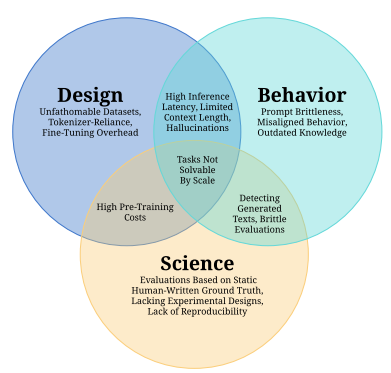
前天,EleutherAI、MetaAI、StabilityAI、伦敦大学等研究人员合作提交了一个关于大语言模型(Large Language Model,LLM)的挑战和应用的论文综述,引用了688篇参考文献总结了当前LLM的主要挑战和应用方向。
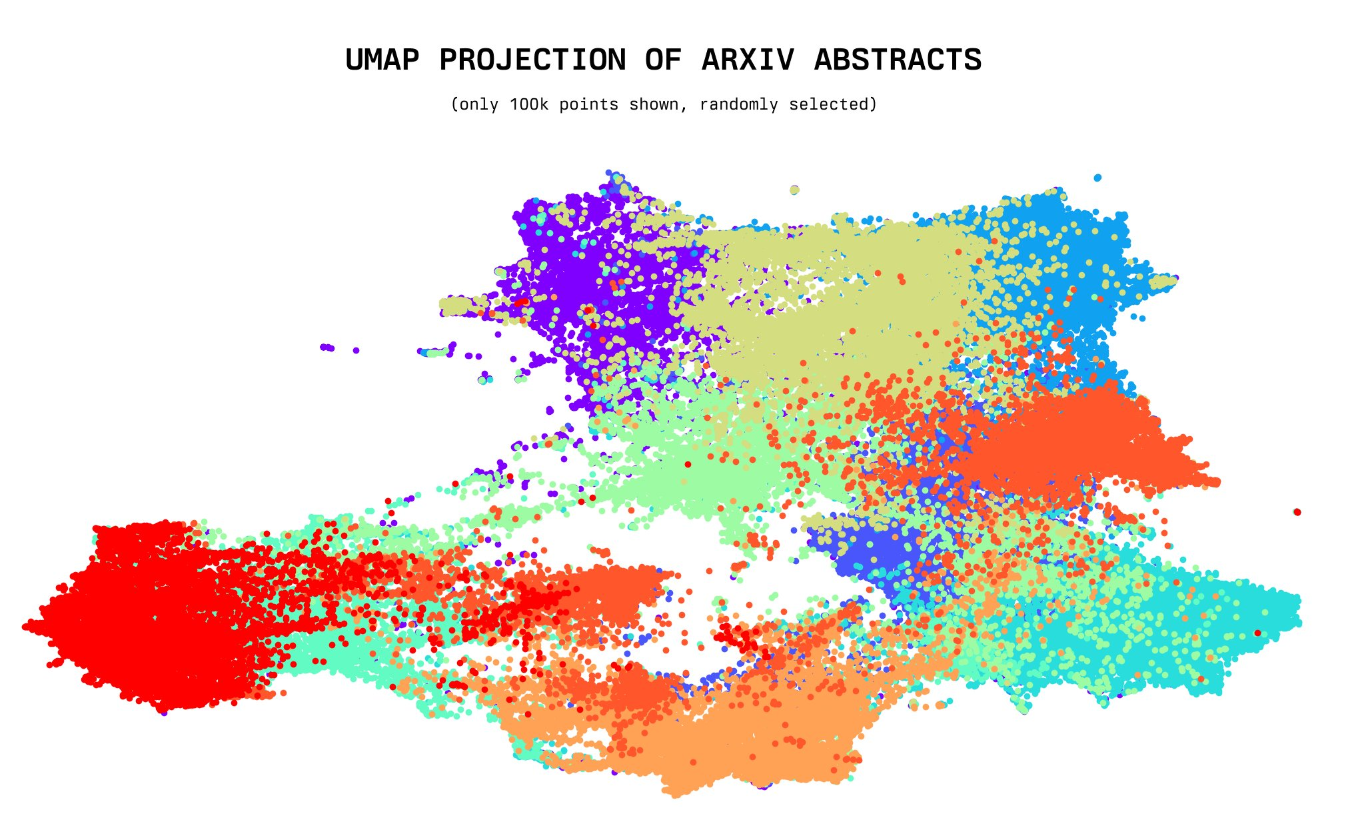
今天,一位年仅20岁的小哥willdepue 开源了230万arXiv论文的标题和摘要的embedding向量数据集,完全开源。该数据集包含截止2023年5月4日的所有arXiv上的论文标题和摘要的embedding结果,使用的是开源的Instructor XL抽取。未来将开放更多其它相关数据的embedding结果
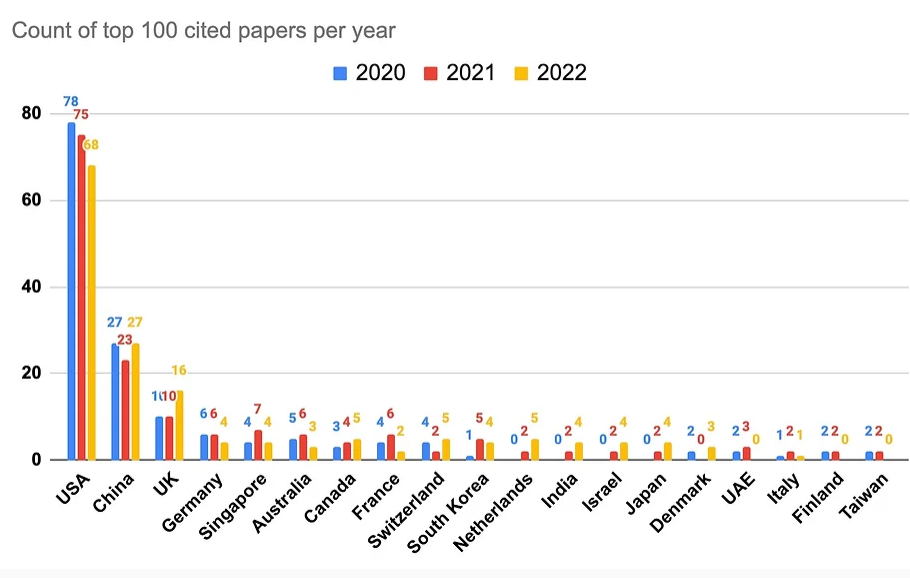
尽管AI领域在工业界发展迅速,企业研究机构在拼命的开发相关的产品以推动各自业务的发展。但是他们也在科研领域不断贡献大量的AI论文。Zeta Alpha的一篇博客分析了2022年发表的被引用最多的100篇AI论文,给大家提供一个洞察思路。

本周,谷歌的研究人员在arXiv上提交了一个非常有意思的论文,其主要目的就是分享了他们建立能够翻译一千多种语言的机器翻译系统的经验和努力。
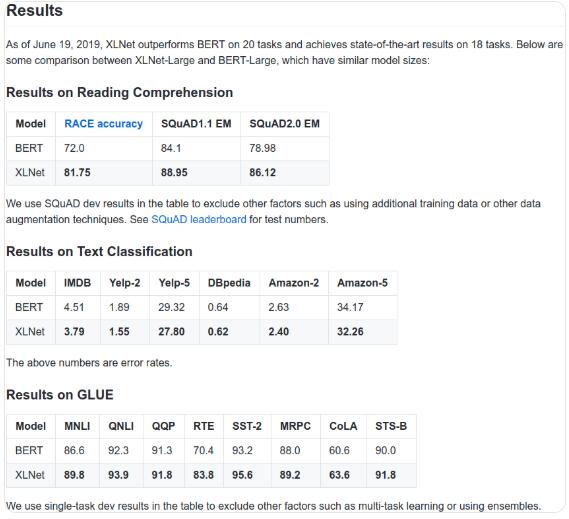
前几天刚刚发布的XLNet彻底火了,原因是它在20多项任务中超越了BERT。这是一个非常让人惊讶的结果。之前我们也说过,在斯坦福问答系统中,XLNet也取得了目前单模型第一的成绩(总排名第四,前三个模型都是集成模型)。
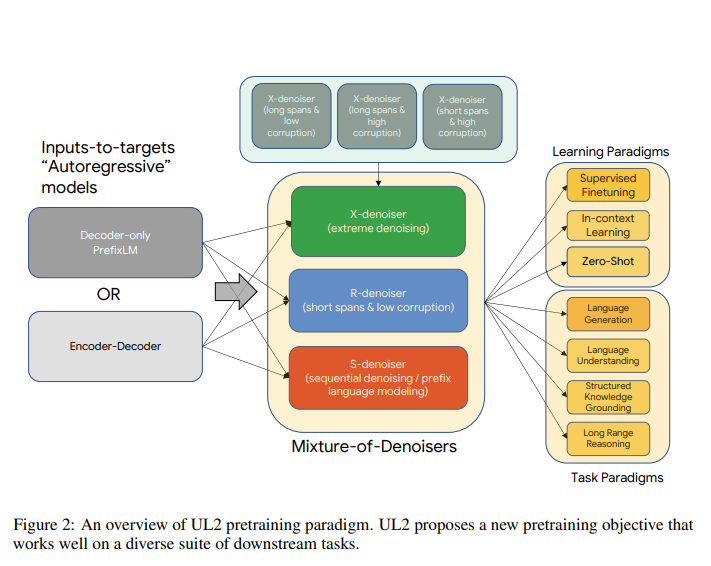
如今,自然语言处理的预训练模型被广泛运用在各个领域。各大企业和组织都在追求各种大型的预训练模型。但是当你问我们应该使用哪一个预训练模型来解决问题的时候,通常没有统一的答案,一般来说它取决于下游的任务,也就是说需要根据任务类型来选择模型。 而谷歌认为这不是一个正确的方向,因此,本周,谷歌提出了一个新的NLP预训练模型框架——Unifying Language Learning Paradigms(简称UL2)来尝试使用一个模型解决多种任务。
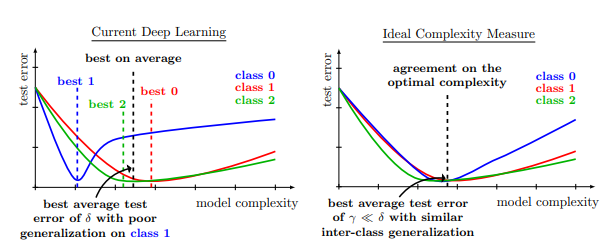
正则化是一种基本技术,通过限制模型的复杂性来防止过度拟合并提高泛化性能。目前的深度网络严重依赖正则化器,如数据增强(DA)或权重衰减,并采用结构风险最小化,即交叉验证,以选择最佳的正则化超参数。然而,正则化和数据增强对模型的影响也不一定总是好的。来自Meta AI研究人员最新的论文发现,正则化是否有效与类别高度相关。
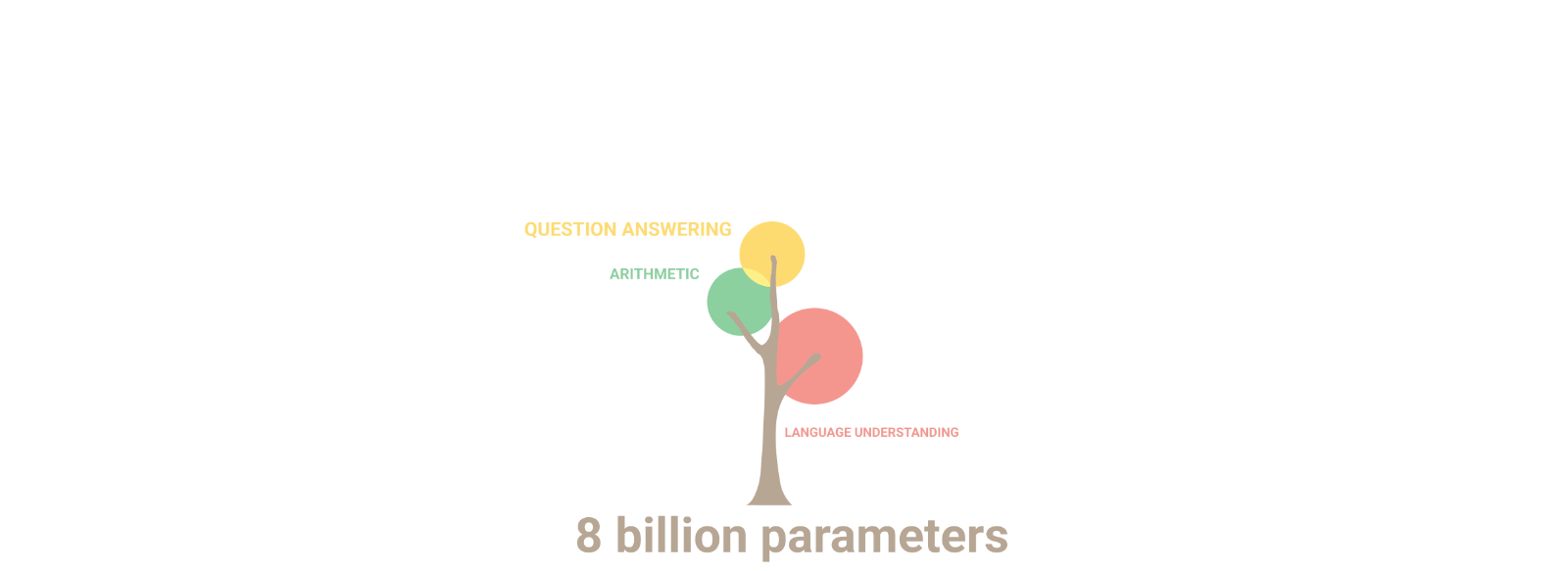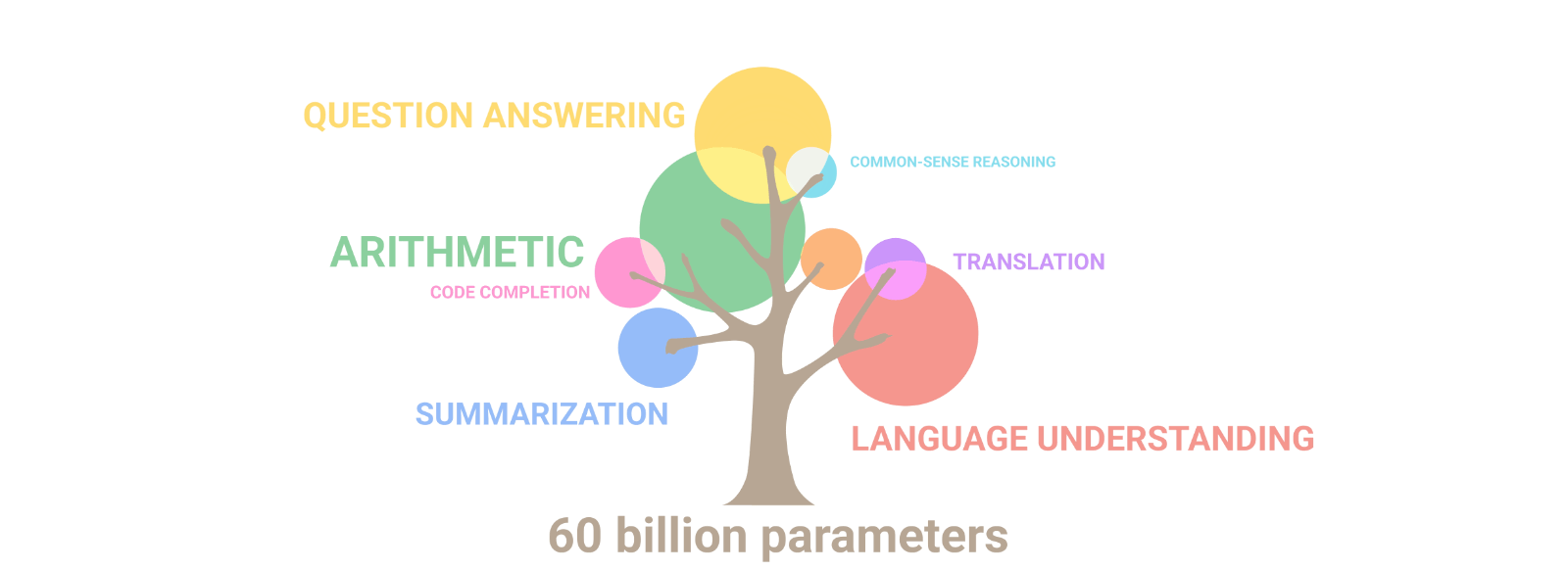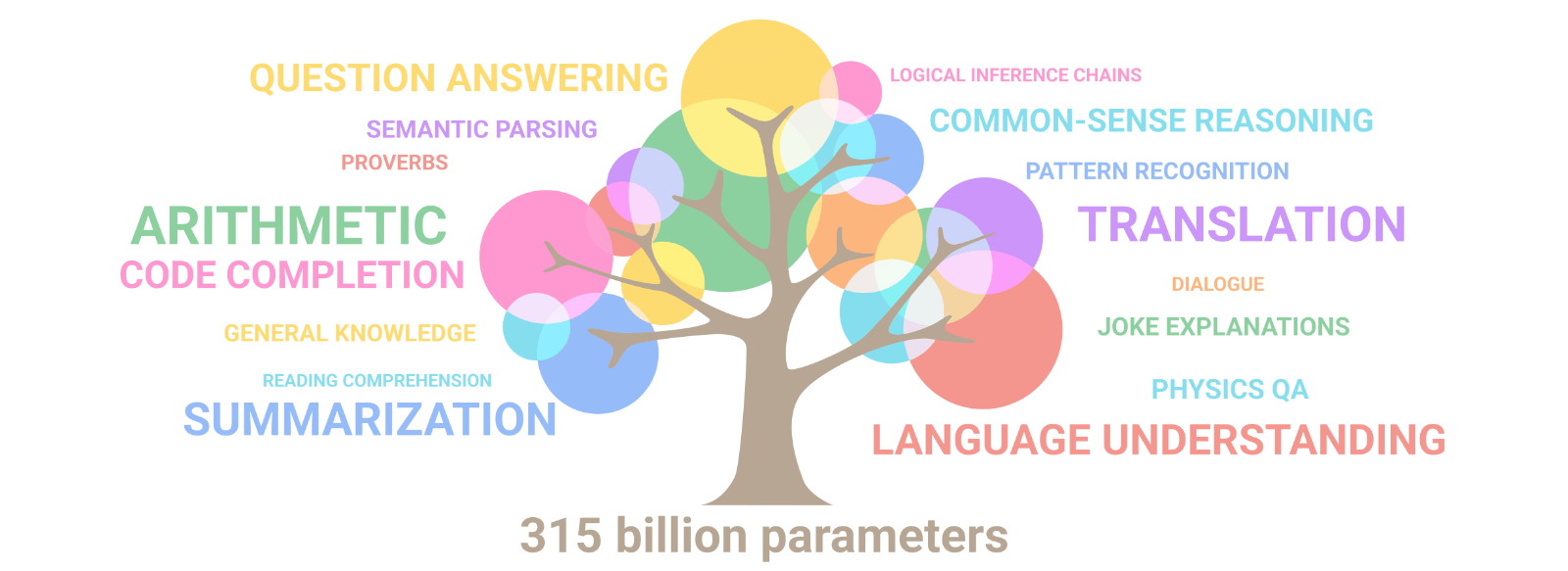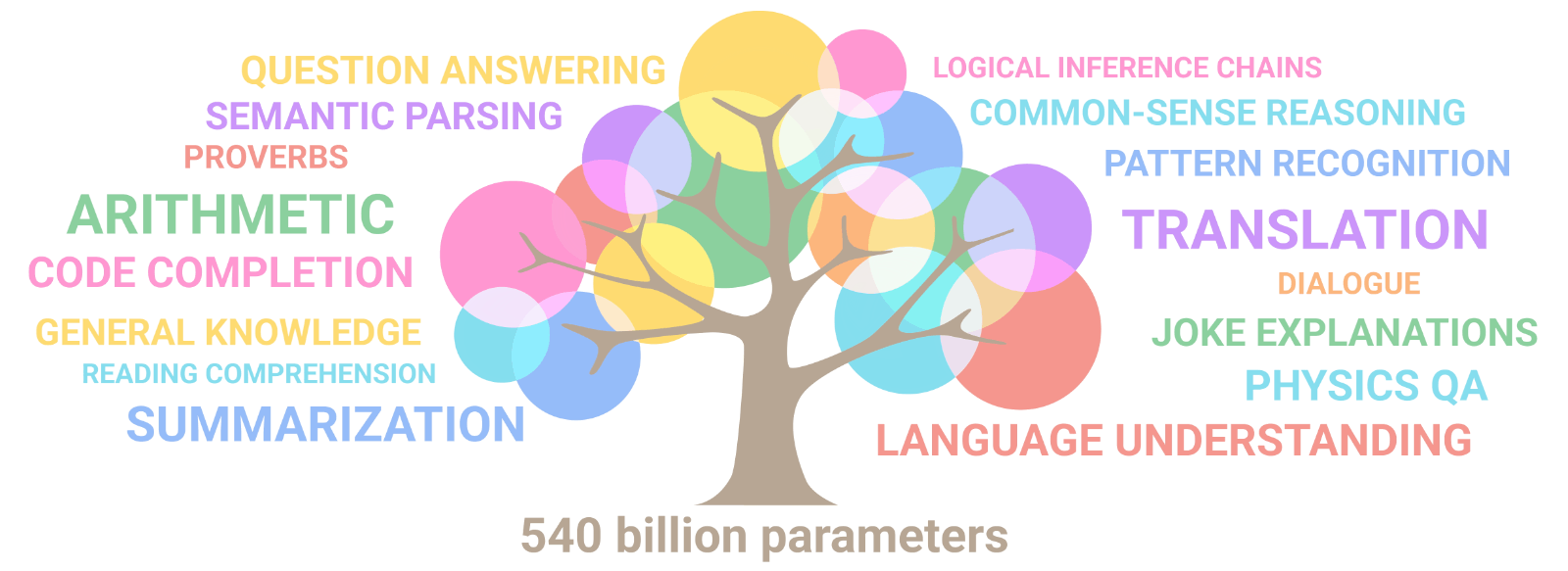
今天,Google介绍了一个新的语言模型,一个Pathways语言模型:PaLM,这是一个用Pathways系统训练的5400亿个参数、仅有dense decoder的Transformer模型,在数百个语言理解和生成任务上对PaLM进行了评估,发现它在大多数任务中实现了最先进的性能,在许多情况下都有显著的优势。
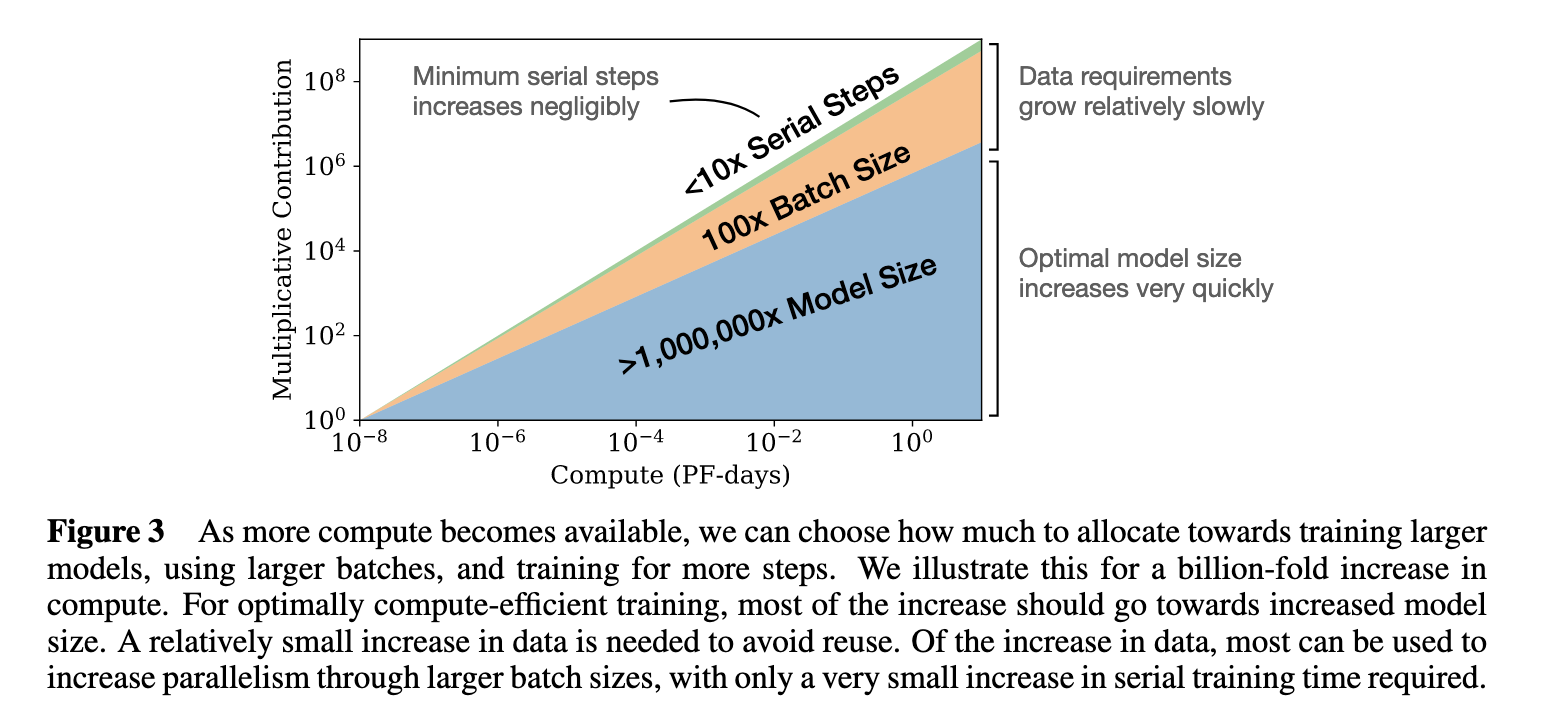
3月29日,DeepMind发表了一篇论文,"Training Compute-Optimal Large Language Models",表明基本上每个人--OpenAI、DeepMind、微软等--都在用极不理想的计算方式训练大型语言模型。论文认为这些模型对计算的使用一直处于非常不理想的状态。并提出了新的模型缩放规律。
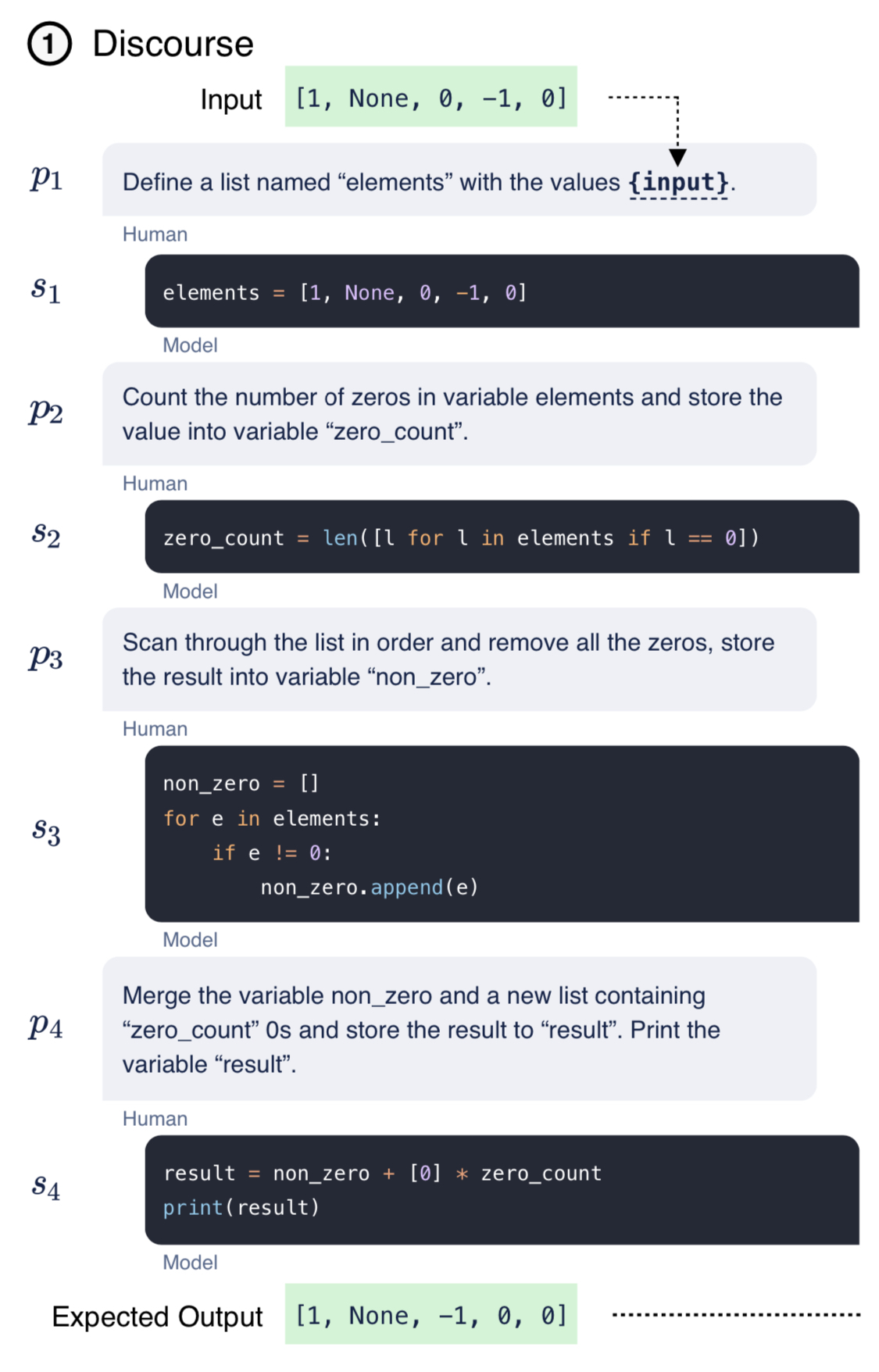
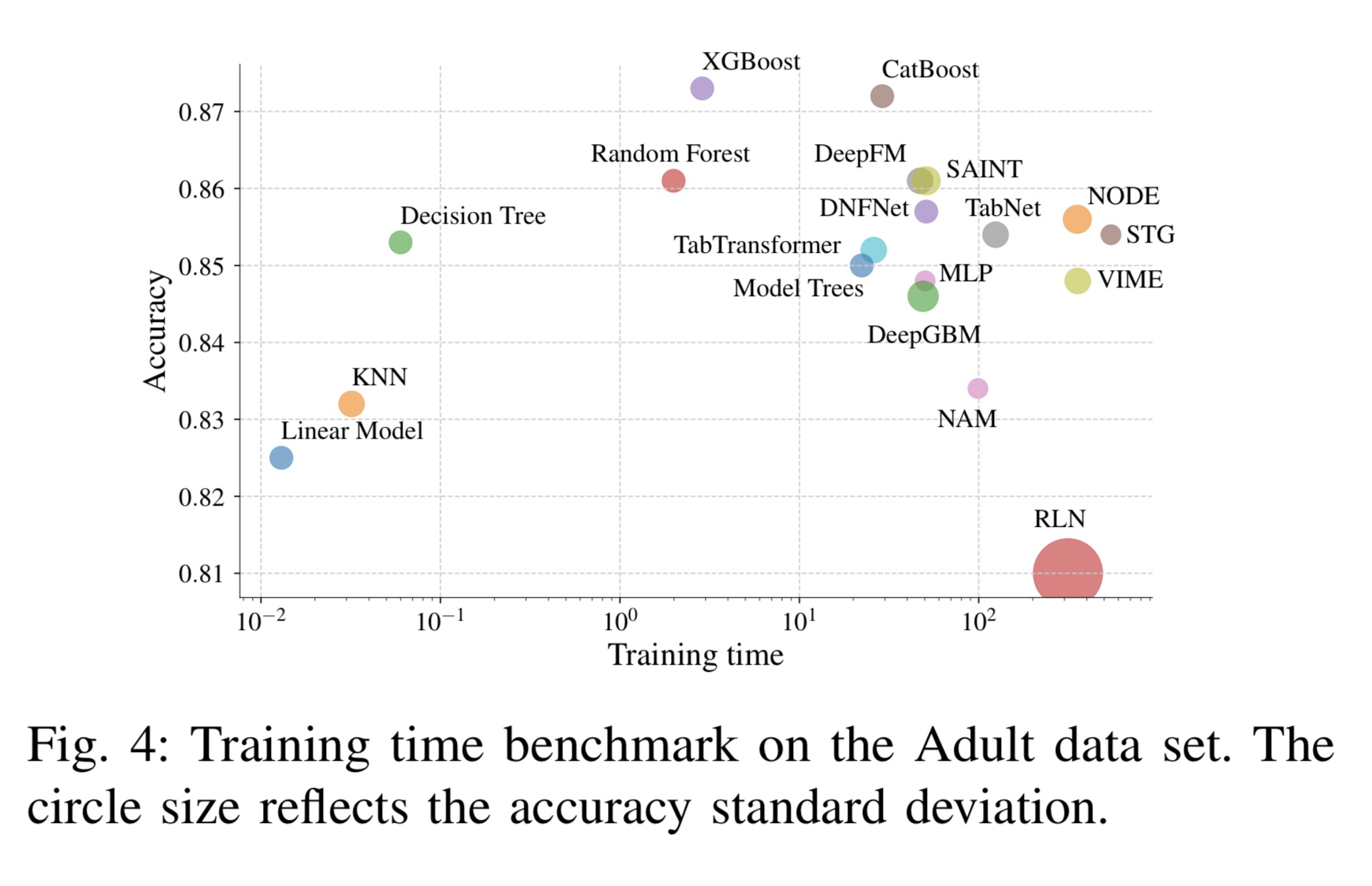
异质表格数据是最常用的数据形式,对于众多关键和计算要求高的应用来说是必不可少的。在同质数据集上,深度神经网络已多次显示出优异的性能,因此被广泛采用。然而,它们在表格数据建模(推理或生成)方面的应用仍然具有高度挑战性。
