
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




最近,随着ChatGPT的火爆,大语言模型(Large language model)再次被大家所关注。当年BERT横空出世的时候,基于BERT做微调风靡全球。但是,最新的大语言模型如ChatGPT都使用强化学习来做微调,而不是用之前大家所知道的有监督的学习。这是为什么呢?著名AI研究员Sebastian Raschka解释了这样一个很重要的转变。大约有5个原因促使了这一转变。

今天,时隔一年后,OpenAI发布了第二代的DALL·E模型。相比较第一代的模型,DALL·E 2,以4倍的分辨率生成更真实和准确的图像。
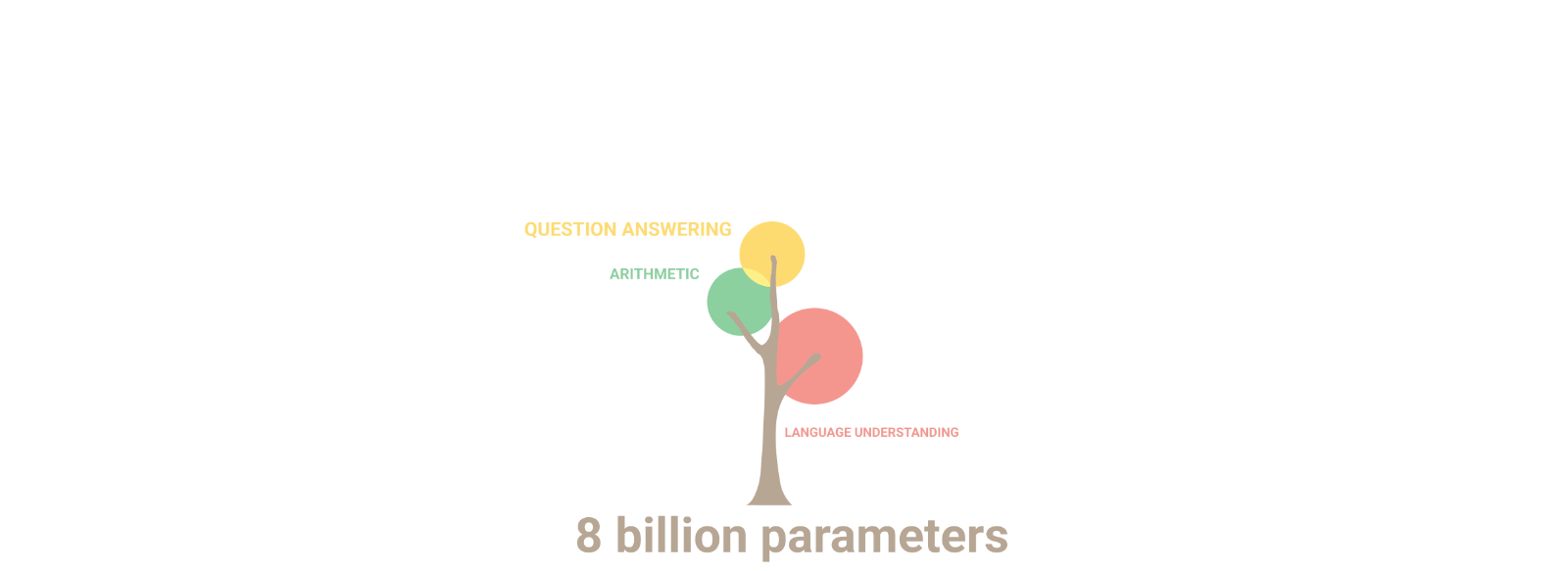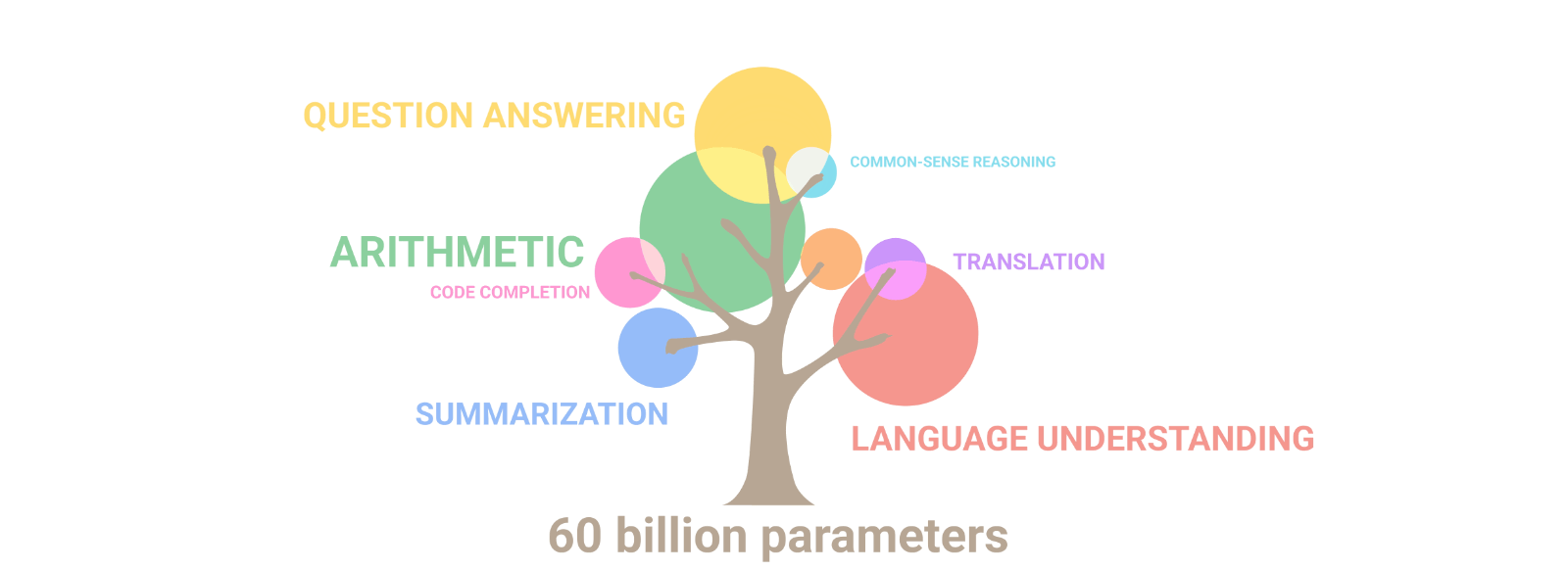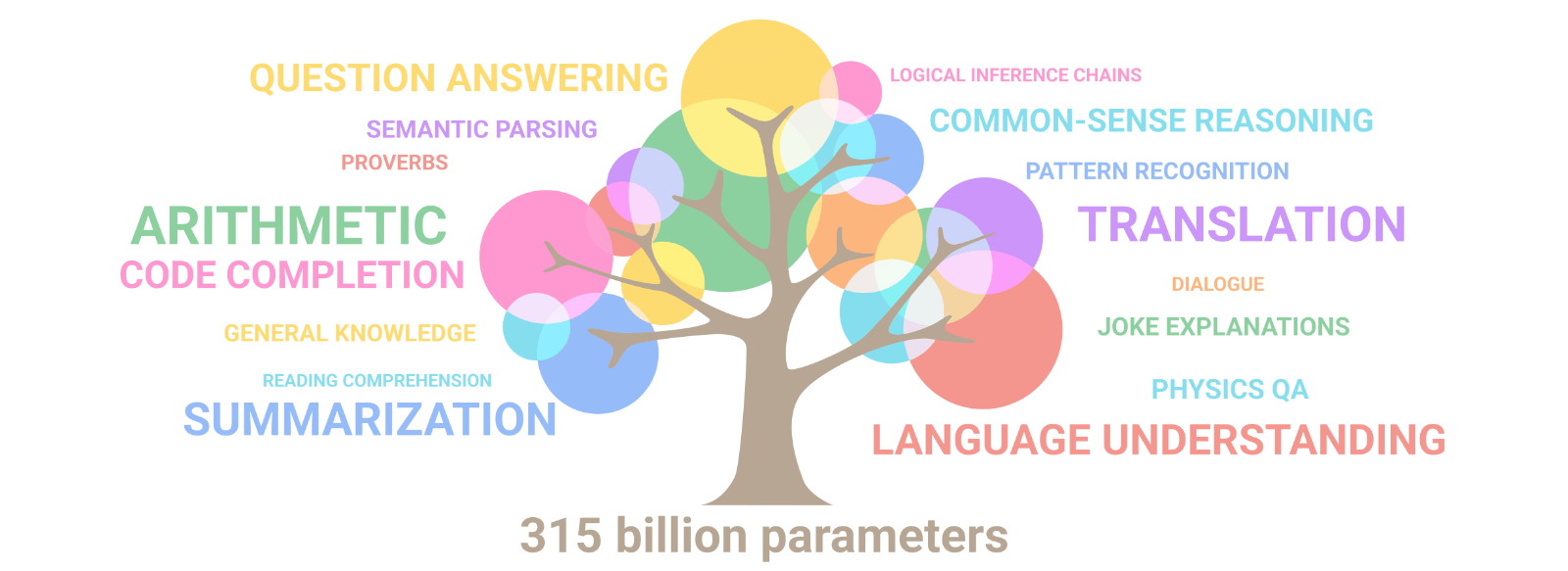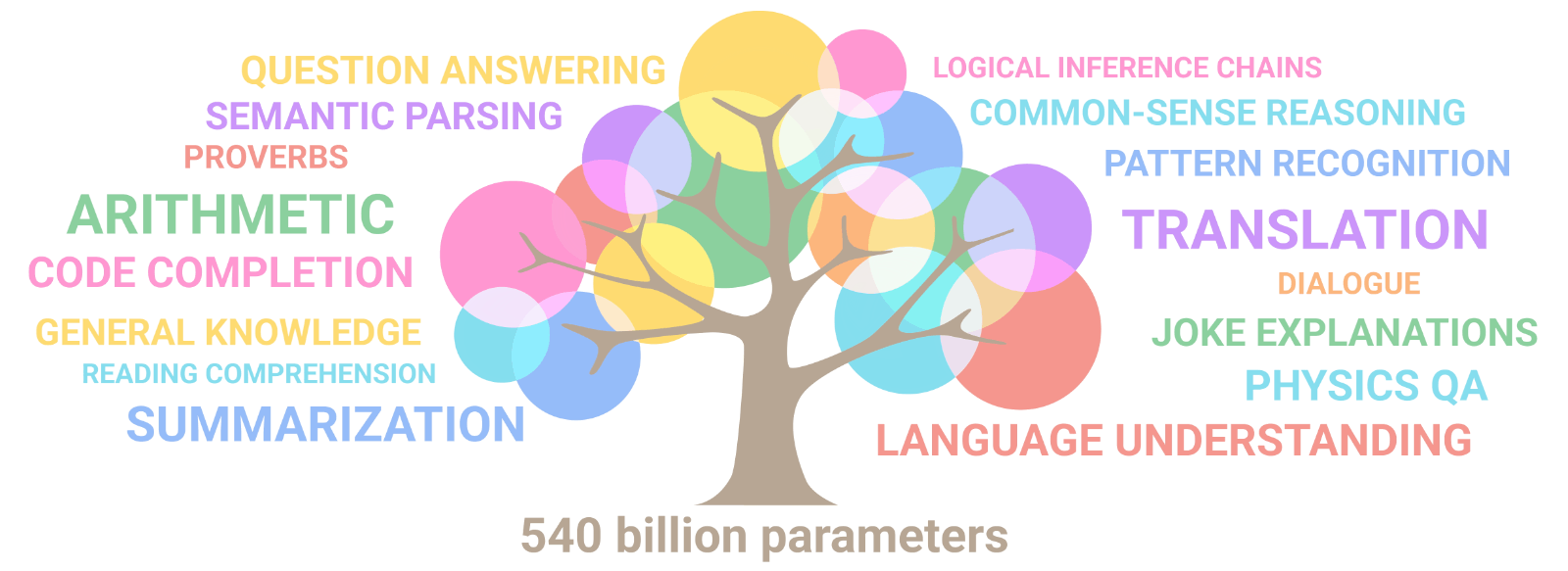
今天,Google介绍了一个新的语言模型,一个Pathways语言模型:PaLM,这是一个用Pathways系统训练的5400亿个参数、仅有dense decoder的Transformer模型,在数百个语言理解和生成任务上对PaLM进行了评估,发现它在大多数任务中实现了最先进的性能,在许多情况下都有显著的优势。
3月29日,DeepMind发表了一篇论文,"Training Compute-Optimal Large Language Models",表明基本上每个人--OpenAI、DeepMind、微软等--都在用极不理想的计算方式训练大型语言模型。论文认为这些模型对计算的使用一直处于非常不理想的状态。并提出了新的模型缩放规律。