
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



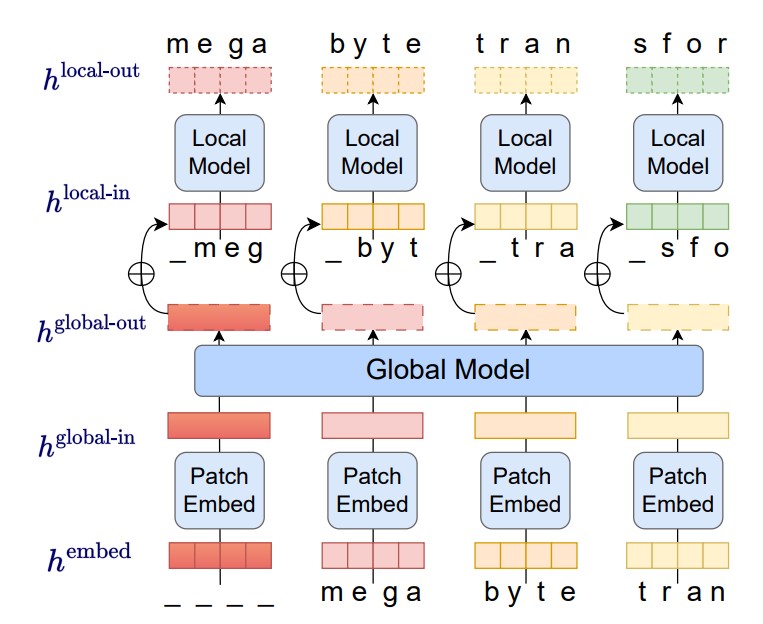
尽管OpenAI的ChatGPT很火爆,但是这类大语言模型有一个非常严重的问题就是对输入的内容长度有着很大的限制。例如,ChatGPT-3.5的输入限制是4096个tokens。MetaAI在前几天提交了一个论文,提出了MegaByte方法,几乎可以让模型接受任意长度的限制!
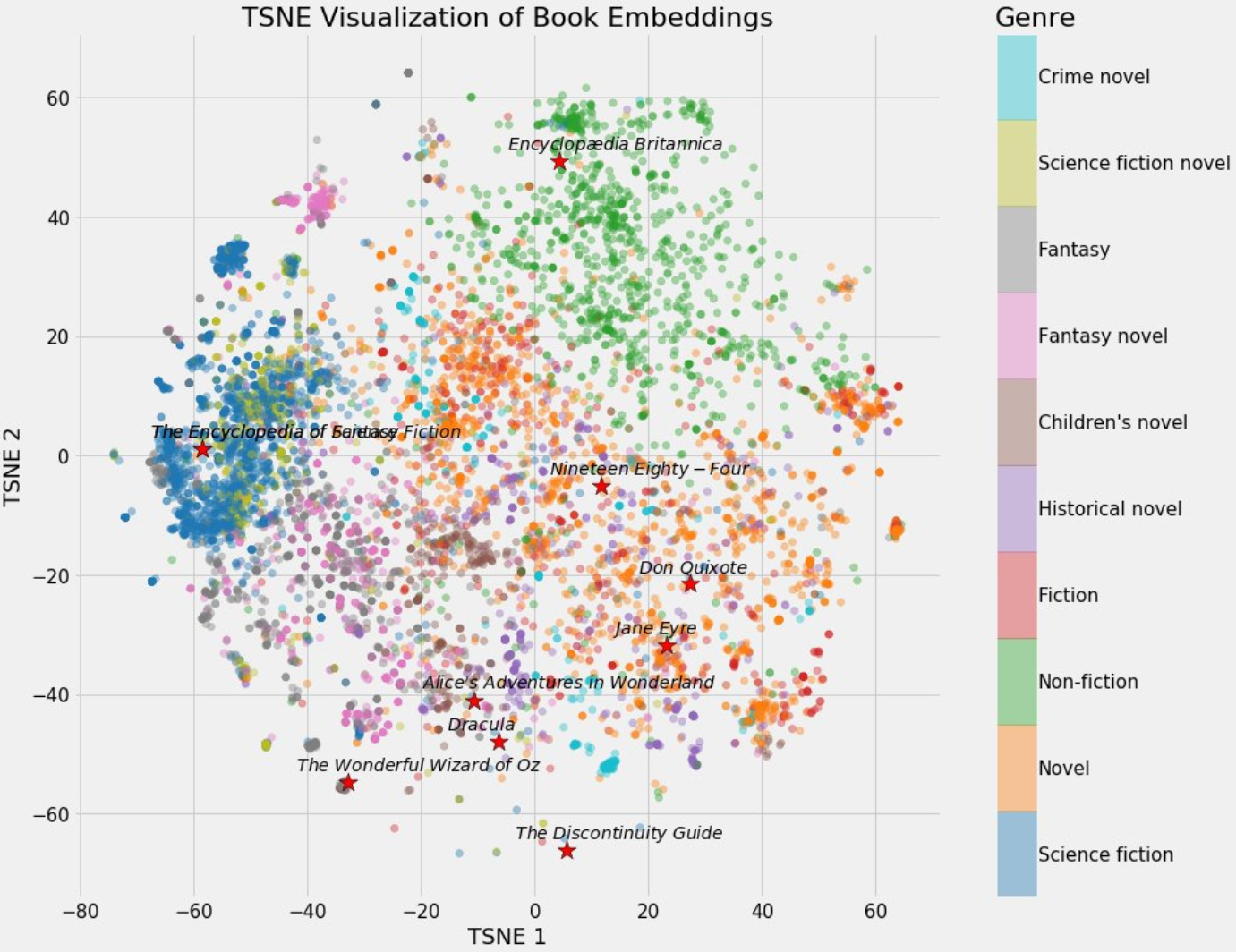
今天,推特上一位科技博主SullyOmarr分享了一个关于embedding的内容十分火爆。主要介绍为什么embedding对于在目前的AI大模型中很重要。这是一个十分不错的关于embedding知识的介绍。本文将根据SullyOmarr的内容也对embedding做一个简单的介绍,并解释为什么它在大语言模型中十分重要。
今日推荐
帮助你提升知识和技能的17个数据科学项目(都是可以免费获取的)
微软发布第四代Phi系列大模型,140亿参数的Phi-4 14B模型数学推理方面评测结果超过GPT 4o,复杂推理能力大幅增强
Dask分布式任务中包含写文件的方法时候,程序挂起不结束的解决方案
未经证实的GPT-4技术细节,关于GPT-4的参数数量、架构、基础设施、训练数据集、成本等信息泄露,仅供参考
超越Cross-Entropy Loss(交叉熵损失)的新损失函数——PolyLoss简介
华盛顿大学提出QLoRA及开源预训练模型Guanaco:将650亿参数规模的大模型微调的显存需求从780G降低到48G!单张显卡可用!