
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



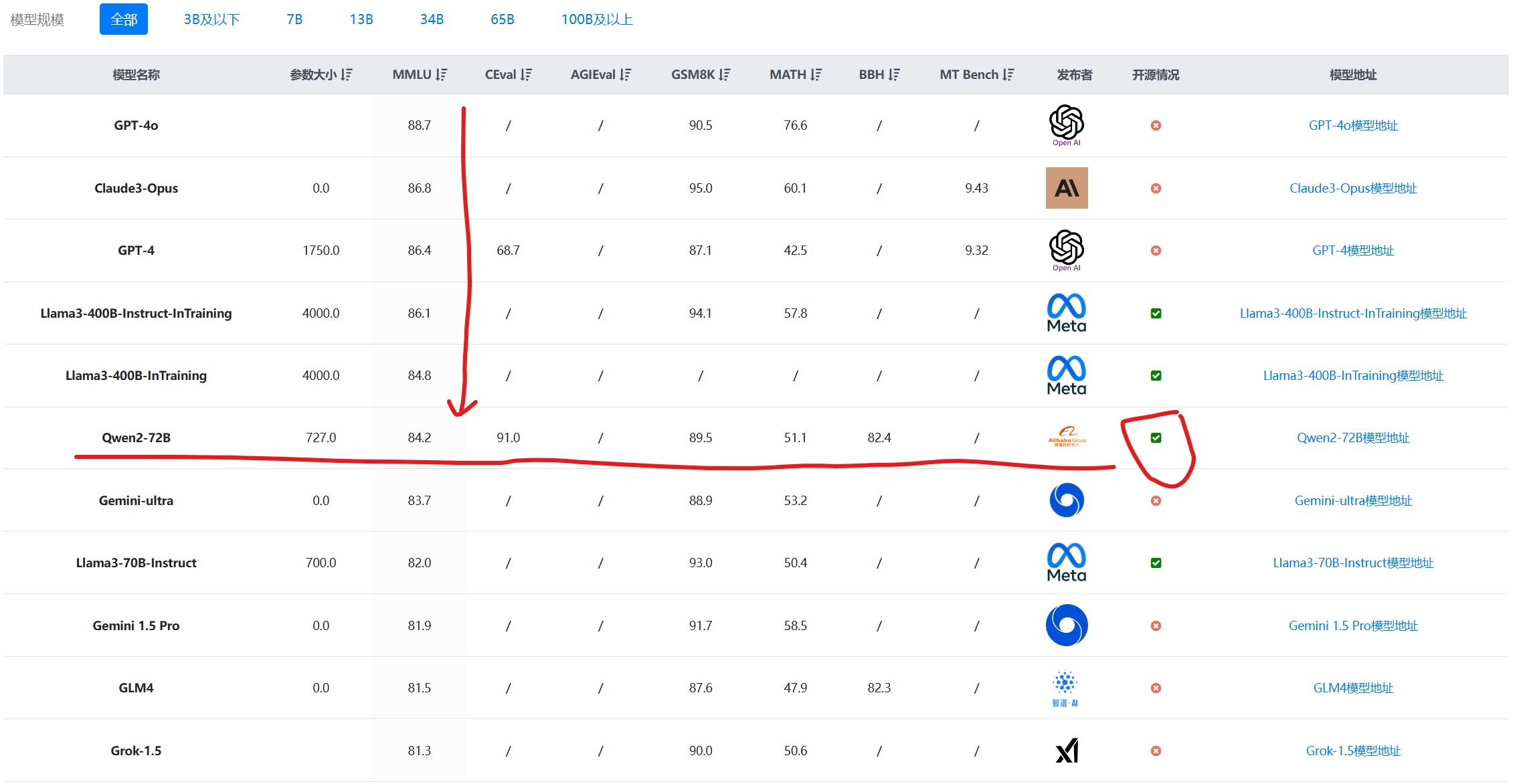
Qwen系列大语言模型是阿里巴巴开源的大语言模型。最早的Qwen模型在2023年8月份开源,当时只有70亿参数规模模型,随后阿里巴巴不断开源新的模型,最高参数规模达到了700亿,版本也从1.0升级到2024年3月份的1.5,再到今天发布的Qwen2系列。Qwen已经开源了几十个不同参数规模的大模型。此次发布的Qwen2.0系列不仅在评测任务上超过了现有的开源模型,也在实际应用中有非常好的表现。
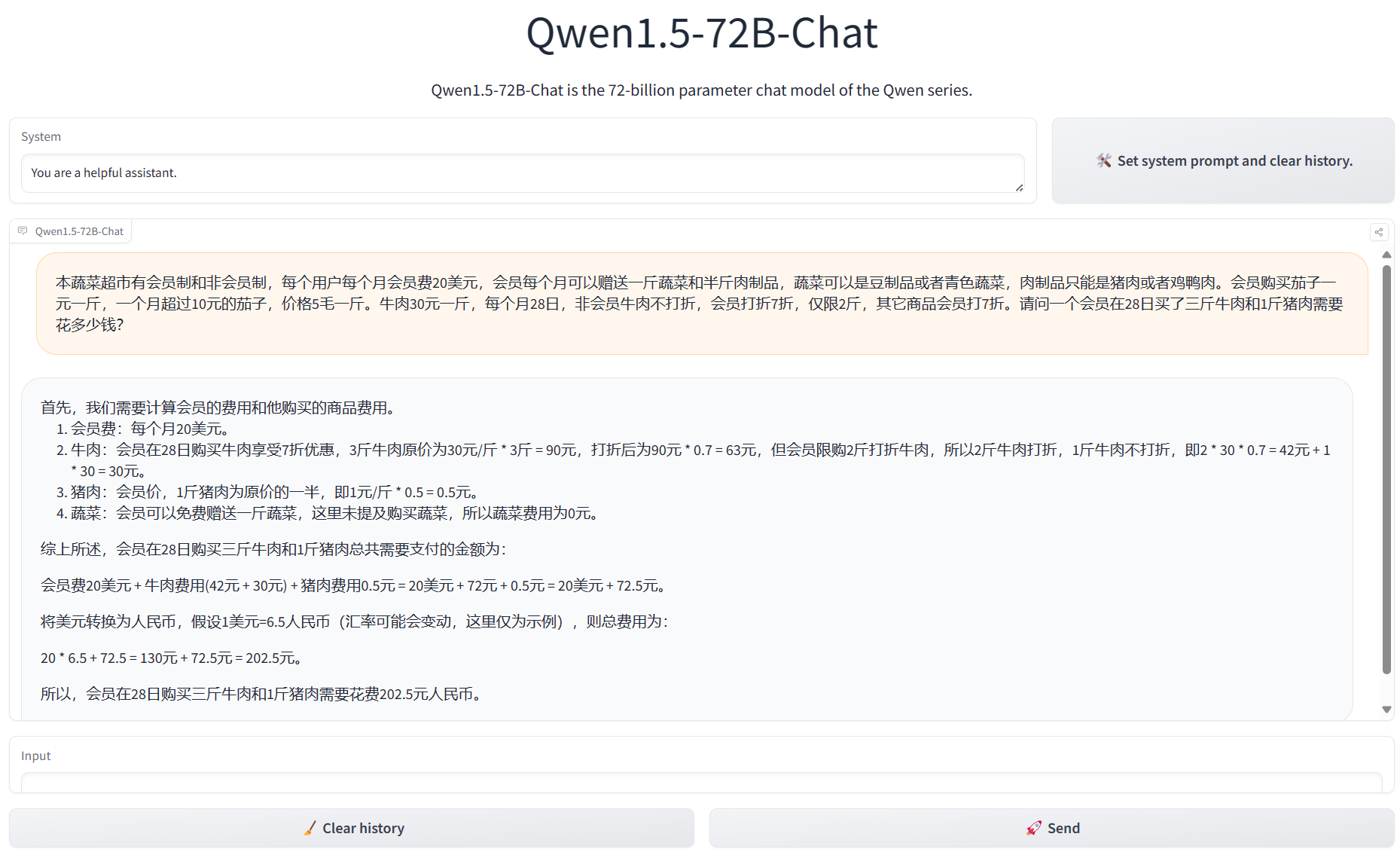
Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为止最强开源模型之一。Qwen1.5是Qwen2的beta版本,此前开源的模型最大参数规模都是720亿,和第一代模型一样。就在刚刚,阿里开源了1100亿参数规模的Qwen1.5-110B模型。评测结果显示MMLU略超Llama3-70B和Mixtral-8×22B。我们实测结果,相比Qwen1.5-72B模型来说,复杂任务的逻辑提升比较明显!
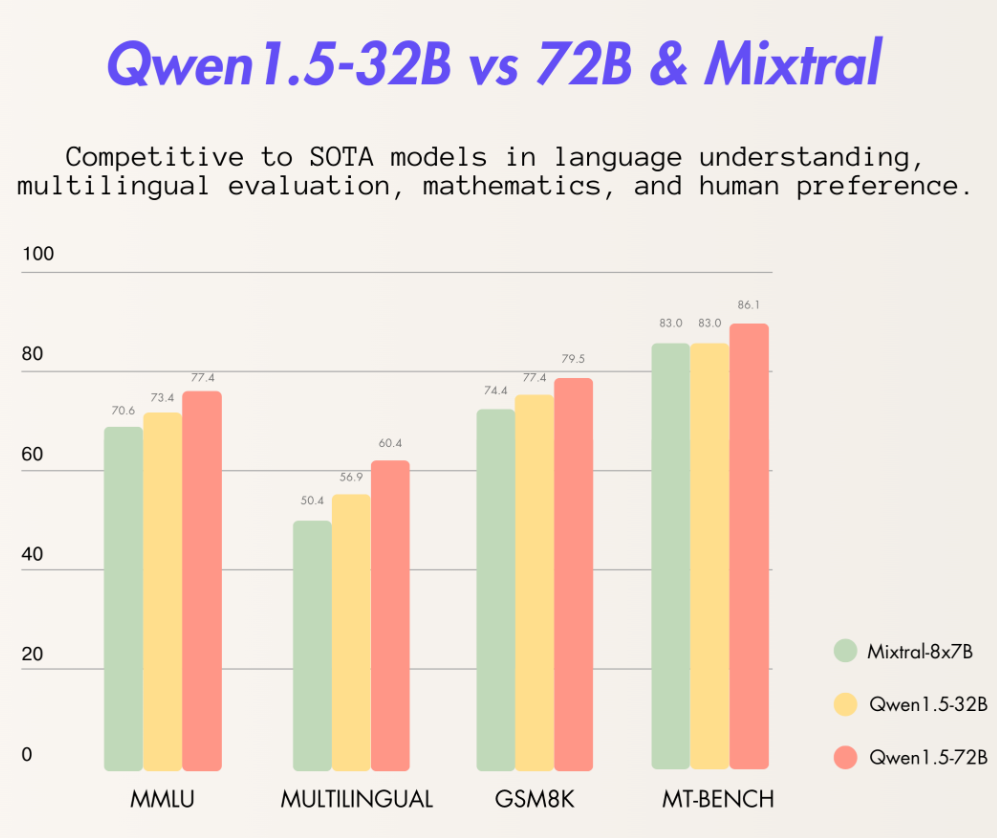
阿里巴巴最新开源了320亿参数的大语言模型Qwen1.5-32B,这个模型在各项评测结果中都略超此前最强开源大模型Mixtral 8×7B MoE,比720亿参数的Qwen-1.5-72B模型略差。但是一半的参数意味着只有一半的显存,这样的性价比极高。

Qwen系列是阿里巴巴开源的一系列大语言模型。在此前的开源中,阿里巴巴共开源了3个系列的大模型,分别是70亿参数规模和140亿参数规模的Qwen-7B和Qwen-14B,还有一个是多模态大模型Qwen-VL。而此次阿里巴巴开源了720亿参数规模的Qwen-72b,是目前国内最大参数规模的开源大语言模型,应该也是全球范围内首次有和Llama2-70b同等规模的大语言模型开源。
今日推荐
OpenAI发布新一代向量大模型,接口已经更新到text-embedding-3-large,embedding长度升级,价格最高下降5倍!
Pseudo-document-based Topic Model(基于伪文档的主题模型)的理解以及源码解读
比OpenAI原始的Whisper快70倍的开源语音识别模型Whisper JAX发布!
检索增强生成(RAG)方法有哪些提升效果的手段:LangChain在RAG功能上的一些高级能力总结
大规模中文开源数据集发布!2TB、几十亿条可商用的中文数据集书生·万卷 1.0开源~中文大模型能力可能要更上一层楼了!
LangChain提升大模型基于外部知识检索的准确率的新思路:更改传统文档排序方法,用 LongContextReorder提升大模型回答准确性!
多元正态(高斯)分布的贝叶斯推导(Bayesian Inference for the Multivariate Normal)
EleutherAI、MetaAI、StabilityAI、伦敦大学等合作的最新关于大语言模型的11个应用方向和16个挑战总结:来自688篇参考文献与业界实践