
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



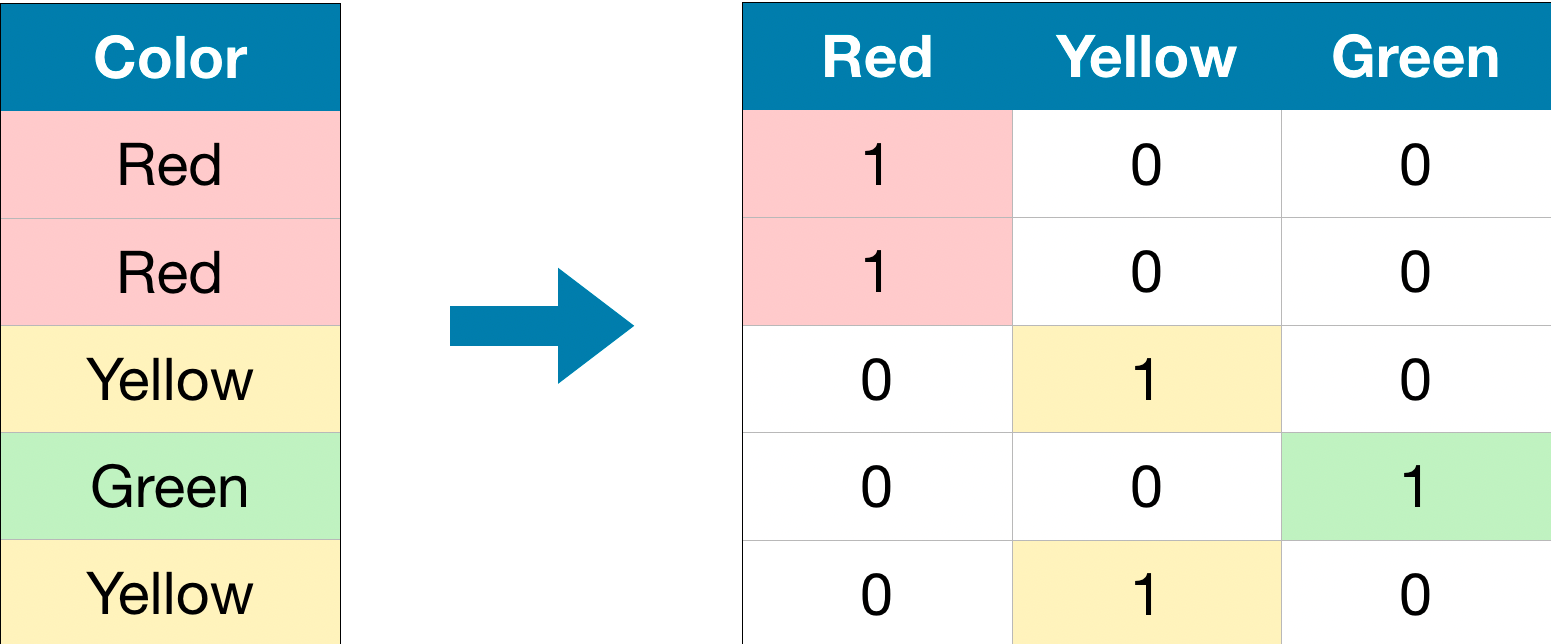
对于分类特征的处理,sklearn中常见的方法有两种,一种是OneHotEncoder,另一种很多人说是LabelEncoder,其实不对。sklearn中,还有一个OrdinalEncoder,二者似乎一样,但其实并不相同,差别很大。本文将用Kaggle的房价预测的实例来描述如何这些差异以及不同处理对预测算法的影响。

预测问题一直是机器学习领域最重要的问题之一。很多算法包括回归、决策树等都是用来解决预测的常用算法。预测问题的核心是基于已有的有标签的数据来判断新数据的标签。一般来说,根据预测标签是离散的还是连续的可以分成分类问题和回归问题。注意,本篇博客主要是快速回顾描述各个模型的优缺点,因此不会对模型有很深的介绍。
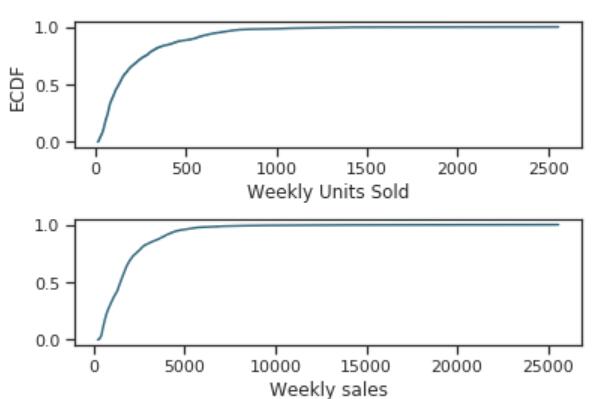
这是一篇来自Towards Data Science上面的一篇个人实践分享,主要是针对销量进行预测。一般来说,销量受到价格、季节等因素影响较大。这里就是考虑这些因素进行的一个实践。值得大家一试。这里我们翻译一下,并对其中的某些工作做一些简单的解释。
