
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



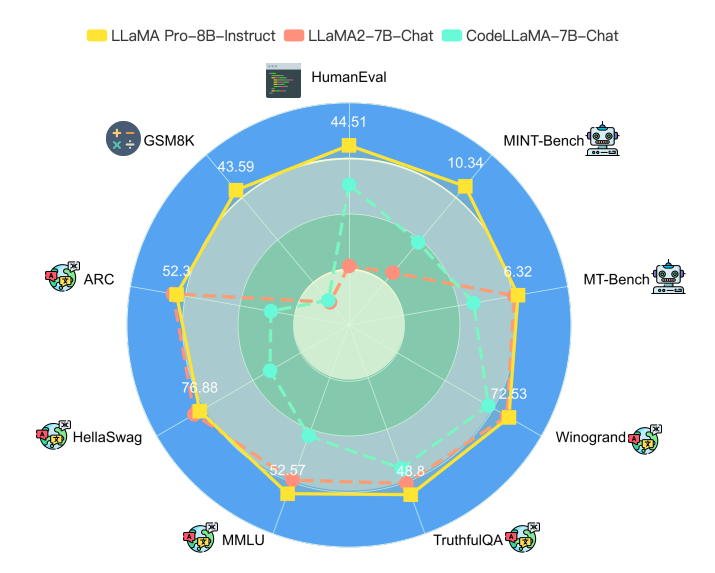
大语言模型一个非常重要的应用方式就是微调(fine-tuning)。微调通常需要改变模型的预训练结果,即对预训练结果的参数继续更新,让模型可以在特定领域的数据集或者任务上有更好的效果。但是微调一个严重的副作用是可能会让大模型遗忘此前预训练获得的知识。为此,香港大学研究人员推出了一种新的微调方法,可以保证模型原有能力的基础上提升特定领域任务的水平,并据此开源了一个新的模型LLaMA Pro。

GPTs是OpenAI推出的用户自定义的GPT功能,这里的GPTs可以认为是specific GPT。用户创建GPTs主要是通过OpenAI提供的GPT Builder完成。GPT Builder提供的最基本的能力就是基于对话的方式来帮助用户创建GPTs。那么,这个对话式的GPT背后的指令是什么?官方设置了什么样的Prompt来让GPT帮助普通用户建立GPTs呢?本文基于官方最新的博客介绍一下。

OpenAI在2023年3月份发布了GPT-4,10个月过去了,目前也没有任何一家产品或者模型可以打败GPT-4。但是,很多人都对2024年抱有非常好的期待,认为2024年会出现能与GPT-4竞争的大模型。包括MistralAI的CEO也说他们会在2024年发布性能媲美GPT-4的大模型。但是,Google前AI研究人员,GalileoAI的联合创始人认为2024年也不会出现这种情况。

2022年11月底,ChatGPT横空出世,全球都被这样一个“好像”有智能的产品吸引力。随后,工业界、科研机构开始疯狂投入大模型。在2023年,这个被称为大模型元年的年份,有很多令人瞩目的AI产品与模型发布。2023年,DataLearner收集了大量的大模型,并发布了很多大模型相关的技术博客,在即将结束的2023年,我们以这个『2023年最令人瞩目的AI产品』结束本年的技术分享。
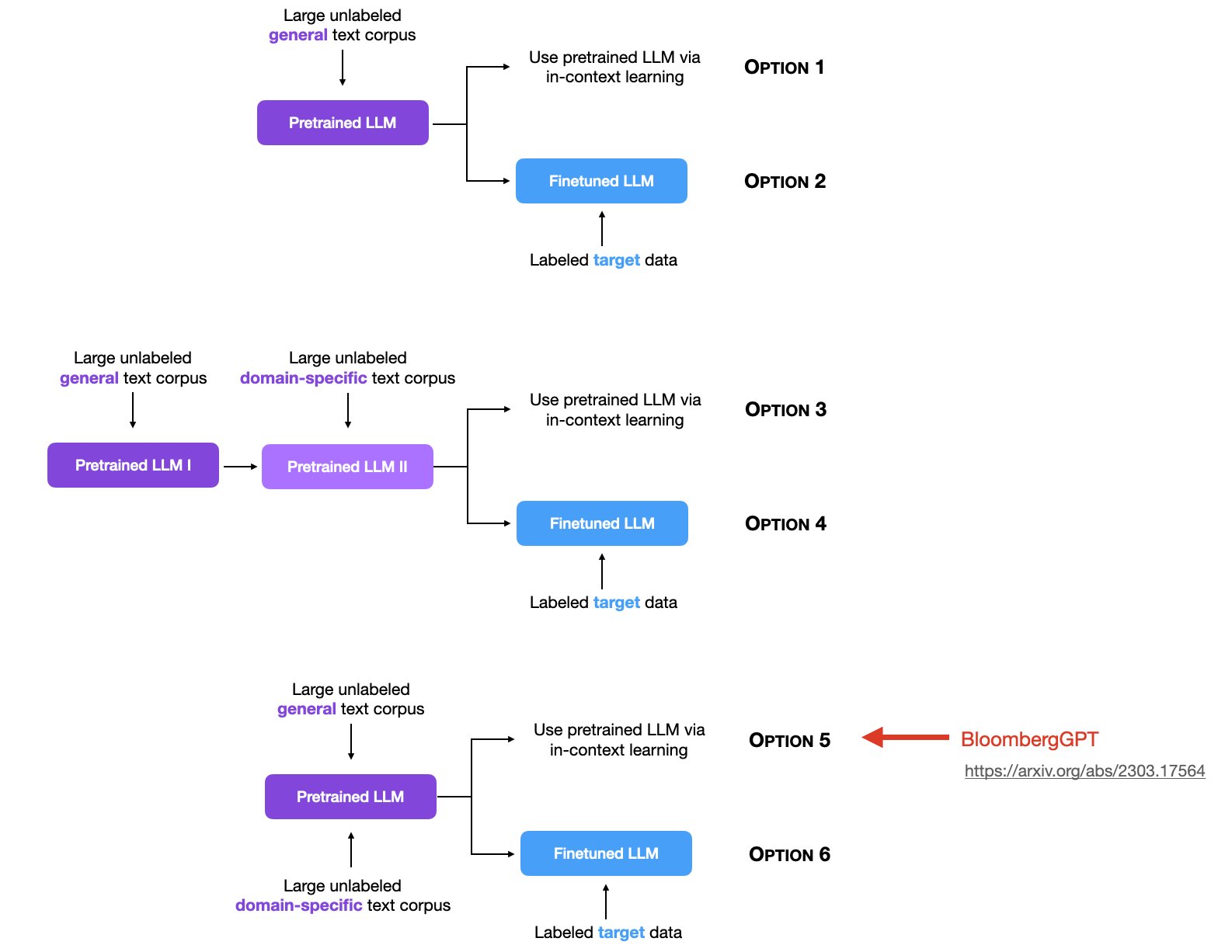
Sebastian Raschka是LightningAI的首席科学家,也是前威斯康星大学麦迪逊分校的统计学助理教授。他在大模型领域有非常深的简介,也贡献了许多有价值的内容。在最新的一期统计中,他总结了6种大模型的使用方法,引起了广泛的讨论。其中,关于使用领域数据集做无监督预训练是目前讨论较少,但十分重要的一个方向。

PerplexityAI是通过搜索引擎检索互联网的内容,然后使用大模型总结答案。产品形态有点像Bing的Bing Chat。圣诞节前夕,PerplexityAI提供了一个优惠代码,可以免费使用他们的2个月的Pro版本订阅服务。PerplexityAI的Pro版本提供GPT-4、Claude-2.1等大模型服务,支持生成图片和基于很长的PDF问答,这2个月的服务十分划算!

大模型的微调是当前很多人都在做的事情。微调可以让大语言模型适应特定领域的任务,识别特定的指令等。但是大模型的微调需要的显存较高,而且比较难以估计。与推理不同,微调过程微调方法的选择以及输入序列的长度、批次大小都会影响微调显存的需求。本文根据LLaMA Factory的数据总结一下大模型微调的显存要求。
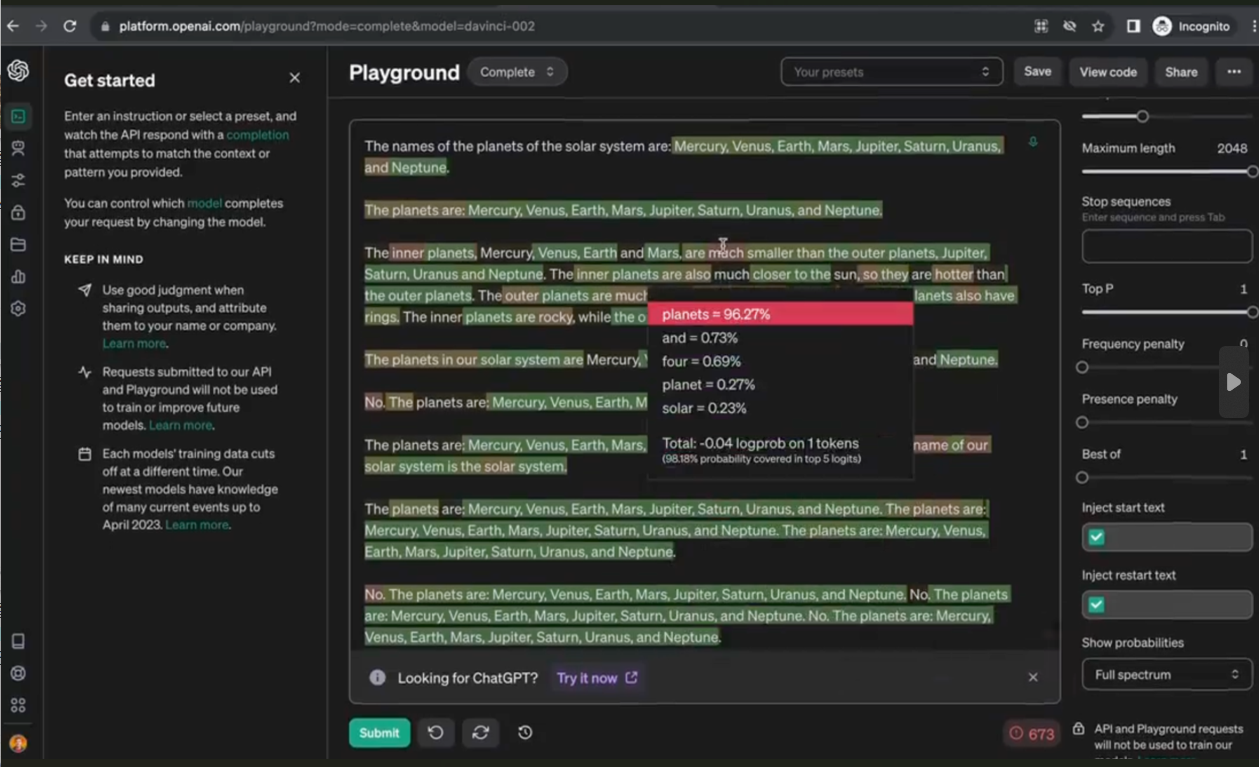
在最新的OpenAI官方接口文档中,新增了top_logprobs和logprobs这2个参数。这2个参数是一起配合使用的。后者是一个布尔类型,表明模型的返回结果中是否增加输出每个token的概率,而top_logprobs参数是一个整数类型,取值范围是0-5之间。如果top_logprobs设置为true,那么模型会根据top_logprobs的设置结果,返回输出结果中每个token及其后续的n个单词的概率。

今天,OpenAI在其官网上发布了一个全新的研究成果:一个利用较弱的模型来引导对齐更强模型的能力的技术,称为由弱到强的泛化。OpenAI认为,未来十年来将诞生超过人类的超级AI系统。但是,这会出现一个问题,即基于人类反馈的强化学习技术将终结。因为彼时,人类的水平不如AI系统,所以可能无法再对模型输出的内容评估好坏。为此,OpenAI提出这种超级对齐技术,希望可以用较弱的模型来对齐较强的模型。这样可以在出现比人类更强的AI系统之后可以继续让AI模型可以遵循人类的意志、偏好和价值观。

网络流传了一张疑似GPT-4.5的定价截图,引爆了很多人的讨论。但是,目前没有人可以确定真假。

Google Gemini是Google最新发布的大模型系列。这是一系列的多模态的大模型,谷歌官方宣布在各项评分中Gemini超过了GPT-4V。但是,谷歌的宣传视频过于夸张被很多人质疑造假嫌疑,导致被全网嘲讽。而今天,Google官方的Gemini多模态接口开放,DataLearnerAI第一时间申请测试,结果让人惊喜。
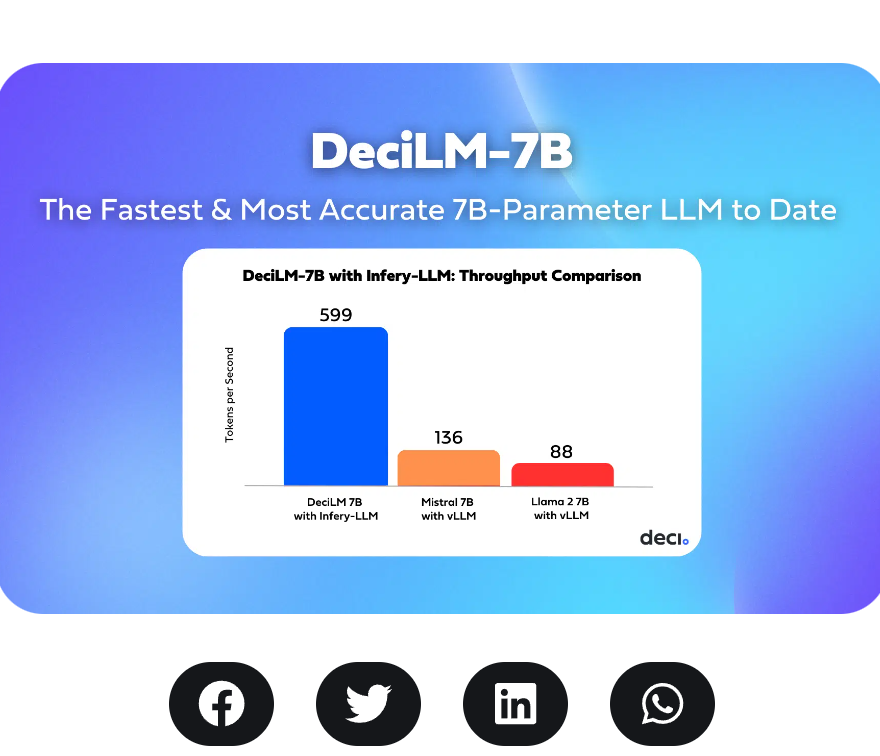
DeciAI是一家成立于2019年的以色列企业,他们最主要的产品是深度学习平台Deci,可以让大家部署运行更快、更准确的模型。包括Adobe、HPE等都是他们的客户。在昨天,他们开源了截止目前可能是Open LLM Leader综合评分最高的大语言模型DeciLM-7B以及指令优化版本的DeciLM-7B-Instruct。最重要的是,这个模型以Apache2.0的协议开源,可以免费商用。

最近一段时间,很多人普遍反映GPT-4变得懒散和愚笨,很多此前可以回答的问题在最近一段时间都无法回答,或者回答比较简单。为此,OpenAI官方也在前几天发布信息说的确收到了这样的信息,但是模型并没有在最近一个多月更新过,所以他们也在好奇是什么原因。而今天的一些测试表明,GPT-4模型会像人一样在不同的时间段有不同的效率。

MistralAI开源的混合专家模型Mistral-7B×8-MoE在本周吸引了大量的关注。这个模型不仅是稍有的基于混合专家技术开源的大模型,而且有较高的性能、较低的推理成本、支持法语、德语等特性。昨天MistralAI发布的不仅仅是这个混合专家模型,还有他们的平台服务La plateforme。在这里他们透露了MistralAI还有更加强大的模型。

12月8日晚上,MistralAI在他们的推特账号上发布了一个磁力链接,大家下载之后根据名字推断这是一个混合专家模型(Mixture of Experts,MoE)。这种模型因为较低的成本和更高的性能被认为是大模型技术中非常重要的路径。也是GPT-4可能的方案。MistralAI在今天发布了博客,正式介绍了这个强大的模型。