CodeLlama-70B-Instruct
编程大模型CodeLlama-70B-Instruct
发布时间: 2024-01-30 3
模型基本信息
是否支持推理过程
不支持
最高上下文输入长度
100K tokens
最长输出结果
模型类型
编程大模型
发布时间
2024-01-30
模型预文件大小
140GB
开源和体验地址
官方介绍与博客
API接口信息
接口速度(满分5分)
接口价格
输入价格:
- 文本: 暂无数据
- 图片: 暂无数据
- 音频: 暂无数据
- 视频: 暂无数据
- Embedding: 暂无数据
输出价格:
- 文本: 暂无数据
- 图片: 暂无数据
- 音频: 暂无数据
- 视频: 暂无数据
- Embedding: 暂无数据
输入支持的模态
文本
输入不支持
图片
输入不支持
视频
输入不支持
音频
输入不支持
Embedding(向量)
输入不支持
输出支持的模态
文本
输出不支持
图片
输出不支持
视频
输出不支持
音频
输出不支持
Embedding(向量)
输出不支持
CodeLlama-70B-Instruct模型在各大评测榜单的评分
发布机构
模型介绍
CodeLLaMA是基于Llama 2基础模型继续训练和微调得到的代码专用语言模型。相比完全从头训练,继承Llama 2的预训练带来明显提升。关于CodeLlama系列模型的介绍参考: https://www.datalearner.com/blog/1051692893755811
CodeLlama系列最早是在2023年8月份发布的。但是不包含700亿参数规模的大模型。在2024年1月30日,MetaAI开源了700亿参数规模版本的CodeLlama-70B,包含三个版本:
| CodeLlama-70B模型版本 | 模型简介 | DataLearner模型信息卡地址 |
|---|---|---|
| CodeLlama-70B-Base | CodeLlama-70B最基础的版本,支持不同的编程语言。 | 点击访问CodeLlama-70B-Base的模型信息卡 |
| CodeLlama-70B-Python | 针对Python编程语言优化的版本。 | 点击访问CodeLlama-70B-Python的模型信息卡地址 |
| CodeLlama-70B-Instruct | 指令优化的编程大模型,可以识别用户的文本指令生成代码。 | 点击访问CodeLlama-70B-Instruct模型信息卡 |
这里说的CodeLlama-70B-Instruct就是其中做过指令对齐优化的模型,也是最强的模型,它可以识别用户指令,基于指令生成代码,而不是一个单纯的代码补全模型。相比较基础版本的CodeLlama-70B-Base和CodeLlama-70B-Python,它的表现更好。
CodeLlama系列模型的代码表现很好,本次开源的CodeLlama-70B系列提升更加明显,其中,基础版本的CodeLlama-70B-Base在HumanEval@1得分53.0分,指令优化版本最高得分67.8,超过了GPT-4论文中的得分(GPT论文分数67分,但是在微软的论文中测试结果是82分)。
根据DataLearnerAI收集的大模型代码评测结果,我们可以看到CodeLlama-70B-Instruct成绩非常优秀。超过了了Gemini Pro:
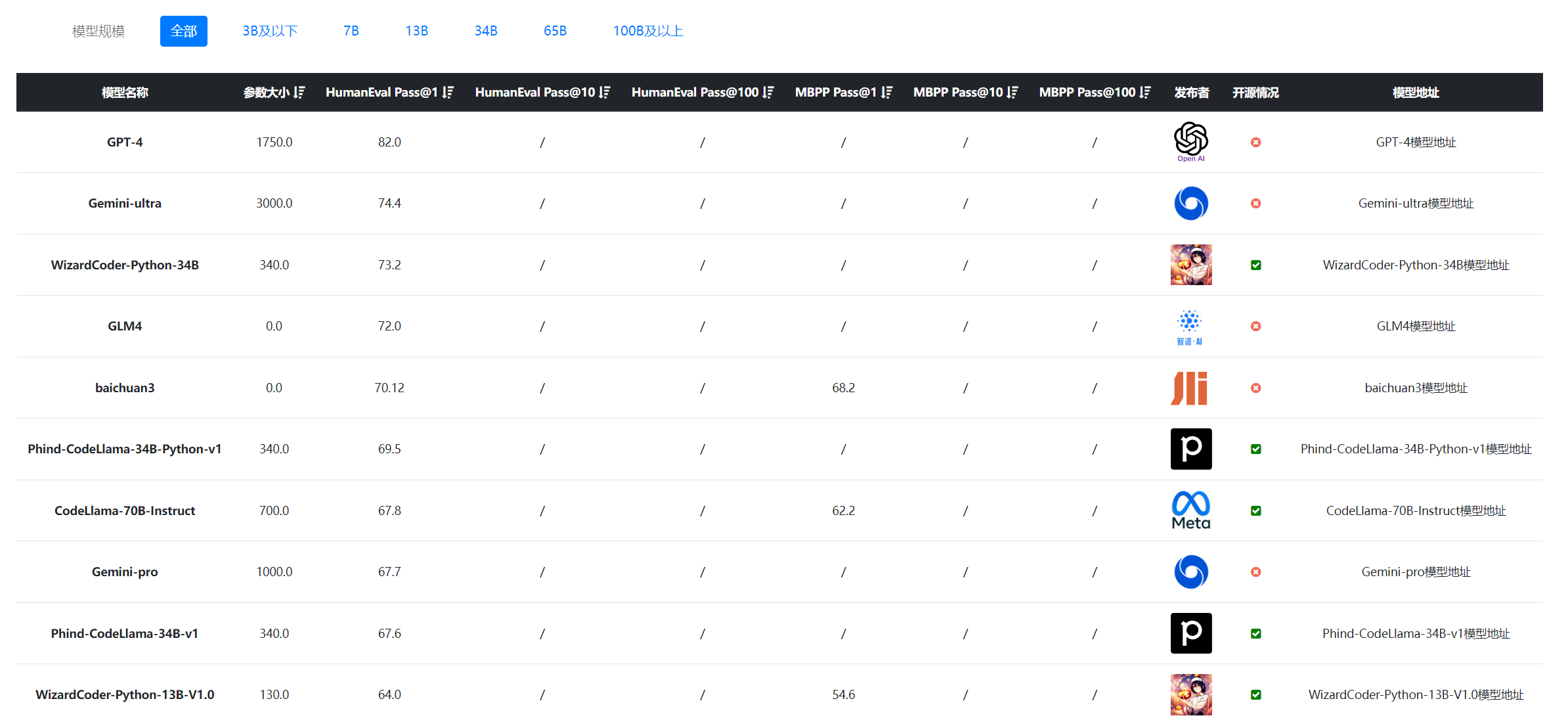
数据来源: https://www.datalearner.com/ai-models/llm-coding-evaluation
由于CodeLlama-70B-Instruct是开源的预训练模型,相比较榜单其它模型,其优势非常明显。其他模型大多数是微调或者闭源模型。
根据官网的论文介绍,CodeLLaMA的特点如下:
- 通过长序列微调(long context fine-tuning),CodeLLaMA系列模型支持高达10万个tokens的输入文本,明显优于只支持4K的Llama 2。在非常长的代码文件中仍表现稳定。
- 在Python代码生成基准测试数据集如HumanEval和MBPP上取得最先进的成绩,尤其是与开源模型相比,基本是最强的。同时也在多语言数据集MultiPL-E上表现强劲。
- CodeLLaMA-Instruct通过自监督生成的代码数据进行指令细调,明显提高了模型的安全性、有用性和遵循指令的能力。
- 采用开源和允许商业用途的许可,可以让更多研究人员和企业基于CodeLLaMA进行创新,推动整个技术领域的进步。
关注DataLearnerAI公众号
关注DataLearnerAI微信公众号,接受最新大模型资讯
