DeepSeek-V3-0324
聊天大模型DeepSeek-V3-0324
发布时间: 2025-03-24 33
模型基本信息
是否支持推理过程
不支持
最高上下文输入长度
160K tokens
最长输出结果
模型类型
聊天大模型
发布时间
2025-03-24
模型预文件大小
700GB
开源和体验地址
官方介绍与博客
API接口信息
接口速度(满分5分)
接口价格
输入价格:
- 文本: 0.27 美元/100万 tokens
- 图片:
- 音频:
- 视频:
- Embedding:
输出价格:
- 文本: 1.1 美元/100万 tokens
- 图片:
- 音频:
- 视频:
- Embedding:
输入支持的模态
文本
输入支持
图片
输入不支持
视频
输入不支持
音频
输入不支持
Embedding(向量)
输入不支持
输出支持的模态
文本
输出支持
图片
输出不支持
视频
输出不支持
音频
输出不支持
Embedding(向量)
输出不支持
DeepSeek-V3-0324模型在各大评测榜单的评分
发布机构
模型介绍
DeepSeek-AI开源的DeepSeekV3更新版本,版本号是0324,是2025年3月24日上传到HuggingFace上并以MIT协议开源。
根据模型提供的配置信息,DeepSeekV3-0324依然是MoE大模型,包含256个路由专家和1个共享专家,每个token使用8个专家推理。DeepSeekV3-0324通过RoPE可以扩展到最高163840上下文长度(160K)。模型词汇表大小是129280个。与DeepSeekV3相比,这些参数都没有变化,这意味着大概率是原有模型继续训练或者后训练的结果~
集成 LoRA 机制,支持轻量级微调。
目前暂无其它信息披露。
2025年3月25日,官方更新了更多的升级内容。总结如下:
DeepSeekV3-0324模型的升级很多
尽管模型架构等技术方面没有变化,但是相比较DeepSeek V3,DeepSeek V3-0324升级却很多,核心是推理能力显著增强。主要总结如下:
前端开发能力优化
针对开发者关心的代码生成质量方面,DeepSeekV3-0324的能力显著增强,主要包括:
- 生成代码的可执行性明显改善
- 网页和游戏前端界面的视觉美观度提升
- 更符合现代Web开发实践要求
在第二点中,已经有多人一句话生成了800行前端网页,很美观。如下图所示:
内容生成质量提升
在官方的介绍中,DeepSeek V3-0324在文本生成质量方面也有明显提示,看介绍应该是用了R1生成的结果做了后训练:
- 严格对齐R1写作风格标准
- 中长篇内容的结构完整性和内容深度增强
- 文学性和专业性表达更加自然流畅
此外,在多轮对话和交互方面也有提升:
- 多轮对话的上下文连贯性改善
- 支持更精准的交互式内容重写
- 翻译质量和正式信函写作能力提升
中文搜索增强
为了支持更好的联网生成效果,DeepSeek V3-0324在报告类请求的分析深度和输出细节方面也有增强,具体来说有如下2点提升:
- 搜索结果整合能力优化
- 支持更复杂的商业分析场景
函数调用改进
最后,DeepSeek V3-0324在函数调用方面也有了优化,主要修复了此前V3版本中的函数调用准确性问题,这意味着在构建AI Agent应用中,DeepSeek V3-0324可能会有更好的效果,具体包含:
- API响应稳定性和可靠性提升
- 复杂参数处理能力增强
DeepSeek V3-0324的评测结果
DeepSeek-V3-0324在多个权威基准测试中展现出突破性进步,相比较DeepSeek V3,DeepSeek V3-0324在多个评测指标中都有显著提升:
- MMLU-Pro:从75.9提升至81.2(+5.3)
- GPQA:从59.1跃升至68.4(+9.3)
- AIME:实现最大幅度提升,从39.6飙升至59.4(+19.8)
- LiveCodeBench:从39.2进步到49.2(+10.0)
而根据DataLearnerAI的大模型官方评测排行榜,以MMLU Pro这种高难度综合知识评测为例,DeepSeek V3-0324已经是仅次于GPT-4.5的非推理大模型。
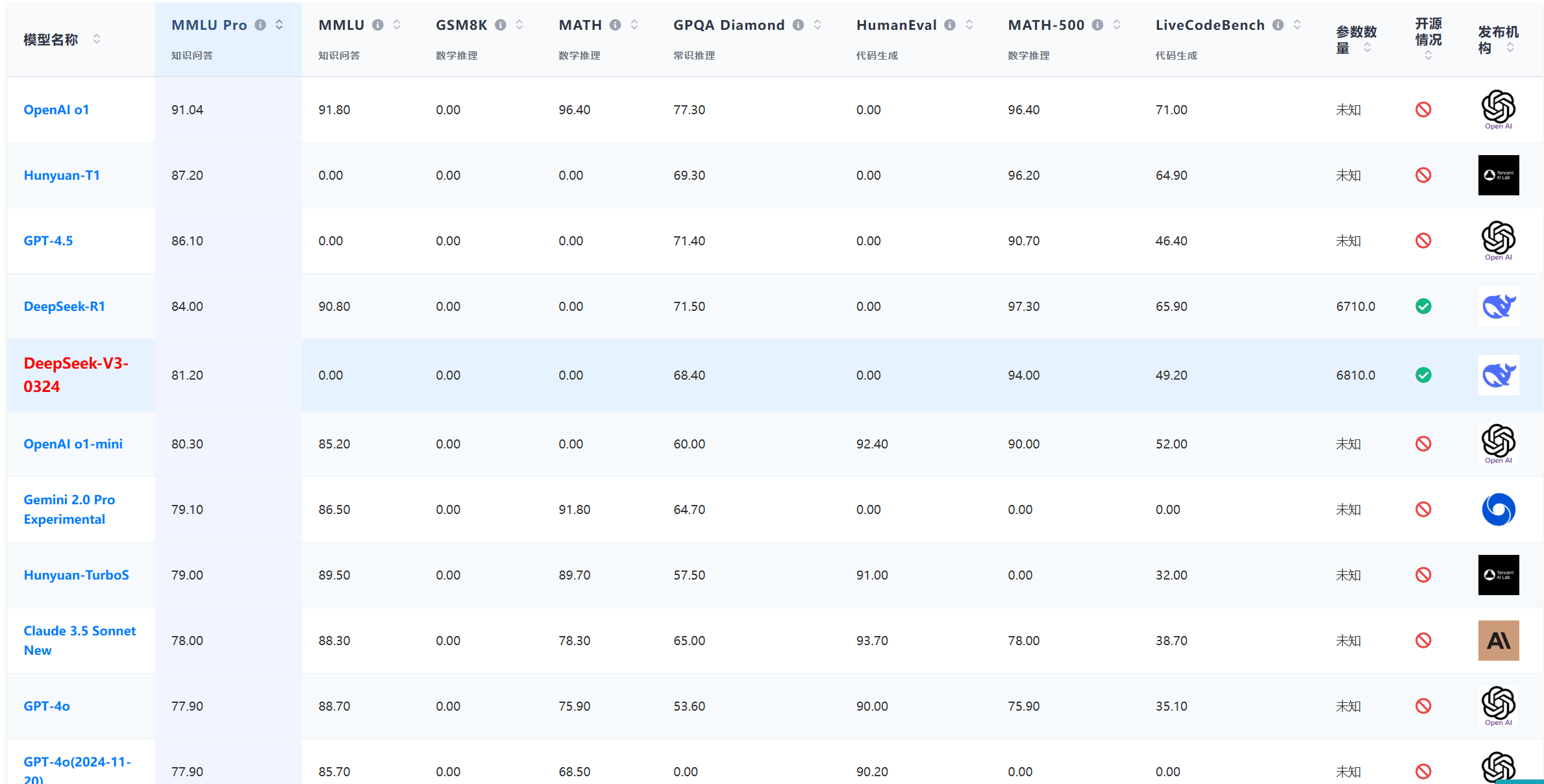
数据来源: https://www.datalearner.com/ai-models/ai-benchmarks-tests/benchmarks-for-all
甚至,在AIME2024的评测中,DeepSeekV3-0324甚至超过了Grok3,成为仅次于DeepSeek-R1的模型。
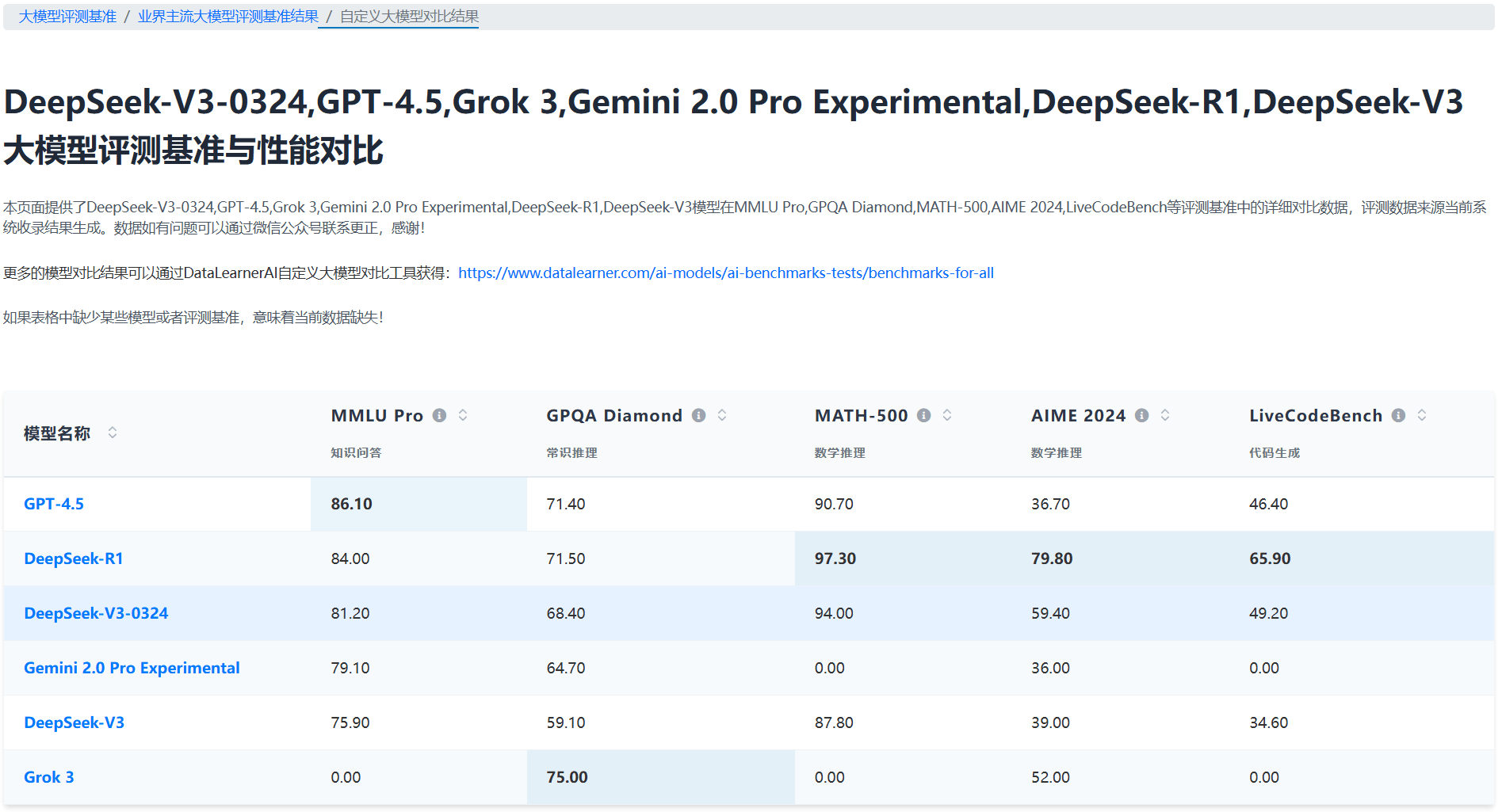
数据来源DataLearnerAI大模型对比评测工具: https://www.datalearner.com/ai-models/ai-benchmarks-tests/compare-result?benchmarkInputString=16,32,36,37,40&modelInputString=543,515,488,492,496,508
而在LiveCodeBench的编程方面也是非常强悍!
关于DeepSeek V3-0324更多的介绍参考DataLearner博客: https://www.datalearner.com/blog/1051742900777784
关注DataLearnerAI公众号
关注DataLearnerAI微信公众号,接受最新大模型资讯
