ImageBind
基础大模型ImageBind
ImageBind 是由 Facebook AI研究实验室 发布的 AI 模型,发布时间为 2023-05-09,定位为 基础大模型,上下文长度为 2K,模型文件大小约 4.5GB。
数据优先来自官方发布(GitHub、Hugging Face、论文),其次为评测基准官方结果,最后为第三方评测机构数据。 了解数据收集方法
模型基本信息
开源和体验地址
官方介绍与博客
API接口信息
评测结果
和其他模型对比
暂时没有为该模型整理的相关对比页面。
想自定义其他组合?打开对比工具
发布机构
模型解读
AI模型在学习时,往往只能接受单一形式的信息,只不过如今这一情况正在改变。来自MetaAI团队的最新进展是,他们开发了一种名为ImageBind的AI模型,该模型可以同时将来自六个形态的信息进行绑定,从而使得机器在多种形式的数据中同时地、完整地、直接地进行学习,而不需要进行显式的监督。
ImageBind不仅可以处理文本、图片/视频和音频,还可以处理记录深度(3D)、热力学(红外线辐射)以及惯性测量单元(IMU,即能够计算物体的运动和位置)的传感器,从而从多重角度为机器提供全面的理解。

该技术比先前的专业模型有更好的表现,同时也能帮助AI技术更好地分析多种不同形式的信息。
ImageBind还为更准确地识别、连接和管控内容、更为扩展的多模态搜索功能等提供了可能性,以及在生成更丰富的媒体时又能更为自然地进行操作等方面,ImageBind都会有所作为。
ImageBind是Meta发展多模态AI系统的一部分。随着模态数量的增加,ImageBind也为研究人员提供了更多开发全面系统的机会。ImageBind的多模态能力可以使研究人员将其他形式的数据作为输入查询,并以其他格式检索输出,从而打通不同形式间的隔阂,进一步构建出类人智能的机器。
ImageBind模型技术解析
ImageBind作为MetaAI新发布的多模态模型,专注于多模态表示学习。从模型设计来说,ImageBind的目标是利用图像绑定(Image Bind)学习一个embedding空间,里面包含了所有模态的信息。
MetaAI将每种模态的embedding与图像embedding进行对齐,例如使用网络数据将文本对齐到图像,使用带有IMU的自我中心相机捕获的视频数据将IMU对齐到视频。
这种对其可以用(I,M)形式的对表示,其中,I表示图像,M表示其它模态的embedding。MetaAI将每个模态M的embedding对齐到图像的embedding中。实际训练中,他们观察到在嵌入空间中出现了一种涌现的行为,即使我们只使用(I,M1)和(I,M2)对进行训练,最后页可以将两个模态对(M1,M2)对齐。这种行为使我们能够执行各种zeor-shot和跨模态检索任务,而无需对它们进行训练。
这样做的好处是你不需要找到拥有所有模态的数据集就可以训练了。
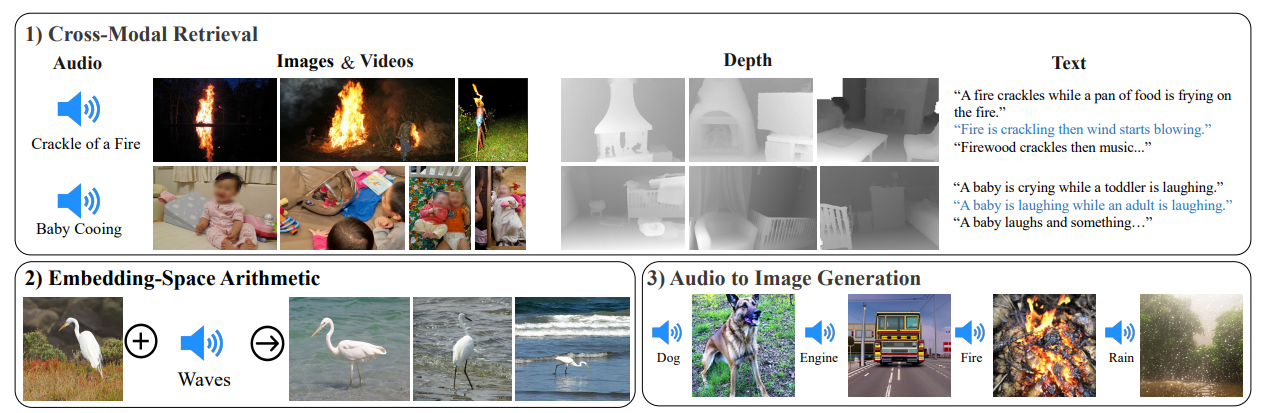
具体来说,ImageBind的主要的步骤如下:
- 跨模态抽取(Cross-Modal Retrieval):这是指显示出不同模态(例如音频、深度或文本)之间的涌现对齐(emergent alignment),尽管它们之间并没有被同时观察到。
- 将来自不同模态的嵌入加在一起可以自然地组合它们的语义。
- 通过使用音频嵌入和预先训练的DALLE-2解码器与CLIP文本嵌入配合使用,可以实现从音频到图像的生成。
在未来,ImageBind可以利用DINOv2的强大视觉特征进一步提高其功能。
DINOv2是MetaAI最新开源的计算机视觉领域的预训练大模型。相比较DINO的第一个版本,作者做了很多的修改,使得v2版本的DINO模型性能更加强大。具体信息可以参考DINOv2在DataLearner上的模型信息卡内容:https://www.datalearner.com/ai-models/pretrained-models/DINOv2
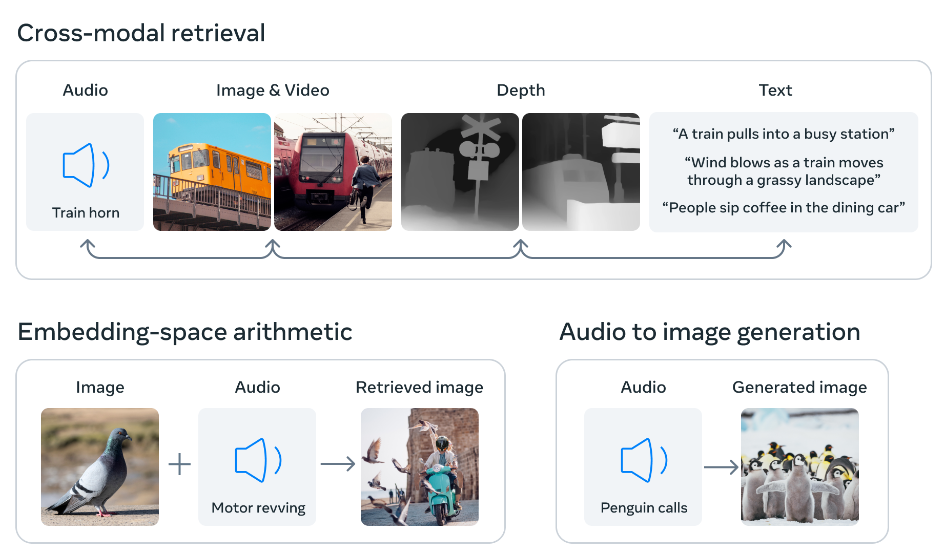
ImageBind通过使用图像对齐将六种模态的嵌入对齐到一个共同的空间来工作。这个联合嵌入空间可以实现跨模态检索、嵌入空间算术运算和音频到图像生成。
以音频生成图像为例,ImageBind使用音频嵌入和一个预训练的DALLE-2解码器来生成图像,该解码器设计用于与CLIP文本嵌入一起工作。这种能力使得可以从音频输入生成图像,这在音乐、电影和游戏等领域具有潜在的应用。例如,它可以用于生成声音效果或音乐作品的视觉表示。
在实践中,ImageBind 利用 web 规模的(图像,文本)配对数据,并将其与自然出现的配对数据(如(视频,音频),(图像,深度)等)结合使用,以学习一个单一的联合嵌入空间。这使得 ImageBind 能够将文本嵌入对齐到其他模态,如音频、深度等,从而实现了对该模态的零样本识别能力,而不需要显式的语义或文本配对。此外,MetaAI还展示了它可以用大规模的视觉语言模型(如 CLIP)进行初始化,从而利用这些模型的丰富的图像和文本表示。因此,ImageBind 可以应用于各种不同的模态和任务,只需要很少的训练。
ImageBind的实际测试效果
ImageBind的特征可用于少样本的音频和深度分类任务,并且可以胜过专门针对这些模态的先前方法。例如,ImageBind在四样本分类的top-1准确度上获得了大约40%的提升,显着优于在Audioset上进行自我监督训练和进行音频分类微调的Meta自我监督AudioMAE模型以及监督AudioMAE模型。
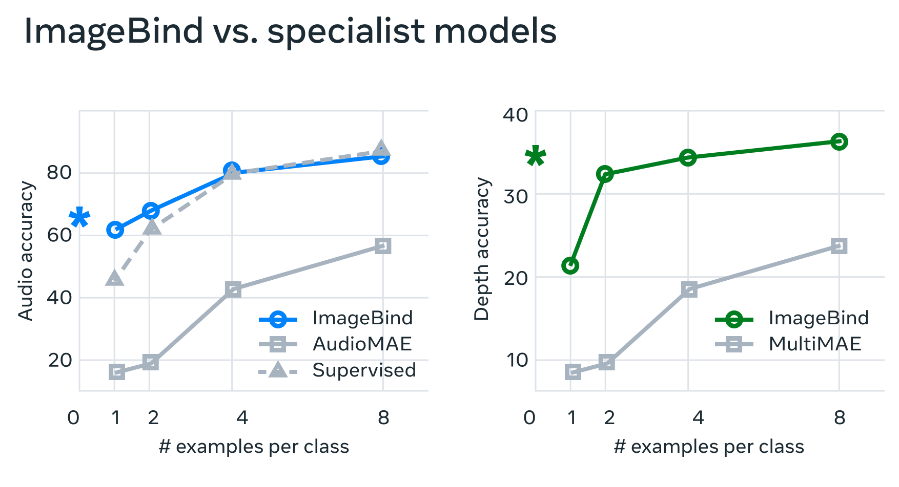
ImageBind还在跨模态的自发零样本识别任务上取得了新的最佳表现,甚至胜过了针对该模态的最近训练的概念识别模型。
ImageBind模型的代码、在线演示等资源
MetaAI开源了ImageBind的预训练结果和代码。同时还有一个在线演示地址,演示了ImageBind的多种能力,主要是:
- 图像生成音频
- 音频生成图像
- 文本生成图像&音频
- 音频&图像生成图像
- 音频生成图像
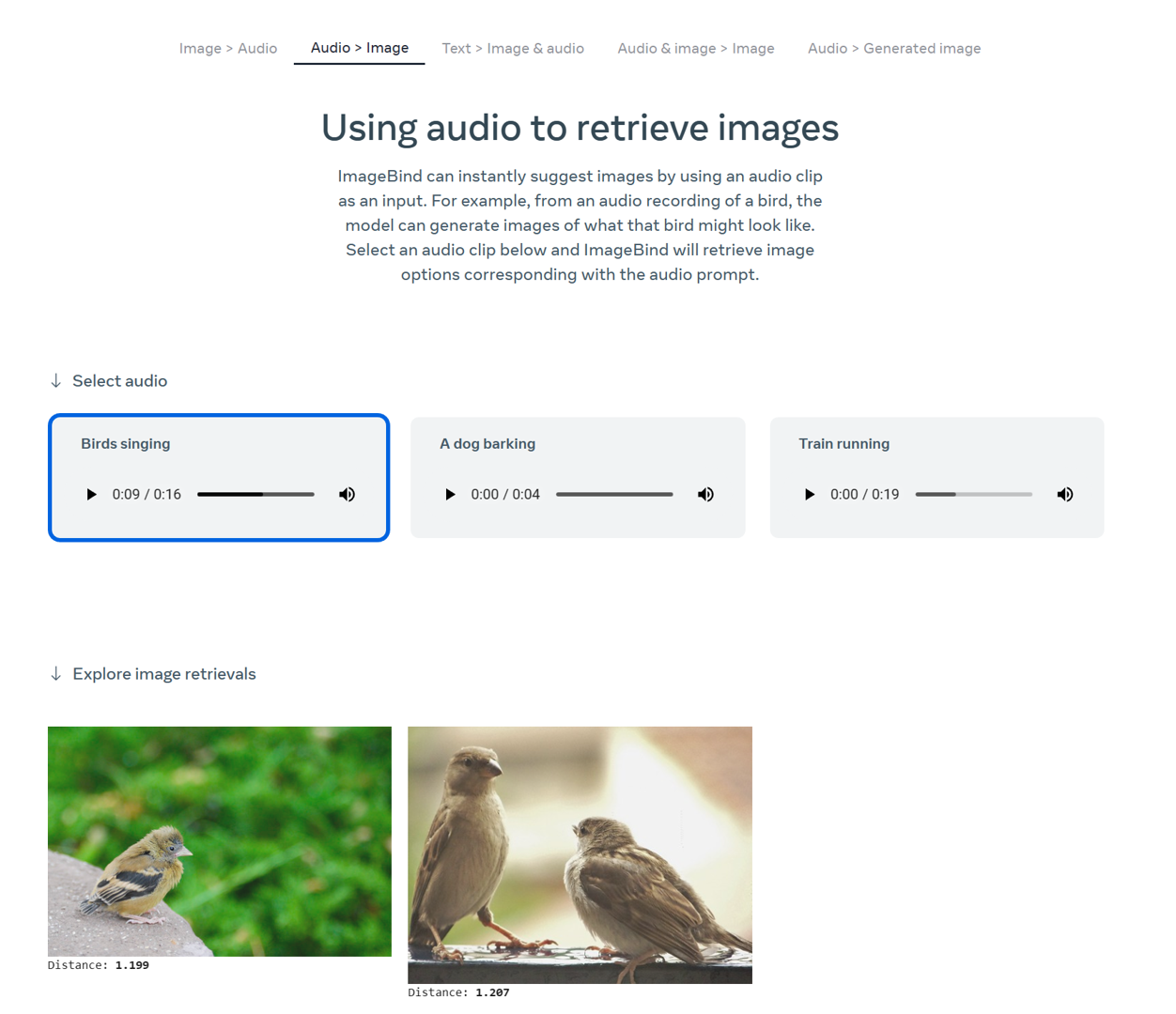
下图是官网中鸟叫音频生成的图像:
相关资源链接如下:
论文地址:https://facebookresearch.github.io/ImageBind/paper
ImageBind官方介绍博客:https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
ImageBind的在线演示地址:https://imagebind.metademolab.com/
ImageBind的演示视频:https://dl.fbaipublicfiles.com/imagebind/imagebind_video.mp4
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
