AI大模型学习
原创AI博客
大模型技术资讯
大模型评测排行
大模型评测排行榜
大模型数学推理能力排行榜
大模型代码编程能力排行榜
大模型图片编辑能力排行榜
LMSys ChatBot Arena排行榜
Berkeley大模型工具使用能力排行榜
大模型综合能力排行榜(旧)
大模型编程能力排行榜(旧)
OpenLLMLeaderboard中国站
AI大模型大全
最新大模型列表
大模型部署教程
大模型对比工具
大模型评测基准
大模型评测基准
SWE Bench Verified
ARC-AGI-2
AIME 2025
FrontierMath-Tier4
MMMU
AI Agents列表
AI资源仓库
AI领域与任务
AI研究机构
AI数据集
AI开源工具
数据推荐
国产AI大模型生态全览
AI模型概览图
AI模型月报
AI基础大模型
AI工具导航
AI大模型工具导航网站
在线聊天大模型列表
A Biterm Topic Model for Short Texts
小木
WWW
2013-05
7903
2017/02/06 09:56:52
由于传统的话题模型主要是获取文档级别的词共现,对于短文来来说,数据的稀疏性导致了传统话题模型效果不好。为了解决这个问题,作者提出了一个新的模型(biterm topic model, BTM)来为短文本建模。BTM通过语料级别的词共现来为短文本建模。BTM的主要优点包括:1)直接利用了词共现的优势为短文本建模;2)BTM使用语料级别的词共现模式聚合来解决文档级别的稀疏性。 传统话题模型在短文本上应用困难。现有工作已经有了一些解决方案。一是通过聚合短文本,比如讲一个人发表的所有的微博合在一起作为一篇文档。但这类方法受制于数据。二是通过做一些比较严格的假设,如一个短文本只包含一个话题,或者是一句话来自于同一个话题等。但这些假设破坏了文档的完整性,有过拟合的问题。作者则通过获取语料级别的词共现来解决这个问题。作者的想法来自于两个问题:1)既然话题是由一组相关的词语组成,而相关的词语则是由词共现来揭示,那为什么不直接对词共现进行建模?2)既然短文话题建模受制于文档的数据,那为什么不使用语料级别的词共现模式? BTM 首先从语料级别抽取所有的二元词组,即抽取Biterm对。这个过程很简单。比如“I visit apple store”,去除I停用词后,抽取的二元词组包括{visit apple},{visit store},{apple store}。 然后作者把所有的语料当做一个文档。具体来说,就是作者将语料看做是一组话题的混合,每个二元词组都是来自于某个话题。一个二元词组属于某个话题的概率由二元词组里面两个单词从同一个话题中抽样得到。该模型的生成过程如下: 1)对于每个话题z 抽取话题-词分布$\phi_z \sim \text{Dir}(\beta)$ 2)从Dirichlet先验中获取话题的分布$\theta \sim \text{Dir}(\alpha)$ 3)对于二元词组集合B中的每个二元词b (a)抽取一个主题$z \sim \text{Multi}(\theta)$ (b)抽取两个单词$w_i,w_j \sim \text{Multi}(\phi_z)$ 最终可以得到二元词组的联合概率: ```math P(b) = \sum_z P(z)P(w_i|z)P(w_j|z)=\sum_z\theta_z\phi_{i|z}\phi_{j|z} ``` 最终作者做了几个实验。。但是我看主题下的词语分布,前20个词语的结果与人工判断感觉提升不明显。 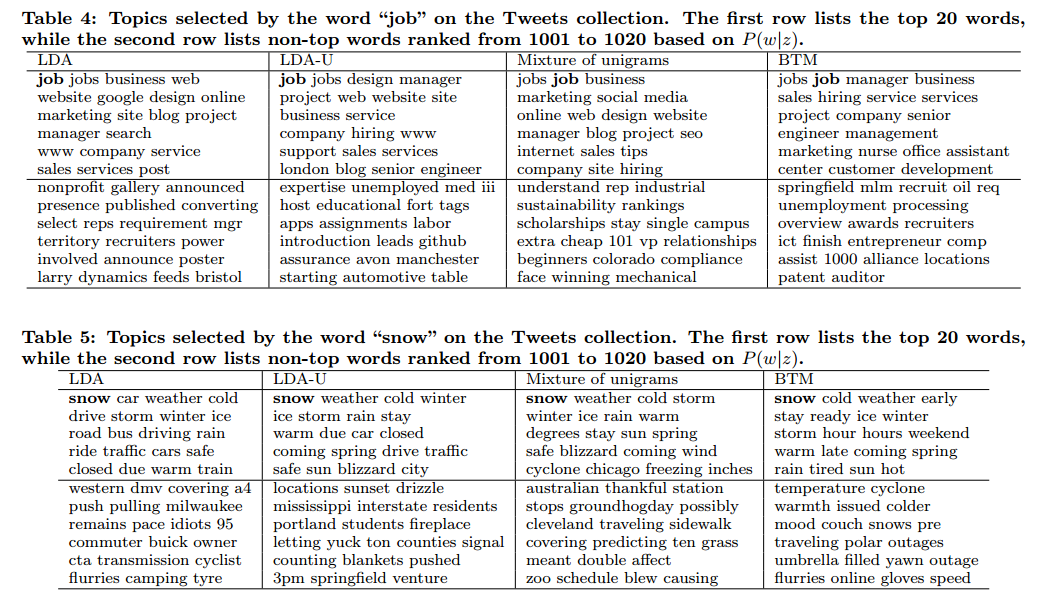
赏
支付宝扫码打赏
如果文章对您有帮助,欢迎打赏鼓励作者
Back to Top
 支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏