AI大模型学习
原创AI博客
大模型技术资讯
大模型评测排行
大模型评测排行榜
大模型数学推理能力排行榜
大模型代码编程能力排行榜
大模型图片编辑能力排行榜
LMSys ChatBot Arena排行榜
Berkeley大模型工具使用能力排行榜
大模型综合能力排行榜(旧)
大模型编程能力排行榜(旧)
OpenLLMLeaderboard中国站
AI大模型大全
最新大模型列表
大模型部署教程
大模型对比工具
大模型评测基准
大模型评测基准
SWE Bench Verified
ARC-AGI-2
AIME 2025
FrontierMath-Tier4
MMMU
AI Agents列表
AI资源仓库
AI领域与任务
AI研究机构
AI数据集
AI开源工具
数据推荐
国产AI大模型生态全览
AI模型概览图
AI模型月报
AI基础大模型
AI工具导航
AI大模型工具导航网站
在线聊天大模型列表
Making the Most of Crowdsourced Document Annotations: Confused Supervised LDA
小木
CoNLL
2015-09
2839
2017/02/06 09:46:55
从群体智慧中获取腿短结果非常有效,其最常用的方法是使用投票最多的结果作为结论。但这会忽略掉一些重要的信息。比如,有些标注者的可靠性不同,高可靠的标注者应当具有更高的权重。好的众包方法应当有一个概率机制能倾向于好的标注者。因此,评估标注者本身的专业程度是非常重要的一个问题。作者提出了一个模型,它同时对标注者和数据特征建模,用以提升众包的效果。 首先介绍一个简单的概率模型。它是1979年的文章,后来的模型大多数基于整个模型的改进。这个方法被称为ITEMRESP。它有一个混淆矩阵$\gamma_j$,它是来自于标注者$j$。每个混淆矩阵$\gamma_j$的行$\gamma\_{jc}$是来自一个对称的Dirichlet分布$Dir(b\_{jc}^{(\gamma)}$,它是类标签的概率分布,是当当前文档的真实标签为c的情况下,标注者j对文档标注结果的概率分布。那么,对于每个文档$d$,我们都可以抽取一个标签$y_d$。标注者j根据类别分布$Cat(\gamma\_{jy\_{d}}$生成一个标注结果。 ####利用数据的扩展 ITEMRESP有很多的扩展,其中之一是对数据的特征进行建模。主要包括判别模型和生成模型两类。Felt认为生成模型在众包场景下更为合适,因为生成模型的学习比条件模型更快。ITEMRESP的扩展通常认为所有的文档都有一个共同高层次的结构。当每个文档$d$的标签抽取出来之后,该标签下的特征也就可以抽取了。Felt就提出了MONRESP模型,如图2所示,来表示众包的模型。在MOMRESP模型中,文档$d$的特征向量$x_d$来自参数为$\phi_y_d$的多项式分布。这种模型继承了很多朴素贝叶斯模型的优点(更简单的推导以及更好的偏差推导能使模型具有更好的鲁棒性)和缺点(对条件独立假设的严格限制导致对文档的特征的偏好,而降低了标注者特征的结果)。 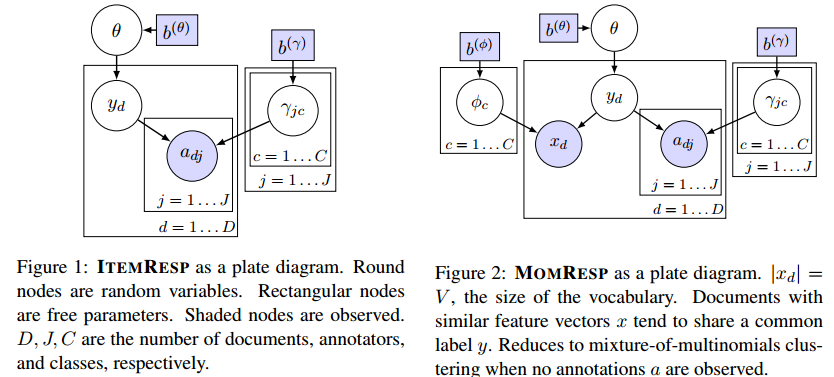 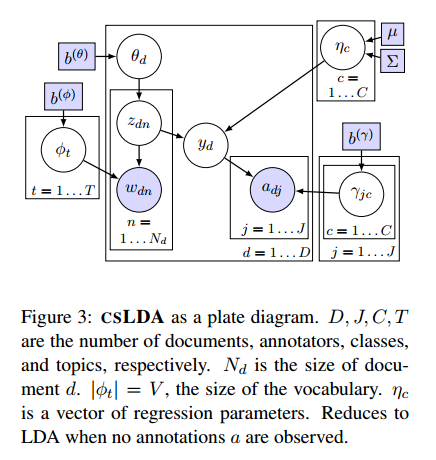 ####Confused Supervised LDA(csLDA) 作者通过一个新的模型来解决MOMRESP降低标注者权重的缺点。该模型将之前文档中类-条件结构变成了一个更加复杂的结构。作者先抽取一个文档,然后再通过log-linear抽取一个标签。同时,作者对话题和标签进行联合建模从而学习潜在的文档表示模型,能更好的预测更正标注者的错误。 作者的模型是基于有监督的话题模型改进而来。sLDA可以更好的将文档类别与主题结合起来。csLDA的生成过程如下: 1、从$Dir(b^{(\theta)})$中抽取主题词分布$\phi_t$ 2、从$Gauss(\mu,\sum)$中抽取类别的回归参数$\eta_c$ 3、从$Dir(b\_{jc}……{(\gamma)}$中抽取标注者的混淆矩阵$\gamma_j$ 4、对于每一个文档d (a)从$Dir(b^{(\theta)})$中抽取话题向量$\theta_d$ (b)对于每个单词n,从$Cat(\theta_d)$中抽取主题$z\_{dn}$,然后从$Cat(\phi_z\_{dn})$中抽取单词$w\_{dn}$ (c)抽取类标签$y_d$ (d)对于每个标注者,从$\gamma\_{jyd}$中抽取标注向量$a\_{dj}$
赏
支付宝扫码打赏
如果文章对您有帮助,欢迎打赏鼓励作者
Back to Top
 支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏