AI大模型学习
原创AI博客
大模型技术资讯
大模型评测排行
大模型评测排行榜
大模型数学推理能力排行榜
大模型代码编程能力排行榜
大模型图片编辑能力排行榜
LMSys ChatBot Arena排行榜
Berkeley大模型工具使用能力排行榜
大模型综合能力排行榜(旧)
大模型编程能力排行榜(旧)
OpenLLMLeaderboard中国站
AI大模型大全
最新大模型列表
大模型部署教程
大模型对比工具
大模型评测基准
大模型评测基准
SWE Bench Verified
ARC-AGI-2
AIME 2025
FrontierMath-Tier4
MMMU
AI Agents列表
AI资源仓库
AI领域与任务
AI研究机构
AI数据集
AI开源工具
数据推荐
国产AI大模型生态全览
AI模型概览图
AI模型月报
AI基础大模型
AI工具导航
AI大模型工具导航网站
在线聊天大模型列表
The Multidimensional Wisdom of Crowds
小木
NIPS
2010-09
2516
2017/05/04 17:26:50
在现实生活中,有很多工作需要人工来标注数据。但是,每个人的标注能力不同,单个人标注可能会出现较多错误,所以在实际情况中,我们都是要让多个工作者标注同个数据来降低错误率,然后通过算法推断真实的数据标签。作者认为,人工标注的数据包含“噪音”,主要来自:1)每个工作者的背景不一样,因此在不同的任务中表现不同;2)标注者在不同错误率下的标注成本不同,因此有不同的偏差;3)不同的数据,有些容易标注,有些难以标注。尽管以前的工作都对某一个方面的“噪音”进行了建模,但实际中还缺少把所有的噪音融合到一个模型中的方法。在这篇文章中,作者提出了一个生成贝叶斯模型,用来为标注过程建模。 ####标注过程 一个标注者,索引为$j$,在查看图片$I\_i$,并赋予标签$l\_{ij}$。有能力的标注者会提供准确的标签,然而有些标注者可能会提供一些不一致的标签。作者将这个标注过程当做一系列步骤进行建模。有$N$个图片,是通过某种图片收集手段得到的。首先,一个变量$z\_i$表示哪一个对象产生了图片$I\_i$。比如说,$z\_i \in \\{0,1\\}$表示图中是否存在某种鸟类。有很多“令人讨厌的”因素会影响这个“存在”,如视角和姿势等。每个图片都是通过某种转换方式,将像素转换成了与任务相关的变量$x\_{i}$,代表了某个标注者能看到的内容。比如,这个$x\_i$是那些最好的标注者脑袋里面关于任务的神经元的激活速率(也就是认知能力吧,可以这么理解)。也可以认为是一个视觉的向量,包括形状、颜色等,能够被标注者用来识别物体的。那么,一个对象$z\_i$产生了某个信号$x\_i$是随机的,它可以用一个参数为$\theta\_{z}$的函数表示图片的生成过程。这段话很容易理解,就是说每个图片属于某种类别,这个类别可以不管它是什么,就是能决定图片上有什么物体的类别。然后图片是这个类别对应的某个参数为$\theta\_z$的分布产生的样本。 我们总共有$M$个标注,标注了图像$i$的标注者集合为$\mathcal{J}\_i$。标注者$j\in \mathcal{J}\_i$,被选择用来标注图像$I\_i$。但并不是直接接触$x\_i$,而是$y\_{ij}=x\_i+n\_{ij}$,是受到标注者和图像相关的“噪音”$n\_{ij}$影响的版本。这个噪音对每个标注者来说都是不一样的,它是由一个参数为$\sigma\_j$的分布控制的。同时,对于有能力的标注者来说,这个噪音的方差必须是很低的。向量$y\_{ij}$可以理解成一个认知编码,它表示所有可能影响标注者判断的因素。每个标注者都是一个参数为$\hat{w}\_{j}$控制的,表示标注者对每个对象认知的偏差。标量投影$< y\_{ij},\hat{w}\_{j} >$与一个阈值$\hat{\tau}\_j$比较。如果信号高于阈值,标注结果为1,如果信号低于阈值,结果为0。 <center> 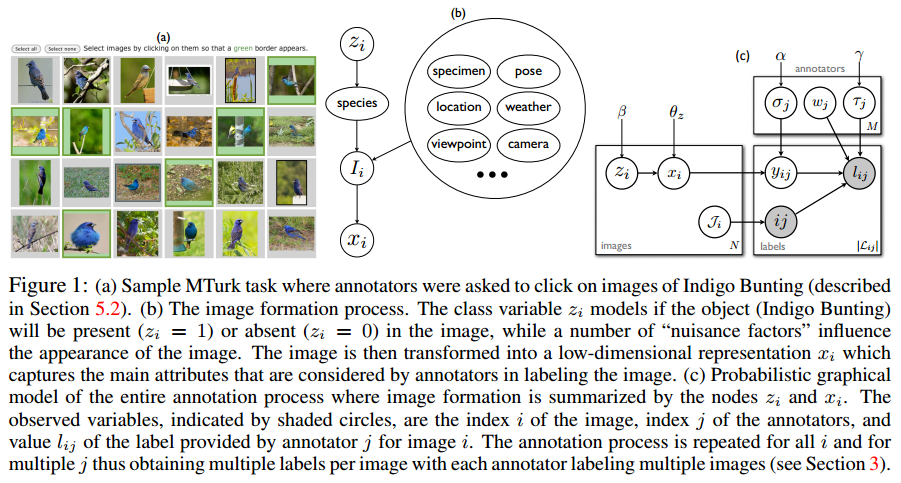 </center>
赏
支付宝扫码打赏
如果文章对您有帮助,欢迎打赏鼓励作者
Back to Top
 支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏