AI大模型学习
原创AI博客
大模型技术资讯
大模型评测排行
大模型评测排行榜
大模型数学推理能力排行榜
大模型代码编程能力排行榜
大模型图片编辑能力排行榜
LMSys ChatBot Arena排行榜
Berkeley大模型工具使用能力排行榜
大模型综合能力排行榜(旧)
大模型编程能力排行榜(旧)
OpenLLMLeaderboard中国站
AI大模型大全
最新大模型列表
大模型部署教程
大模型对比工具
大模型评测基准
大模型评测基准
SWE Bench Verified
ARC-AGI-2
AIME 2025
FrontierMath-Tier4
MMMU
AI Agents列表
AI资源仓库
AI领域与任务
AI研究机构
AI数据集
AI开源工具
数据推荐
国产AI大模型生态全览
AI模型概览图
AI模型月报
AI基础大模型
AI工具导航
AI大模型工具导航网站
在线聊天大模型列表
Hidden Topic Markov Models
小木
AISTATS
2007-09
2351
2017/05/05 20:51:33
这篇文章作者将每个文档中单词的主题当做一个马尔可夫链。作者假设一条语句中的所有的单词都属于同一个主题,连续的句子更可能是属于同一个主题。由于主题是隐的,因此我们可以使用隐马尔科夫模型来学习和推断。LDA模型本身是一个基于词袋的模型,词语与词语之间没有顺序。有一些模型,如Bigram Topic Model、LDA Collection Model和Topical n-grams Model等都假设每个单词的主题与前面几个词的单词的主题是一样的。这使得模型变得复杂,但也给LDA带来了更好的预测能力。这篇文章提出了一个隐主题马尔科夫模型。如图1c所示,一个文档中的主题组成了一个马尔可夫链,其转移矩阵依赖于$\theta$和主题转移变量$\psi\_n$。当$\psi\_n=1$的时候,单词从一个新的主题中抽取,当$\psi\_n=0$的时候,当前单词的主题与前一个单词的主题一样。作者假设主题的转移仅仅发生在句子之间,因此$\psi\_n$可能只在一个句子的第一个单词不是0。因此,作者的模型可以描述如下: 1、对于每个主题$z=1,\cdots,K$, 抽取$\beta\_z \sim \text{Dirichlet}(\eta)$ 2、对于每个文档$d=1,\cdots,D$, (a)、抽取$\theta \sim \text{Dirichlet}(\alpha)$ (b)、设置$\psi\_1=1$ (c)、对于每个单词$n=2,\cdots,N\_d$ 如果是开始的句子,那么抽取$\psi\_n \sim Binom(\varepsilon)$,否则的话$\psi\_n=0$ (d)、对于每个单词$n=1,\cdots,N\_d$ 如果$\psi\_n==0$,那么$z\_n=z\_{n-1}$,否则抽取一个新主题$z\_n \sim multinomial(\theta)$ 抽取一个新单词$w\_n \sim multinomial(\beta\_{z\_n})$ <center> 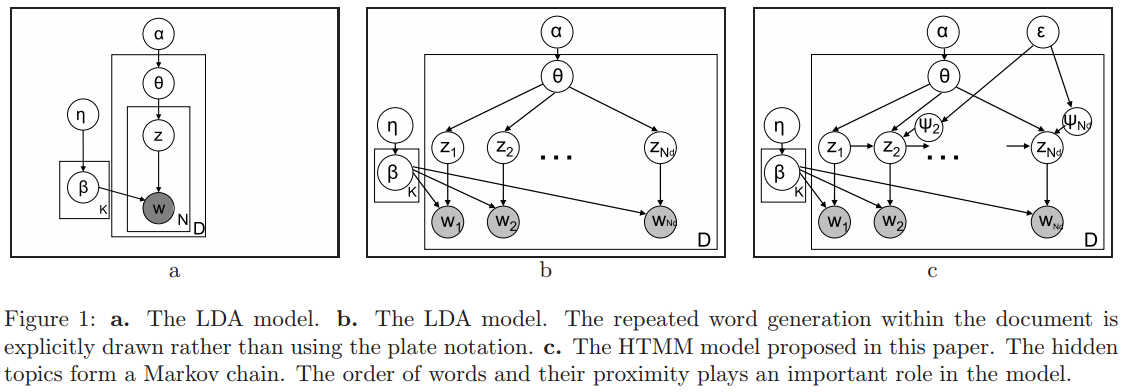 </center>
赏
支付宝扫码打赏
如果文章对您有帮助,欢迎打赏鼓励作者
Back to Top
 支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏
支付宝扫码打赏