目前业界支持中文大语言模型开源和商用许可协议总结
目前,业界开源的大语言模型越来越多,性能也越来越强大。然而,这些开源模型大多数由国外的机构贡献,对于英文的支持没有任何问题。但是,对于中文的支持则是有好有坏。本文将基于主流的开源大模型进行分析,介绍当前支持中文的开源大模型,并对其使用方式和主要能力进行总结。
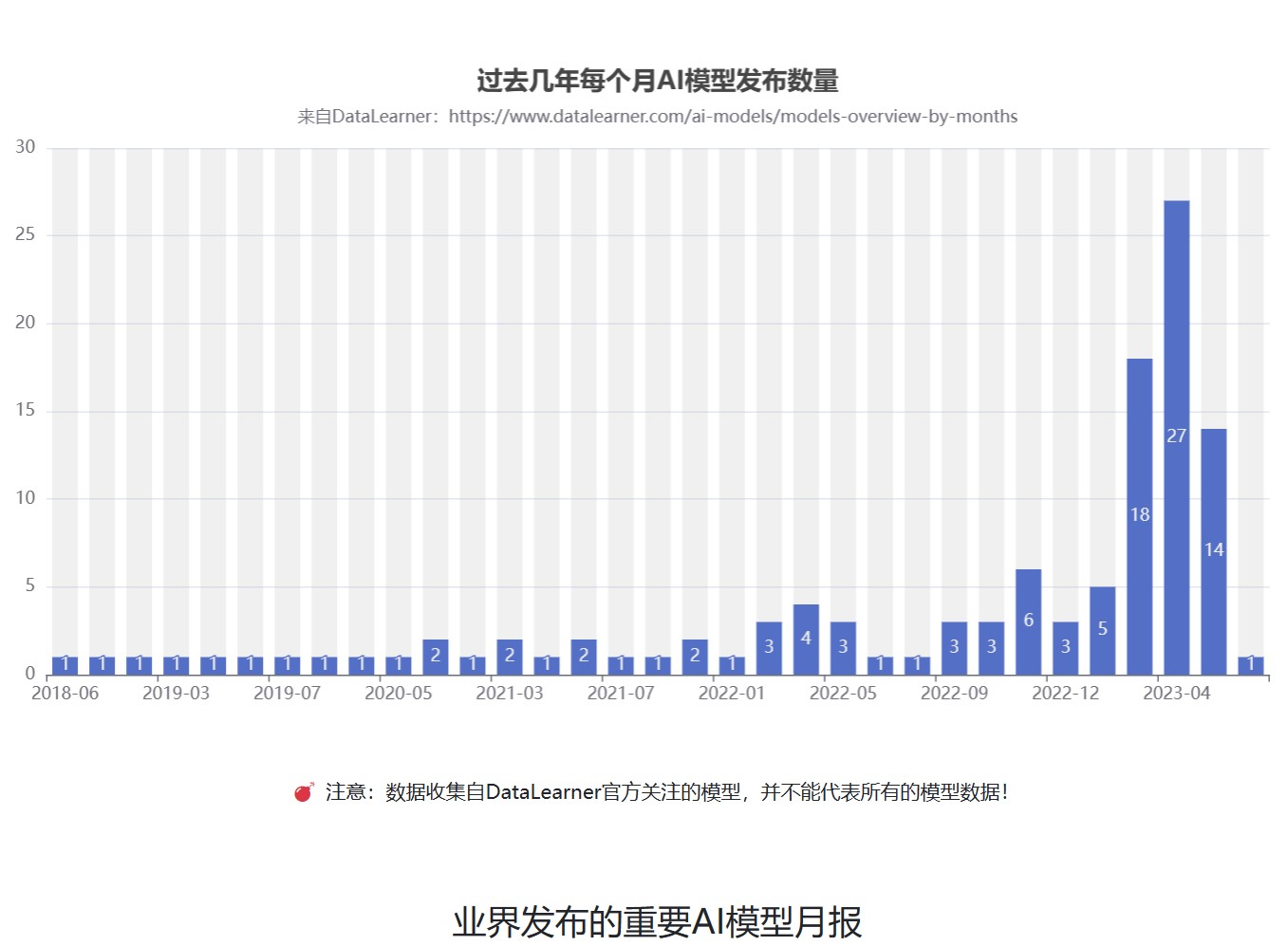
上图是DataLearner收集的每个月发布的大模型统计,可以看到,2月份之后大模型的发布数量增长很快。不过需要注意的是,这些模型仅仅来自DataLearner官方关注的模型,并不能代表所有的模型数据!详情参考:https://www.datalearner.com/ai-models/models-overview-by-months
一、MetaAI开源的OPT - Open Pre-trained Transformer模型
MetaAI是大语言模型开源领域的重要贡献者。早在2022年5月份,他们就按照GPT-3的水平开源了业界最早的大规模语言模型,即OPT - Open Pre-trained Transformer。该系列模型最高的参数规模为1750亿。
OPT模型本身并没有特意针对多语言进行训练,不过他们的数据集很大,因此也能在简单的中英文翻译中获得不错的结果。这也是早期支持中文的大模型,不过由于OPT太早了,现在用的人不多。
OPT的开源协议也是不允许商用。
OPT在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/OPT
二、Google开源的Flan-T5系列
Flan-T5是谷歌AI团队提出的基于思维链微调的大语言模型,相比较传统的微调方法,基于思维链微调的预训练模型要好很多。
Flan-T5是Google从另一种方式尝试的自然语言大模型的路径。Google通过几种方式推进了指令微调。目前,Flan-T5开源了很多个模型,最大的一个参数110亿。开源协议为Apache2.0,可以商用哦~
Flan-T5支持很多50种语言,包括中文! Flan-T5在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/flan-t5
三、BigScience开源的BLOOM大模型
BigScience在2022年12月发布了BLOOM,一个由数百名研究人员合作设计和构建的1760亿参数的开放式语言模型。BLOOM是一个仅解码器的Transformer语言模型,它是在ROOTS语料库上进行训练的,该语料库包含46种自然语言和13种编程语言。
BLOOM完全开源,对模型的重用、分发和商用均没有限制,只要你不用它生成不好的用例,所谓不好的用例大家应该可以理解。
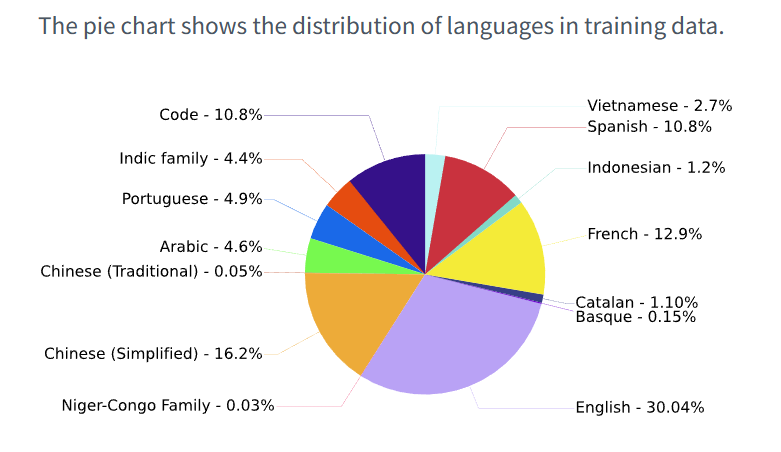
BLOOM的训练语料第一大语言是英语,占比30.4%,其次就是中文,占比16.2%。所以它是支持中文的。 BLOOM在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/bloom
四、复旦大学的MOSS系列
MOSS是复旦大学邱锡鹏教授开源的一个大语言模型,由于其良好的意图识别能力和多轮对话能力,被大家所关注。2023年2月20日早期版本和演示环境一经发布就吸引了大批的用户,造成环境的崩溃。
2023年4月21日,MOSS正式开源。MOSS包含6个版本:
不多说,咱们自己的模型,当然支持中文! MOSS在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/MOSS
五、MetaAI最著名的开源模型LLaMA
LLaMA全称是Large Language Model Meta AI,是由Meta AI(原FacebookAI研究实验室)研究人员发布的一个预训练语言模型。该模型最大的特点就是基于以较小的参数规模取得了优秀的性能。根据官网提供的信息,LLaMA的模型包含4个版本,最小的只有70亿参数,最大的650亿参数,但是其性能相比较之前的OPT和1750亿参数的GPT-3都是非常由有竞争力的。
LLaMA是目前很多开源大模型的基础。它支持中文,虽然很有限。
不过LLaMA模型虽然开源,但是不可以商用! LLaMA在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/LLaMA
六、LAION AI开源的OpenAssistant-LLaMA
OpenAssistant是由LAION AI开源的一个AI Chat模型,它的目的是为每个人提供一个访问大模型的机会。
OpenAssistant是一个基于聊天的助手,能够理解任务,可以与第三方系统交互,并动态地检索信息以执行任务。
它可以轻松地扩展和个性化,并作为免费的开源软件开发。
OpenAssistant LLaMA是基于MetaAI开源的LLaMA模型微调得到,目前依然在不断的训练中。显然,LLaMA支持中文,它也可以。需要注意的是,OpenAssistant也有基于Pythia的模型,那是不支持中文的!因为Pythia模型是一个仅支持英文的模型! OpenAssistant LLaMA在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/OpenAssistant-LLaMA
七、LM-SyS开源的vicuna系列
著名的南美“骆驼”系列模型,是由LLaMA模型微调得到的结果。这个系列最大的一个模型规模是130亿,名字为Vicuna-13B。
Vicuna模型是由多家研究机构合作开发的,包括UC Berkeley、CMU、斯坦福等。根据官方的描述,Vicuna模型是基于7万多个用户分享的与ChatGPT对话的数据进行微调得到的。官方的测试结果显示,vicuna-13b可能是目前最好的开源大模型。
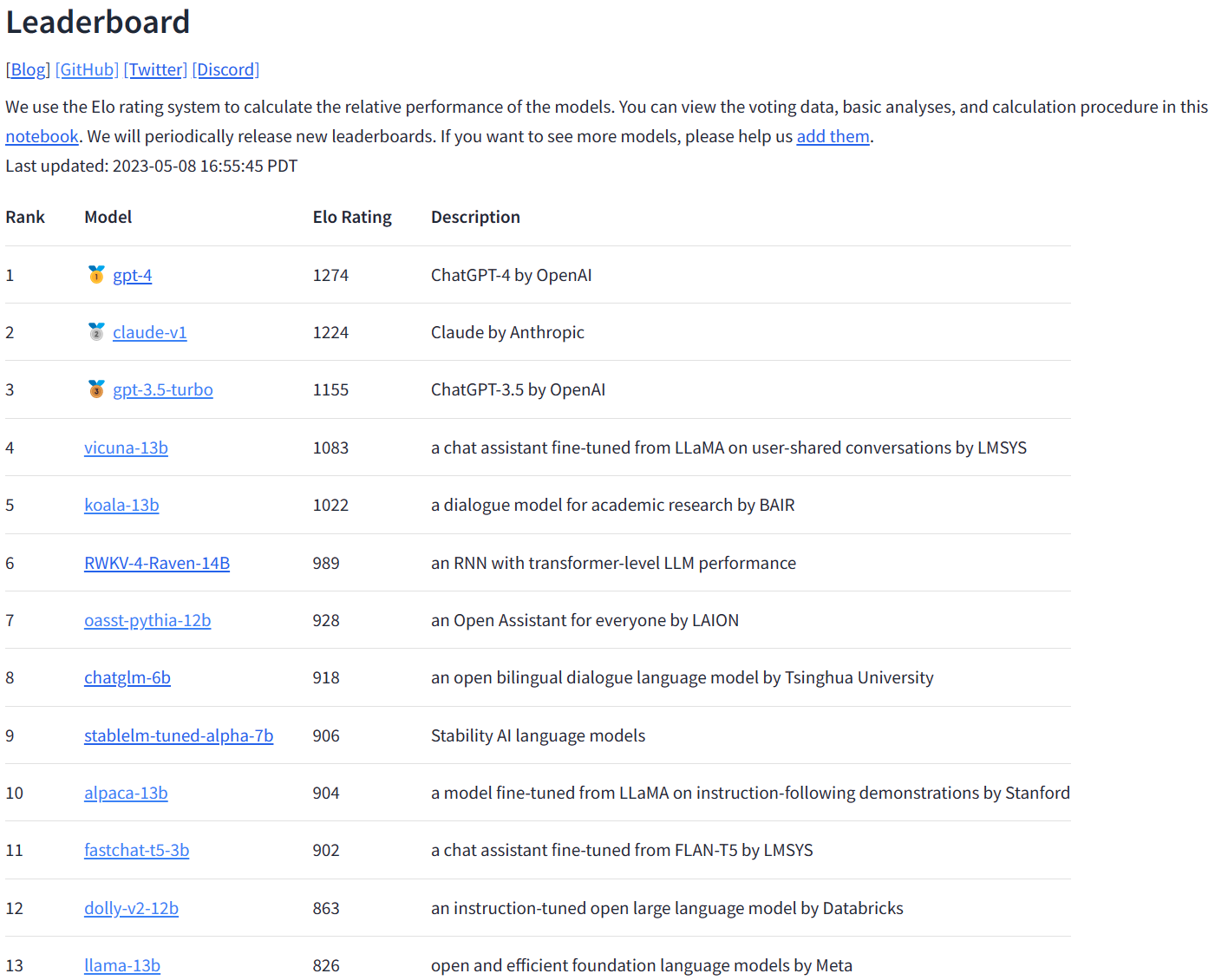
这份Leaderboard是由LM-SyS做的一个匿名投票得到的。用户可以同时对2个匿名模型发起对话,然后选择满意的那个,这是5月第一周的数据。
不过,受限于LLaMA的开源协议和OpenAI的限制,Vicuna系列开源,但是不可以商用! Vicuna-13B在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/Vicuna-13B
八、Databricks开源的Dolly
Dolly是由Databricks公司发布的一个低成本的大型语言模型(LLM),具有与ChatGPT相似的惊人的指令跟随能力。而Alpaca团队的工作表明,最先进的模型可以被引导出高质量的指令跟随行为,而Databricks发现即使是早期架构的开源模型,只要在少量的指令训练数据上进行微调,也能展现出引人注目的行为。
Dolly有2个版本,v1是基于vicuna模型微调得到的,v2模型则是基于pythia模型得到的。前者不可商用,后者可以。当然,dolly2个版本都支持中文,只不过它在各项测试中都比较糟糕~~
Dolly在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/Dolly Dolly v2在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/dolly-v2
九、多模态大模型MiniGPT-4
MiniGPT-4是一个可以理解图片的大语言模型,是由开源的预训练模型Vicuna-13B与BLIP-2结合得到。
MiniGPT-4是分两个阶段训练的。
- 首先是使用500万个图像-文本数据训练,在4个A100上训练了10个小时左右,不过这个阶段的模型的生成能力受到了严重的影响,因此还有第二个阶段;
- 第二个阶段是通过模型本身和ChatGPT一起创建高质量的图像文本对,这是一个小而高质量的数据集(共计3500个对)。然后在对话模板中使用这个数据集进行训练,显著提高了其生成可靠性和整体可用性;但是这个阶段的微调效率很高,一个A100在大约7分钟内就可以完成。
研究发现,MiniGPT-4具有许多与GPT-4类似的功能,比如生成详细的图像描述和从手写草稿创建网站。MiniGPT-4还有其他新兴功能,包括根据给定的图像撰写故事和诗歌,提供解决图像中显示的问题的方法,以及基于食品照片教用户如何烹饪等。
MiniGPT-4支持中文:
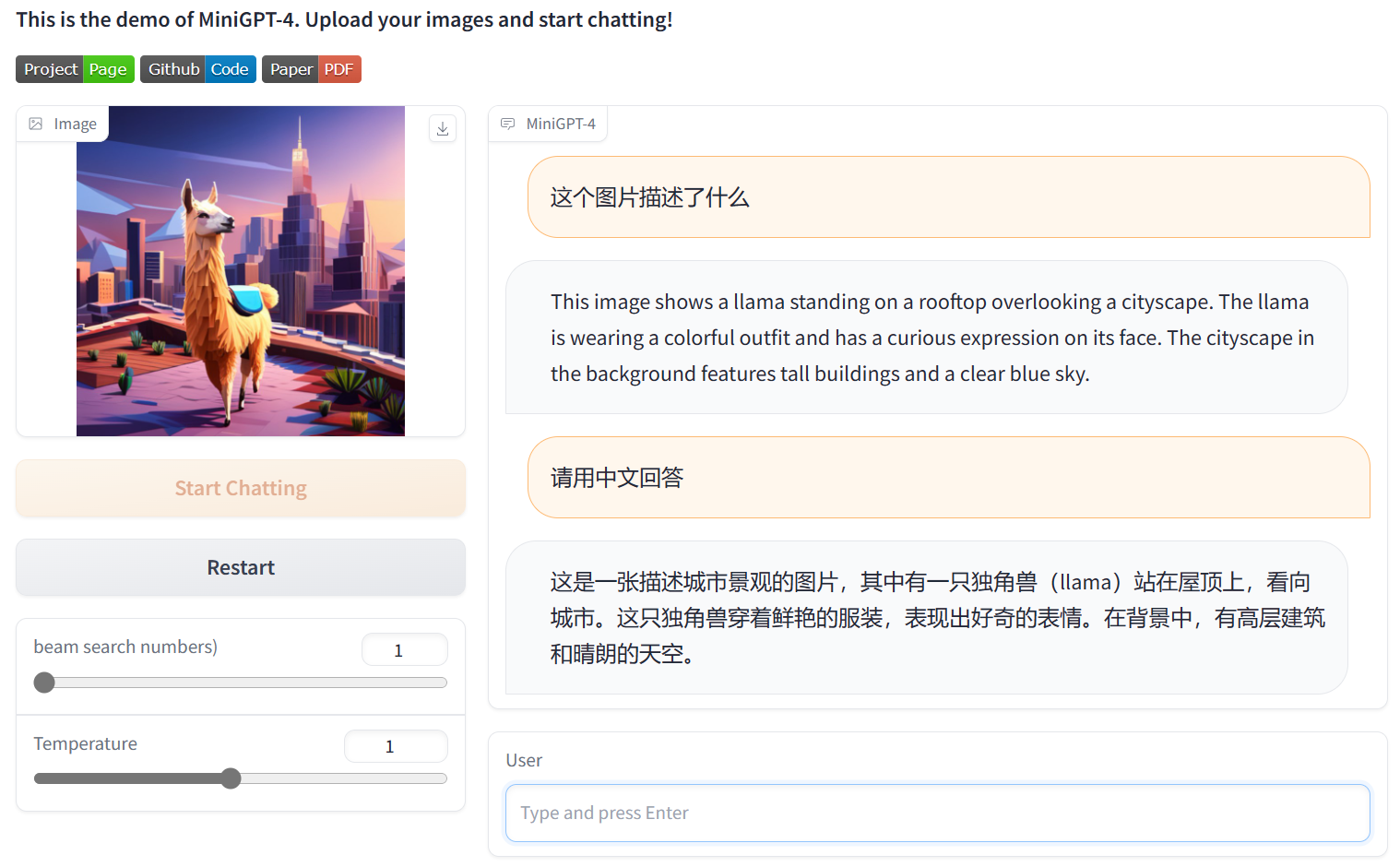
MiniGPT-4在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/MiniGPT-4
十、StabilityAI发布的StableLM和StableVicuna
是的,这就是开源了著名的图片生成模型StableDiffusion背后的公司开源的语言模型。
StableLM也是基于Pile数据训练的,只是利用的是一个新的Pile数据集,比原始数据集大三倍,包含1.5万亿tokens。数据集目前没有公开,但是官方说后续在适当的时机会公布。模型训练的context长度是4096个。目前,StableLM背后的架构没有公布,技术报告还没发布,但据猜测应该是与GPT-NeoX有着联系。
StableVicuna是StabilityAI的另一个尝试,是基于vicuna模型微调的结果。
这两个模型都支持中文,需要注意的是只有StableLM-Base-Alpha支持可以商用,StableLM-Tuned-Alpha与StableVicuna都是不可以商用的。
StableLM在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/StableLM StableVicuna在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/StableVicuna-13B
十一、开源可商用的MPT系列
MPT全称MosaicML Pretrained Transformer,是由MosaicML推出的transformer大模型。是基于1万亿tokens的文本和代码训练的。这是一个完全开源且允许商用的模型:
MPT系列主要的特点是:
- 有商用许可
- 基于大量的数据训练
- 目标是解决长输入(最高支持65K的输入,84K的处理)
- 训练与推理速度的优化
- 高效的开源训练代码
MPT应该是一个从头开始训练的模型,不受之前的开源协议约束。从这些特点看,MPT真的是一个很优秀的开源大模型,且官方宣称它的评测结果与LLaMA-7B差不多,目前已经开源70亿参数规模的MPT-7B。
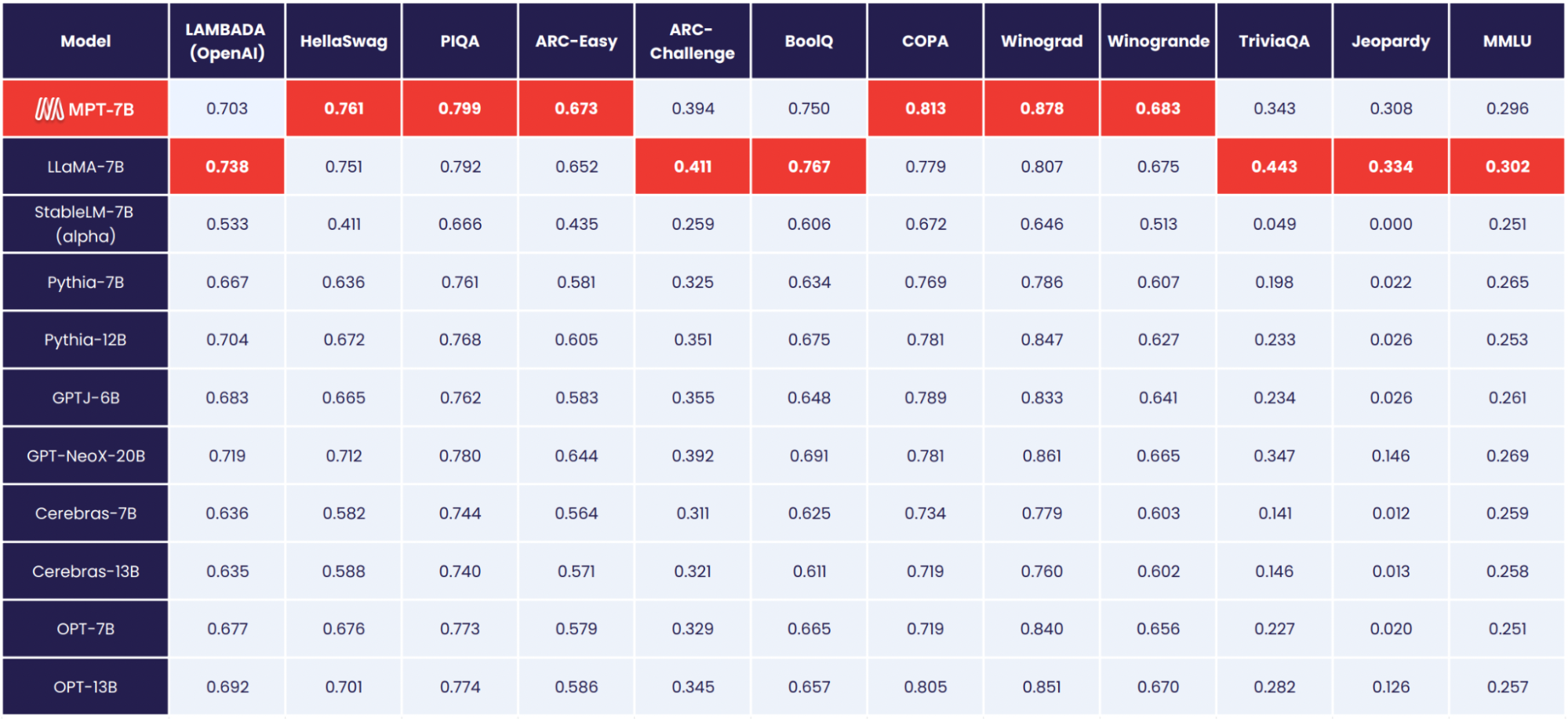
MPT-7B在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/MPT-7B
十二、清华大学的ChatGLM-6B和VisualGLM-6B
ChatGLM-6B是清华大学知识工程和数据挖掘小组(Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University)发布的一个开源的对话机器人。因其良好的性能和较低的部署成本,在国内受到了广泛的关注和好评。
而前几天,THUDM开源了ChatGLM-6B的多模态升级版模型VisualGLM-6B。这是一个多模态对话语言模型,支持图像、中文和英文。
不多说,和MOSS一样,自己的模型,中文支持相当可以:
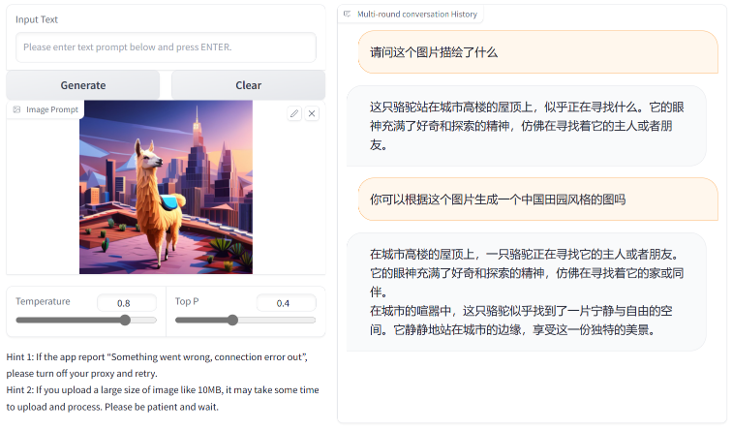
ChatGLM-6B在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai-resources/pretrained-models/ChatGLM-6B VisualGLM-6B在DataLearner上的AI模型信息卡地址:https://www.datalearner.com/ai/pretrained-models/VisualGLM-6B
十三、基于RNN架构的RWKV-4-Raven-14B
RWKV是一个结合了RNN与Transformer双重优点的模型架构。由香港大学物理系毕业的彭博首次提出。简单来说,RWKV是一个RNN架构的模型,但是可以像transformer一样高效训练。上周,HuggingFace官方宣布在transformers库中首次引入RNN这样的模型,足见RWKV模型的价值。
同时,在LM-Sys官方的匿名模型battle中,目前RWKV-4-Raven-14B排名第六,仅次于Koala-13B,好于Oasst-Pythia-12B,也能看到普通用户对其的认可。
RWKV支持中文,且开源可商用。
总结
业界开源的大模型很多,但是英文还是最主流的模型。尽管如LLaMA、Vicuna、MPT等国外机构开源的模型支持中文,但是本土的ChatGLM、MOSS、RWKV等系列在中文指令跟随和理解中通常更加优秀。而这些模型可能是未来国内开源的中坚力量。此外,国内商业公司发布的大模型如百度的文心一言、科大讯飞的讯飞星火、华为的盘古等主要面向的可能更多是B端的客户,也没有开源细节,因此不做参考。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
