使用R语言进行K-means聚类并分析结果
R语言内置了一个kmeans函数,在这篇博客中,我们描述一下如何使用这个函数做聚类分析。首先,我们给出kmeans函数的参数:
kmeans(x, centers, iter.max = 10, nstart = 1,algorithm = c("Hartigan-Wong", "Lloyd", "Forgy","MacQueen"), trace=FALSE)
## S3 method for class 'kmeans'
fitted(object, method = c("centers", "classes"),...)
我们将分别描述,首先第一个参数是 x,它是kmeans的输入数据。只要是矩阵的数值数据就可以了。首先,我们使用R语言自带的数据集iris数据(点击查看)。
data(iris)
head(iris)
我们可以看到数据集格式如下:
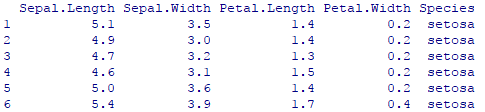
第二个参数是中心点选择 centers,它是中心点选择,可以有两种参数,第一种直接写一个数值,表示聚成几类,这种情况下它会自动随机选择初始中心点,R语言会选择数据集中的随机行作为初试中心点。还有一种方式是可以选择输入一个起始的中心点,那么kmeans就会根据选择的中心点开始聚类迭代。
第三个参数是迭代次数 iter.max,即迭代次数,不写的话默认是10次。否则就是最大迭代次数。
第四个参数是算法选择 algorithm,输入值是缩写的字符,算法有"Hartigan-Wong", "Lloyd", "Forgy","MacQueen"四种,注意Lloyd和Forgy是同一种算法的不同称谓。
剩下的参数没什么意义,暂时不说了。接下来我们看一下实际案例及结果。代码如下:
#载入数据
data(iris)
#选择第1列到第4列数据进行聚类,因为第5列是该数据集的类标签
km <- kmeans(iris[,1:4], 3)
#对结果的可视化
plot(iris[c("Sepal.Length", "Sepal.Width")], col = km$cluster, pch = as.integer(iris$Species))
points(km$centers[,c("Sepal.Length", "Sepal.Width")], col = 1:3, pch = 8, cex=2)
#输出kmeans结果,我们分析一下
km

kmeans的可视化结果
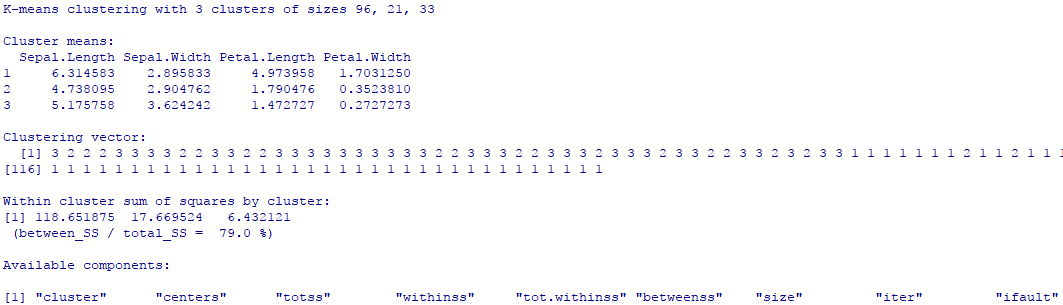
kmeans结果的分析
我们分析一下结果,第一行表示各个类别下数据点的数量分别是96、21和33个。然后是聚类的均值,即聚类的中心点。然后是聚类向量,表明每个数据点所属的类别。Within cluster sum of squares by cluster表示每个簇内部的距离平方和,表示该簇的紧密程度。between_SS / total_SS这一项表示组间距离的平方和占整体距离平方和的结果。一般的,组内距离要求尽可能小,组间距离尽可能大,因此这个值越接近1越好。最后的Available components表示运行结果返回的对象包含的组成部分。可以使用 km$cluster形式打印出来查看结果。
关于R语言中KMeans评价的说明
在R语言的KMeans中内置了一个评价指标,是组间平方和与总的距离平方和的商:即上文中提到的between_SS / total_SS(这里的ss是sum of squares的缩写)。这里说明一下相关的计算方法。
总的距离平方和是指所有的数据与均值之间的差值,然后计算平方和:
\text{total\_ss} = \sum_{x_i} (x_i - \mu)^2
而组间平方和则是总的距离平方和减去组内距离平方和,所以这里先计算组内距离平方和,这是指每个簇内部的距离平方和,然后求总和:
\text{within\_ss} = \sum_k\sum_{x_i \in c_k}(x_i - \mu_k)^2
最终:
\text{between\_ss} = \text{total\_ss} - \text{within\_ss}
这个指标的计算可以使用python,见使用Python的sklearn包做kmeans聚类分析
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
