Java爬虫入门简介(三) —— Jsoup解析HTML页面
5,173 阅读
上一篇博客我们已经介绍了如何使用HttpClient模拟客户端请求页面了。这一篇博客我们将描述如何解析获取到的页面内容。
上一节我们获取了 http://www.datalearner.com/blog_list 页面的HTML源码,但是这些源码是提供给浏览器解析用的,我们需要的数据其实是页面上博客的标题、作者、简介、发布日期等。我们需要通过一种方式来从HTML源码中解析出这类信息并提取,然后存到文本或者数据库之中。在这篇博客中,我们将介绍使用Jsoup包帮助我们解析页面,提取数据。
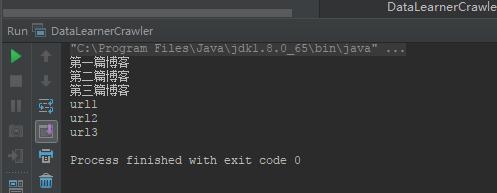
Jsoup是一款Java的HTML解析器,可以直接解析某个URL地址,也可以解析HTML内容。其主要的功能包括解析HTML页面,通过DOM或者CSS选择器来查找、提取数据,可以更改HTML内容。Jsoup的使用方式也很简单,使用Jsoup.parse(String str)方法将之前我们获取到的HTML内容进行解析得到一个Documend类,剩下的工作就是从Document中选择我们需要的数据了。举个例子,假设我们有个HTML页面的内容如下:
<html>
<div id="blog_list">
<div class="blog_title">
<a href="url1">第一篇博客</a>
</div>
<div class="blog_title">
<a href="url2">第二篇博客</a>
第三篇博客