集成学习(Ensemble Learning)简介及总结
一、基本思想
**集成学习(Ensemble Learning)**是解决有监督机器学习任务的一类方法,它的思路是基于多个学习算法的集成来提升预测结果。
通常情况下,有监督的学习方法都是针对一个问题从一个有限的假设空间中搜索最适合结果。这里就包含了两个问题,一个是假设空间中是否包含了合适的方案,另一个是假设这个方案存在,模型是否可以搜寻到。而集成学习就是将多个假设空间放到一起来形成一个更好的方案。
集成学习的结果是一个单一的假设空间,不一定是在原始分类器的假设空间中,因此具有更高的灵活性。理论上说,集成学习可以在训练集上比单一的模型有更好的拟合能力,而某些集成学习方法(如bagging)在实际中也能更好地降低过拟合的问题。集成学习也会给予分类性能好的分类器更高的权重。
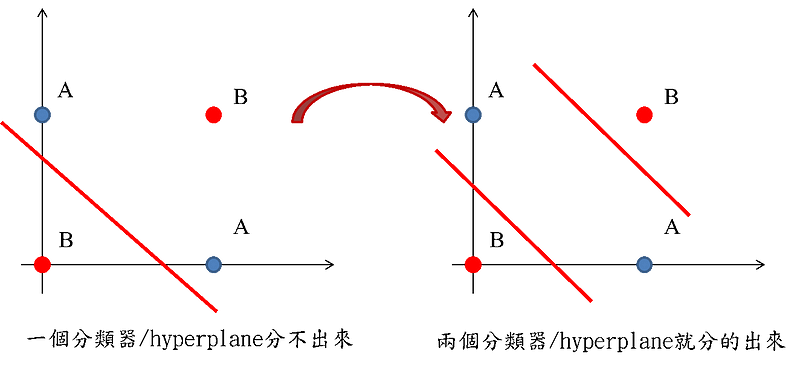
如上图所示,单个线性分类器可能无法分割上述数据,但是两个线性分类器就可以了。这是集成学习一个简单的举例。
二、集成学习的分类
集成学习的集成方式分成两种,一种是串行(squential ensemble),一种是并行(parallel ensemble)。
串行集成的意思是基分类器以串行的方式连接,它的动机是为了探索基分类器之间的依赖关系,通过对前一个错分的数据提高权重来提升性能。串行的集成学习方法的过程一般是对整个训练集使用一个基分类器训练,然后将基分类器表现不好的样本提升权重,再使用第二个基分类器进行训练在,直到训练到指定的第$T$个基分类器。
而并行集成的方法利用基分类器之间的独立性,通过基分类器之间的加权投票得到最终结果。因此,并行集成下的基分类器需要有较大的差异性,否则无法有效提升预测性能(因为大家都差不多,投票也没意义)。因此,并行集成方法首先将训练数据随机切分成$M$块,然后每一块训练集使用$T$个基分类器训练,最终加权投票得到最终结果。
集成学习有几种不同的类型: 贝叶斯优化 bagging boosting stacking
三、集成学习方法的参数数量影响
Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成;Bagging主要关注降低方差,因此它在不剪枝的决策树、神经网络等学习器上效用更为明显。
对于Bagging算法来说,由于我们会并行地训练很多不同的分类器的目的就是降低这个方差,所以需要更多关注单个分类器的偏差问题,那么单个分类器需要较深的树或者不剪枝的树来提高其精度。而对于Boosting来说,每一步我们都会在上一轮的基础上更加拟合原数据,所以可以保证偏差(bias),所以对于每个基分类器来说,问题就在于如何选择variance更小的分类器,即更简单的分类器,所以我们选择了深度很浅的决策树。
这也是导致了xgboost/gbdt在调参时为什么树的深度很少就能达到很高的精度的原因。参考:为什么xgboost/gbdt在调参时为什么树的深度很少就能达到很高的精度?
有一个解释也很有意思:
你自己不都说了吗,一个是随机bagging,一个是boosting。bagging就是大家都是学渣,每道题都由随机选出的一群学渣投票决定,这样需要的学渣比较多,而且每个学渣还都得很努力学习。boosting也是一群学渣,但每个人虽然总分菜,却是因为偏科导致的,每个学渣都贡献自己最擅长的那个题目。这样boosting需要的每个学渣都豪不费力,但是整体上更强了。xgb的学渣还通过预习,让自己偏科的科目学得更省力。所以整体上xgb看起来是非常省力的一群学渣组成,但是拿到的分数却很高。 作者:张馨宇 链接:https://www.zhihu.com/question/45487317/answer/99014746 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
四、集成学习基分类器数量的影响
集成学习的基分类器的数量对结果影响很大,但是目前很少有相关的研究。实际表明,基分类器的数量在增长到一定程度之后带来的提升很小。最近也有一些研究认为存在一个完美的集成数字是的模型取得最优的效果。他们的理论显示使用和分类标签一样多的集成数量会有最优的准确率。
来源:
R. Bonab, Hamed; Can, Fazli (2016). A Theoretical Framework on the Ideal Number of Classifiers for Online Ensembles in Data Streams. CIKM. USA: ACM. p. 2053.
R. Bonab, Hamed; Can, Fazli (2017). Less Is More: A Comprehensive Framework for the Number of Components of Ensemble Classifiers (PDF). TNNLS. USA: IEEE.*
集成学习需要注意几个点: 1、被集成的分类器需要有较大的差异性,差异性过小的分类器被集成没有意义。 2、单个弱分类器的精度最好略高于0.5,随着集成规模的增加,低于0.5的弱分类器会导致分类准确率不断下降,而高于0.5则会导致模型的准确率趋向于1。
五、GBDT和随机森林对比
- Random Forest: Bagging + Decision tree
- Boosting Tree: AdaBoost + Decision tree
- GBDT: Gradient Boost + Decision tree
相同点:1.都是由多棵树组成;2.最终的结果都是由多棵树一起决定;
不同点:1.随机森林的子树可以是分类或回归树,而GBDT只能是回归树;2.随机森林可以并行生成,而GBDT只能是串行;3.输出结果,随机森林采用多数投票,GBDT将所有结果累加起来;4随机森林对异常值不敏感,GBDT敏感;5:随进森林减少方差,GBDT减少偏差;6:随机森林对数据集一视同仁,GBDT是基于权值的弱分类器的集成。
GBDT和随机森林哪个容易过拟合? 随机森林,因为随机森林的决策树尝试拟合数据集,有潜在的过拟合风险,而boostingd的GBDT的决策树则是拟合数据集的残差,然后更新残差,由新的决策树再去拟合新的残差,虽然慢,但是难以过拟合。
六、对于集成学习中“弱分类器”的理解
并不是所有的集成学习都是必须要求弱分类器的。首先在并行的集成学习中,集成的结果使得方差较小,因此主要的目标是降低基分类器的偏差,因此基分类器需要强一些。 在串行的集成学习中(boosting)基分类器过强可能会导致收敛困难(比如说一些运气刚好预测对的结果在下一次迭代中就会预测出纯粹的噪音进而降低性能),但通常会在后续的迭代中修复。 使用弱分类器的一个原因是通常弱分类器相对而言比较简单,因此集成学习的一个目标是将多个不同的简单的训练速度快的分类器结合产生一个好的分类器。如果有一个强分类器,但是使用集成学习计算代价很大,那么也许没有意义。 强和弱的定义其实取决于集成之后计算的复杂度以及提升的程度。 此外,如果你有一个很强的分类器,实际上也不需要使用集成方法了。
七、模型的选择依据
没有一个完美的方案。这取决于数据、情景等各种因素。Bagging和Boosting减少了单个模型估算的方差,因为它们结合了不同模型的多个估算值。 因此结果可能是具有更高稳定性的模型。
如果问题是单个模型的性能非常低,Bagging很少会有更好的偏差能力。但是,Boosting可以生成具有较低错误的组合模型,因为它优化了过拟合并减少了单个模型的缺陷。
相比之下,如果单个模型的过度拟合,那么Bagging是最佳选择。 提升其作用无助于避免过度拟合; 事实上,这种技术本身就面临着这个问题。 因此,Bagging比Boosting更有效。
参考资料:
機器學習: Ensemble learning之Bagging、Boosting和AdaBoost 机器学习总结(六):集成学习(Boosting,Bagging,组合策略) On the “strength” of weak learners 集成学习简介 Ensemble Learning to Improve Machine Learning Results
