深度学习的标准符号表示
注:深度学习的网络结构可以理解为多层的神经网络,本篇博客并不强调二者的区别,某些地方用词可以互换。
深度学习中的符号很多,但是大多数情况下,大家都使用同一套符号来表示。这篇博客主要以一个简单的神经网络为例,说明深度学习的标准符号以及相关的维度表示。主要来源是吴恩达的coursera课程——Neural Networks and Deep Learning。
以下图为例,这是一个标准的神经网络结构图。
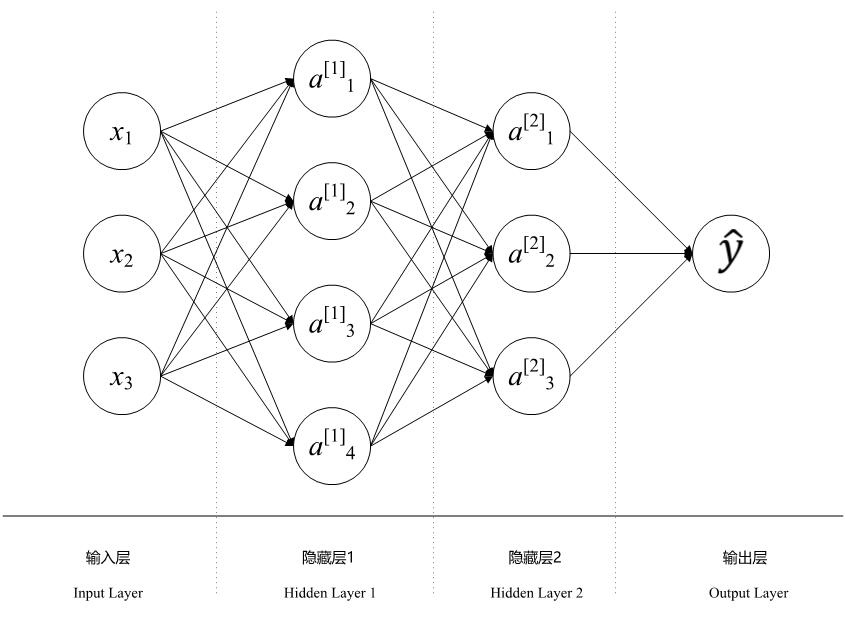
首先,我们说明一下一些通用的规则。小括号的上标如$(i)$表示训练集中的第$i$个数据,而方括号的上标如$[l]$则表示第$l$层。另外,在数深度学习层的时候,通常是只计算包含参数的层,因此,对于包含池化层的卷积神经网络来说,一般不把池化层计算在内。输入层也不当做单独的层计算。因此,对于上述神经网络来说,其层数$L=3$。
标准符号:
维度相关:
$m$:数据集中训练集的数量。 $L$:神经网络中的层数,上图$L=3$。 $l$:第$l$层的神经网络。 $n_x$:输入数据的维度,上图$n_x=3$。 $n_y$:输出数据的维度,通常就是分类问题中的类标签的数量。 $n_h^{[l]}$:第$l$层的隐藏单元的数量,如上图第二层中$n_h^{[2]}=3$。
数据相关
$X \in R^{n_x\times m}$:这是输入数据的矩阵,它的维度是$(n_x, m)$。 $x^{(i)} \in R^{n_x}$:第$i$个数据,一般是一个列向量,它的维度是$(1,n_x)$。 $Y \in R^{n_y\times m}$:标签矩阵,它的维度是$(n_y, m)$。 $y^{(i)} \in R^{n_y}$:第$i$个数据对应的标签,一般是一个整数值。 $W^{[l]}$:第$l$层的权重矩阵,其维度是$(n_h^{[l]},n_h^{[l-1]})$。 $b^{[l]}$:第$l$层的偏差向量,是一个列向量,其维度是$(1,n_h^{[l]})$。 $\hat{y} \in R^{n_y}$:预测的输出向量,列向量,它的维度是$(1,n_y)$。
前馈计算 对于每一个隐藏层中的每个隐藏单元来说,计算都分两个步骤,第一个步骤是前一层的输入单元的线性加权求和$z$,第二个步骤是对这个求和结果使用激活函数计算,得到该隐藏单元的最终结果$a=g(z)$。这里的$g(\cdot)$是激活函数。还是以之前的例子为例,对于隐藏层1的第一个隐藏单元来说,其计算示意图如下:

假设网络是全连接的,那么所有的输入参数都会被计算得到第一个隐藏层的第一个隐藏单元,每个输入单元与这个隐藏单元之间连接的边的权重用$w$表示(也就是上面说的权重矩阵的一个值),第$l$层第$j$个隐藏单元的输出计算的表示如下:
z_j^{[l]} = \sum_kw_{jk}^{[l]}a_k^{[l-1]}+b_j^{[l]}
a^{[l]}_j = g^{[l]}(\sum_kw_{jk}^{[l]}a_k^{[l-1]}+b_j^{[l]})
第$l$层的矩阵的形式如下:
z^{l}=W^{[l]} a^{[l-1]} + b^{[l]}
a^{[l]} = g^{[l]}(z^{[l]})
其中,$a^{[l-1]}$是上一层的输出,在上图的例子中就是当前的输入数据了,即$a^{[0]} = x^{(i)}$,$W^{[l]}$是第$l$层的权重矩阵,$b^{[l]}$是第$l$层的偏差向量。$g^{[l]}(\cdot)$是第$l$层的激活函数。
