Java爬虫入门简介(一) —— HttpClient请求
使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。包括HttpClient 4.3及以上版本的Header设置,请求参数设置等。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。包括HttpClient 4.3及以上版本的Header设置,请求参数设置等。
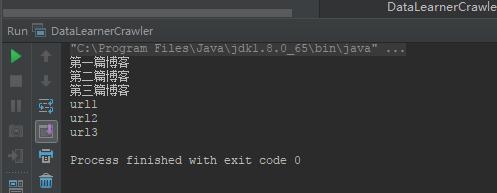
使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。在这篇博客里,我们将简单介绍Jsoup解析HTML页面的操作。

使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。包括HttpClient 4.3及以上版本的Header设置,请求参数设置等。
在使用HttpClient作为客户端请求数据的时候,我们常常需要以一个用户的身份多次请求一个网站内的多种资源。例如,我一次登录后,后面希望以这个身份继续访问不用重新登录。这里就可以使用cookie了。
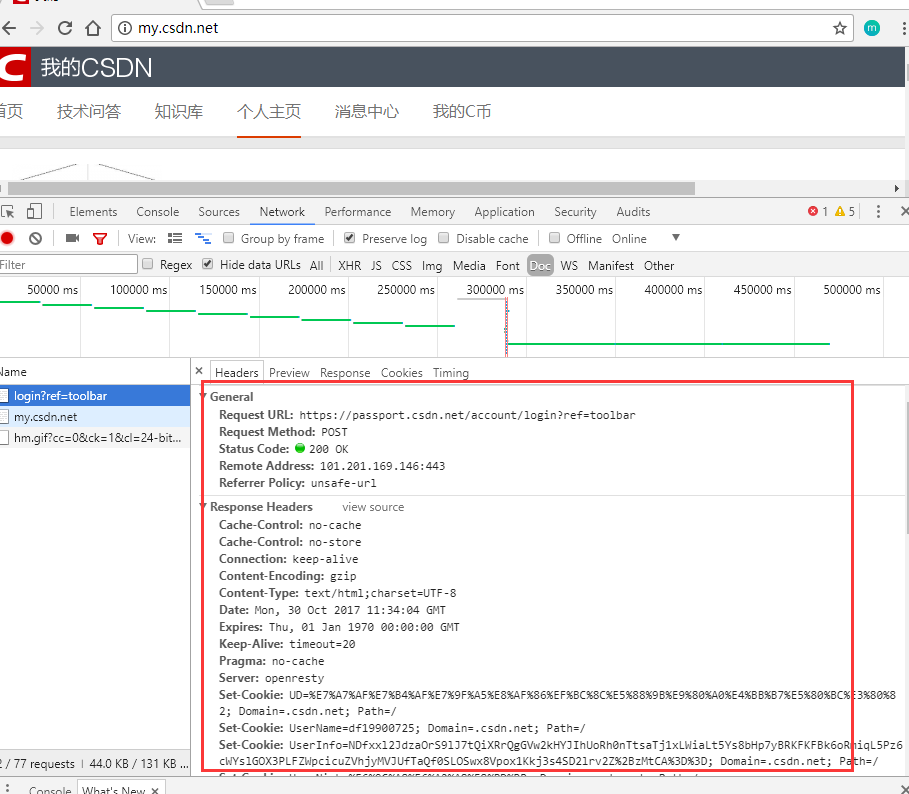
网络爬虫需要解决的一个重要的问题就是要针对某些需要用户名和密码访问的页面可以模拟用户自动登录。在这一篇博客中我们将介绍如何使用Chrome浏览器自带的抓包工具分析页面并模拟用户自动登录
学爬虫先学思想,思想掌握了,对应代码学习技术就so easy了~
Java多线程网络爬虫(时光网为例)
Scrapy网络爬虫实战[保存为Json文件及存储到mysql数据库]
python中Scrapy的安装详细过程
python中Scrapy的安装详细过程
网络爬虫模拟登陆获取数据并解析实战
基于java的网络爬虫框架
网络爬虫中的模拟登陆获取数据

网络爬虫中Json数据的解析
网路爬虫数据库操作
网络爬虫之基础java集合操作篇
网络爬虫需要掌握的基础知识
网络爬虫指按照一定的规则(模拟人工登录网页的方式),自动抓取网络上的程序。
网络爬虫
HttpClient的使用方法案例 爬虫