
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



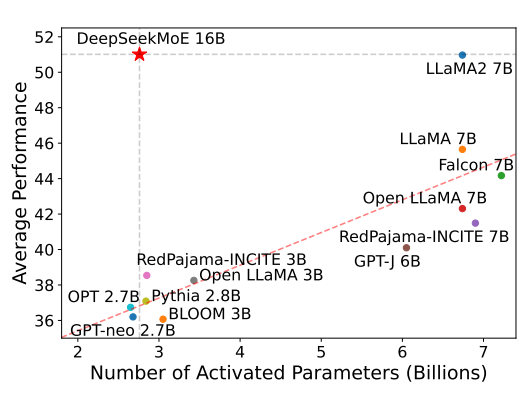
混合专家(Mixture of Experts)是大模型一种技术,这个技术将大模型划分为不同的子专家模型,每次推理只选择部分专家网络进行推理,在降低成本的同时保证模型的效果。此前Mistral开源的Mixtral-8×7B-MoE大模型被证明效果很好,推理速度很棒。而幻方量化旗下的DeepSeek刚刚开源了可能是国产第一个MoE技术的大模型,DeepSeek-MoE 16B。
今日推荐
截止目前可能是全球最快的大语言模型推理服务:实机演示Groq公司每秒500个tokens输出的450亿参数的Mixtral 8×7B模型
回归模型中的交互项简介(Interactions in Regression)
PandasTutor——一个用于可视化pandas操作的神器
检索增强生成(RAG)方法有哪些提升效果的手段:LangChain在RAG功能上的一些高级能力总结
好消息!3.11和3.12版本的Python将有巨大的性能提升!
重磅!ChatGPT加入多模态能力,可以听语音、生成语音并理解图片了!
Java爬虫入门简介(二) —— HttpClient详细使用方法
马斯克旗下xAI发布Grok-1.5,相比较开源的Grok-1,各项性能大幅提升,接近GPT-4!
重磅!阿里巴巴开源自家首个MoE技术大模型:Qwen1.5-MoE-A2.7B,性能约等于70亿参数规模的大模型Mistral-7B