
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



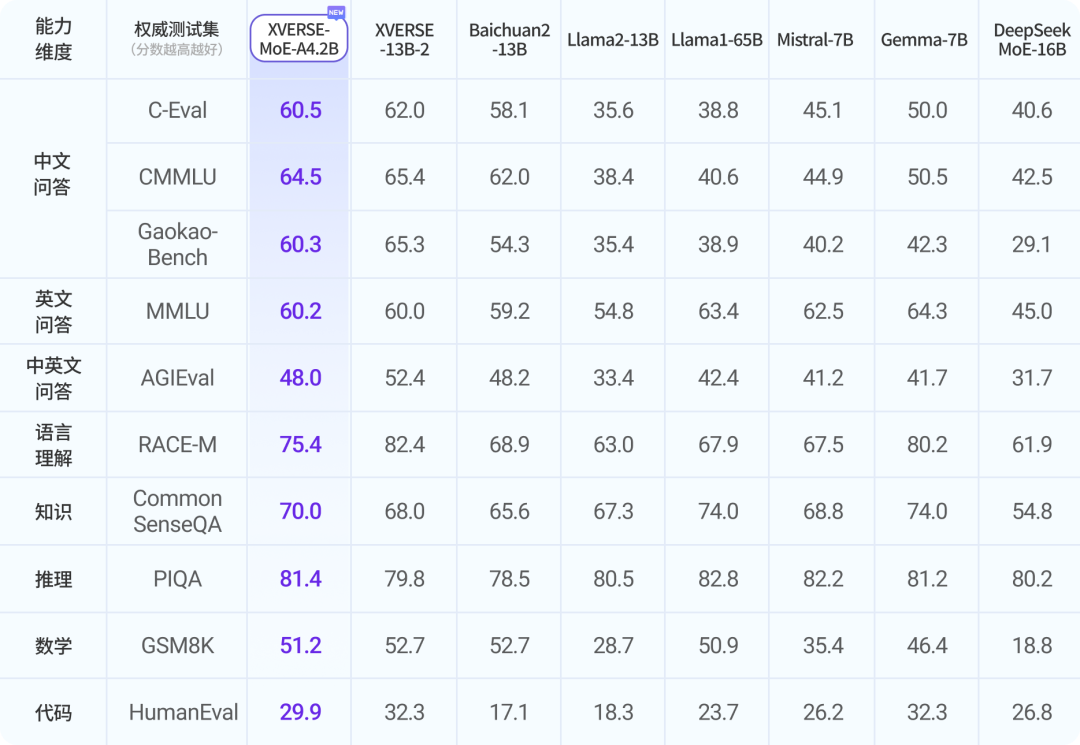
混合专家架构大模型是当前最火热的一个大模型技术发展方向。三月底,业界开源了多个混合专家大模型,包括DBRX、Qwen1.5-MoE-A2.7B等。而在四月初,又一家国产大模型企业开源了一个全新的MoE架构的模型,即深圳元象科技XVERSE开源的XVERSE-MoE-A4.2B。该模型参数256亿,推理时仅激活42亿参数,效果与当前主流的130亿参数的规模差不多。
今日推荐
大型语言模型的新扩展规律(DeepMind新论文)——Training Compute-Optimal Large Language Models
预训练模型编程框架Transformers迎来重磅更新:Transformers Agents发布,一个完全的多模态AI Agent!
康奈尔大学发布可以在一张消费级显卡上微调650亿参数规模大模型的框架:LLMTune
截止目前可能是全球最快的大语言模型推理服务:实机演示Groq公司每秒500个tokens输出的450亿参数的Mixtral 8×7B模型
简单几步教你如何在搭建并使用DALL·E开源版本来基于文字生成图片
大语言模型的开发者运维LLMOps来临,比MLOps概念还要新:吴恩达联合Google云研发人员推出免费的LLMOps课程