
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



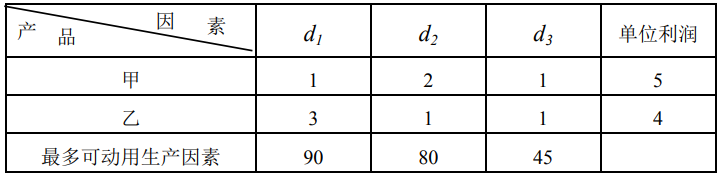

KKT条件(Karush–Kuhn–Tucker conditions)是求解带不等式约束的最优化问题中非常重要的一个概念和方法。这篇博客将解释相关概念和操作。
今日推荐
最像OpenAI的企业Anthropic的重大产品更新:GPT-4最强竞争模型Claude2发布!免费!具有更强的代码能力与更长的上下文!
开源领域大语言模型再上台阶:Databricks开源1320亿参数规模的混合专家大语言模型DBRX-16×12B,评测表现超过Mixtral-8×7B-MoE,免费商用授权!
比OpenAI原始的Whisper快70倍的开源语音识别模型Whisper JAX发布!
最新发布!基于推文(tweet)训练的NLP的Python库TweetNLP发布了!
GPT-4来了!微软德国CTO透露GPT-4将是多模态模型,并于下周发布!
DeepSeekAI开源国产第一个基于混合专家技术的大模型:DeepSeekMoE-16B,未来还有1450亿参数的MoE大模型
微软开源DeepSpeed Chat——一个端到端的RLHF的pipeline,可以用来训练类ChatGPT模型。
实际案例说明AI时代大语言模型三种微调技术的区别——Prompt-Tuning、Instruction-Tuning和Chain-of-Thought