用R做面板数据回归(包括静态和动态)
参考《Applied Econometrics with R》第三章第6节
1.Linear Regression with Panel Data
在过去二十年中,有关面板数据计量经济学相当热门,因此,几乎必须在R中简要讨论一些常见的规范。R包plm(Croissant和Millo 2008)包含相关的功能和方法。对于方法论背景,我们参考Baltagi(2005)。
1.Static linear models
为了说明基本的固定和随机效应方法,我们使用了众所周知的Grunfeld数据(Grunfeld 1958),其中包含11家大型美国公司20个年度(1935-1954年)的观察值,三个变量:实际总投资(投资),企业实际价值(实际值)和资本存量(资本)的实际价值。 最初在芝加哥大学博士论文中研究企业投资的决定因素。这些数据自20世纪70年代以来一直是经典教科书。随附的AER包提供了包括所有11家公司的完整数据集,该文档包含有关替代版本和错误的进一步详细信息。截面数据和面板数据之间的主要区别是面板数据具有内部结构,由二维阵列索引,必须传达给拟合函数。 我们将交叉对象称为“个体”,将时间标识符称为“时间”。我们使用三家公司的一部分进行说明,并使用plm.data()在R中指定个体标识符为”firm”,时间标识符为”year”.
library(plm)
library(AER)
#static linear models
# data
data("Grunfeld",package="AER")
#choose three company
gr=subset(Grunfeld,firm %in% c("General Electric","General Motors","IBM"))
# index:firm,year
pgr=plm.data(gr,index=c("firm","year"))
提前建立一个结构化的数据帧pgr,而不是通过调用plm(),直接指定index = c("firm","year") 稍后,可以使用汇总数据上的简单OLS.
#pooling model
gr_pool=plm(invest~value+capital,data=pgr,model="pooling")
基本的单向面板回归是:
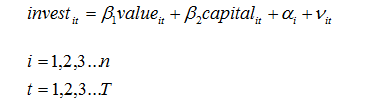
表示个体特定效果。 通过在转化后的模型中运行OLS来估计固定效果版本:
#within model
gr_fe=plm(invest~value+capital,data=pgr,model="within")
R> summary(gr_fe)
Oneway (individual) effect Within Model
结果:
Call:
plm(formula = invest ~ value + capital, data = pgr, model = "within")
Balanced Panel: n=3, T=20, N=60
Residuals:
Min. 1st Qu. Median 3rd Qu. Max.
-167.00 -26.10 2.09 26.80 202.00
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
value 0.104914 0.016331 6.4242 3.296e-08 ***
capital 0.345298 0.024392 14.1564 < 2.2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Total Sum of Squares: 1888900
Residual Sum of Squares: 243980
R-Squared: 0.87084
Adj. R-Squared: 0.86144
F-statistic: 185.407 on 2 and 55 DF, p-value: < 2.22e-16
Summary结果提供了每个企业的观察值列表,这里表明数据是平衡的。普通的回归输出与系数(不包括固定效应)和相关标准误差以及一些适合度的度量。 设定effect = "twoways"可以估计双向模式。如果需要检查固定效应,可以使用fixed()方法和与之相关的summary()方法。检查固定效应是否真的需要是有意义的。通过使用pFtest()比较固定效应和汇总的OLS拟合来完成.
R> pFtest(gr_fe,gr_pool)
结果:
F test for individual effects
data: invest ~ value + capital
F = 56.825, df1 = 2, df2 = 55, p-value = 4.148e-14
alternative hypothesis: significant effects
上述结果表明:存在实质的内部变化。 也可以在设置时使用model = "random"来拟合随机效应并选择一种用于估计方差分量的方法。回想一下随机效应估计器本质上是FGLS估计器,在所有变量“quasi-demeaning”之后利用OLS,其中quasi-demeaning变换的精确形式取决于random.method。有四种方法可用:Swamy-Arora,Amemiya, Wallace-Hussain, and Nerlove (see, e.g., Baltagi 2005). 默认的random.method="walhus"
#random model
gr_re=plm(invest~value+capital,data=pgr,model="random",random.method = "walhus")
R> summary(gr_re)
Oneway (individual) effect Random Effect Model
(Wallace-Hussain's transformation)
结果:
Call:
plm(formula = invest ~ value + capital, data = pgr, model = "random",
random.method = "walhus")
Balanced Panel: n=3, T=20, N=60
Effects:
var std.dev share
idiosyncratic 4389.31 66.25 0.352
individual 8079.74 89.89 0.648
theta: 0.8374
Residuals:
Min. 1st Qu. Median 3rd Qu. Max.
-187.00 -32.90 6.96 31.40 210.00
Coefficients:
Estimate Std. Error t-value Pr(>|t|)
(Intercept) -109.976572 61.701384 -1.7824 0.08001.
value 0.104280 0.014996 6.9539 3.797e-09 ***
capital 0.344784 0.024520 14.0613 < 2.2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Total Sum of Squares: 1988300
Residual Sum of Squares: 257520
R-Squared: 0.87048
Adj. R-Squared: 0.86594
F-statistic: 191.545 on 2 and 57 DF, p-value: < 2.22e-16
回归系数的比较表明,固定和随机效应方法对这些数据产生了相似的结果。与固定效应回归的情况一样,检查随机效应是否真的需要是有意义的。这个任务的几个版本的拉格朗日乘数测试可在plmtest()中获得。
R> plmtest(gr_pool)
结果:
Lagrange Multiplier Test - (Honda) for balanced panels
data: invest ~ value + capital
normal = 15.47, p-value < 2.2e-16
alternative hypothesis: significant effects
该测试还表明,必须考虑某种形式的参数异质性。 随机效应方法比固定效应估计器在更严格的假设下更为有效,即个体效应的异质性。 因此,测试内生性是重要的,标准方法采用Hausman测试。 相关函数phtest()需要两个面板回归对象.
R> phtest(gr_re, gr_fe)
结果:
Hausman Test
data: invest ~ value + capital
chisq = 0.04038, df = 2, p-value = 0.98
alternative hypothesis: one model is inconsistent
根据上述相当类似的估计,并不存在内生性的问题。 plm包含进一步类型的静态面板数据模型的方法,特别是Hausman-Taylor模型(Hausman和Taylor 1981)和变化的系数模型。
2.Dynamic linear models
总结本节,我们提出一个更高级的例子,动态面板数据模型:

该模型通过Arellano和Bond(1991)的方法估计。 回想一下,他们的估计是在第一差异变换之后利用滞后的内生回归的一种广义的时刻方法(GMM)估计器。plm提供了原始的Arellano-Bond数据(EmplUK),处理在1976 - 1984年间140个英国公司的小组中的就业决定因素(emp)。 数据不平衡,每家公司有七到九个观察。
为了简化论述,我们首先建立一个静态公式,其中包含相关变量,每个员工的平均年工资(工资),固定资产(资本)固定资产的账面价值以及常数因素成本的附加值产出指数 ),全部为对数:
data("EmplUK",package = "plm")
#formula
form<-log(emp)~log(wage)+log(capital)+log(output)
提供Arellano-Bond估计器的函数是pgmm(),它的第一个参数是dynformula,这是一个静态模型方程,如上所述,增加了一个整数列表,其中包含每个变量的滞后期。 来自Arellano和Bond(1991)的动态就业方程现在估计如下:
empl_ab<-pgmm(dynformula(form,list(2,1,0,1)),data=EmplUK,index = c("firm","year"),effect = "twoways",model = "twosteps",gmm.inst=~log(emp),lag.gmm=list(c(2,99)))
summary(empl_ab)
因此,这是一个动态模型,其中p = 2,其中log(工资)和log(输出)都发生到滞后1,而log(资本)只有同时期。 指定了包含时间和企业特定效应的模型,工具变量是从属变量log(emp)的滞后项,所使用的滞后量由参数lag.gmm = list(c(2,99))给出,表明超过滞后1的所有滞后都将被用作工具。
Twoways effects Two steps model
Call:
pgmm(formula = dynformula(form, list(2, 1, 0, 1)), data = EmplUK,
effect = "twoways", model = "twosteps", index = c("firm",
"year"), gmm.inst = ~log(emp), lag.gmm = list(c(2, 99)))
Unbalanced Panel: n=140, T=7-9, N=1031
Number of Observations Used: 611
Residuals
Min. 1st Qu. Median Mean 3rd Qu. Max.
-0.6191000 -0.0255700 0.0000000 -0.0001339 0.0332000 0.6410000
Coefficients
Estimate Std. Error z-value Pr(>|z|)
lag(log(emp), c(1, 2))1 0.474151 0.185398 2.5575 0.0105437 *
lag(log(emp), c(1, 2))2 -0.052967 0.051749 -1.0235 0.3060506
log(wage) -0.513205 0.145565 -3.5256 0.0004225 ***
lag(log(wage), 1) 0.224640 0.141950 1.5825 0.1135279
log(capital) 0.292723 0.062627 4.6741 2.953e-06 ***
log(output) 0.609775 0.156263 3.9022 9.530e-05 ***
lag(log(output), 1) -0.446373 0.217302 -2.0542 0.0399605 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Sargan Test: chisq(25) = 30.11247 (p.value=0.22011)
Autocorrelation test (1): normal = -1.53845 (p.value=0.12394)
Autocorrelation test (2): normal = -0.2796829 (p.value=0.77972)
Wald test for coefficients: chisq(7) = 142.0353 (p.value=< 2.22e-16)
Wald test for time dummies: chisq(6) = 16.97046 (p.value=0.0093924)
