推荐系统之概率矩阵分解的详细推导过程(Probabilistic Matrix Factorization,PMF)
概率矩阵分解是目前在推荐领域很流行的模型。本文主要是推导论文 Mnih A, Salakhutdinov R R. Probabilistic matrix factorization[C]//Advances in neural information processing systems. 2008: 1257-1264. 中的结果。
传统的协同过滤方法既不能处理大数据量的推荐,也不能处理只有很少评分的用户。这篇论文提出了著名的概率矩阵分解的方法来解决这个问题。概率矩阵分解的思想是以中线性因子模型,它使用与用户相关的系数,将用户的偏好建模成一个一系列向量的线性组合。具体如下:
假设有$M$个电影和$N$个用户。$R_{ij}$表示第$i$个用户对电影$j$的评分。假设隐变量的维度是$D$,那么我们希望将评分矩阵$R$分解成两个矩阵,即用户隐矩阵$U\in R^{D\times N}$,和电影隐矩阵$V \in R^{D\times M}$。其中,$U_i$表示第$i$个用户的隐向量,$V_j$表示第$j$个电影的隐向量。假设评分是一个有高斯噪音的正态分布。那么我们的评分应当有如下公式:
p(R|U,V,\sigma^2)=\prod_{i=1}^N\prod_{j=1}^M\Big[\mathcal{N}(R_{ij}|U_i^TV_j,\sigma^2)\Big]^{I_{ij}}
这里的$\mathcal{N}(R_{ij}|U_i^TV_j,\sigma^2)$是指高斯分布的概率密度函数。$I_{ij}$是指示函数,表明如果用户$i$评论了电影$j$,那么其结果等与1,否则就是0。因此,上面的结果就是所有已经被评论的电影得分的乘积,也就是似然函数了。
我们给每个用户和电影的隐向量(特征向量)一个均值为0的高斯先验。有:
p(U|\sigma^2_U)=\prod_{i=1}^N \mathcal{N}(U_i|0,\sigma_U^2\mathbf{I})
p(V|\sigma^2_V)=\prod_{j=1}^M \mathcal{N}(V_j|0,\sigma_V^2\mathbf{I})
这里的$\mathbf{I}$是一个$D$维单位对角矩阵。那么,用户和电影特征的后验分布计算如下:
\begin{aligned}
p(U,V|R,\sigma^2,\sigma_V^2,\sigma_U^2) &= p(R|U,V,\sigma^2,\sigma_V^2,\sigma_U^2)\times p(U,V)/p(R,\sigma^2,\sigma_V^2,\sigma_U^2) \\
&\\
&\sim p(R|U,V,\sigma^2,\sigma_V^2,\sigma_U^2)\times p(U,V)\\
&\\
&= p(R|U,V,\sigma^2,\sigma_V^2,\sigma_U^2)\times p(U) \times p(V)
&\\
&=\prod_{i=1}^N\prod_{j=1}^M\Big[\mathcal{N}(R_{ij}|U_i^TV_j,\sigma^2)\Big]^{I_{ij}} \times \prod_{i=1}^{M}\mathcal{N}(U_i|0,\sigma_U^2\mathbf{I}) \times \prod_{j=1}^{N}\mathcal{N}(V_j|0,\sigma_V^2\mathbf{I})
\end{aligned}
对两边取个$\ln$(这是我们求解中常用的方法,取ln不改变函数凹凸性,极值点位置也不便,所以最优点的解也是一样的,同时,乘积形式变成求和形式,也简单很多)。
\ln p(U,V|R,\sigma^2,\sigma_V^2,\sigma_U^2) = \sum_{i=1}^{N}\sum_{j=1}^{M}I_{ij}\ln \mathcal{N}(R_{ij}|U_i^TV_j,\sigma^2) + \sum_{i=1}^{N} \ln \mathcal{N}(U_i|0,\sigma_U^2\mathbf{I}) + \sum_{j=1}^{M} \ln \mathcal{N}(V_j|0,\sigma_V^2\mathbf{I})
上面这三项都是形式完全一样,只是系数和均值方差不同,我们以其中一个为例,剩下都一样。即求解
\ln \mathcal{N}(U_i|0,\sigma_U^2\mathbf{I})
我们给出用户$i$的概率密度函数:
\mathcal{N}(U_i|0,\sigma_U^2\mathbf{I})=-\frac{1}{ (2\pi)^{D/2} |\sigma_V^2\mathbf{I}|^{1/2}} \exp(-\frac{1}{2}U_i^T(\sigma^2_u \mathbf{I})^{-1}U_i)
注意,由于$\mathbf{I}$是对角阵,那么$(\sigma^2_u \mathbf{I})^{-1}=\frac{1}{\sigma_u^2}\mathbf{I}$,所以:
\begin{aligned}
\ln\mathcal{N}(U_i|0,\sigma_U^2\mathbf{I}) &= \ln(-\frac{1}{ (2\pi)^{D/2} |\sigma_V^2\mathbf{I}|^{1/2}}) -\frac{U_i^TU_i}{2\sigma^2_u} \\
&\\
&= -\ln( |\sigma_U^2\mathbf{I}|^{1/2} ) - \frac{U_i^TU_i}{2\sigma^2_u} + C_U \\
&\\
&= -\frac{1}{2}\ln( \sigma_U^{2D} ) - \frac{U_i^TU_i}{2\sigma^2_u} + C_U\\
&\\
&= -\frac{D}{2}\ln( \sigma_U^{2} ) - \frac{U_i^TU_i}{2\sigma^2_u} + C_U\\
\end{aligned}
类似地,我们可以得到进而我们可以得到最终的公式(这里的$C_U$是常数,后面所有的常数都合并到一起了)。公式如下:
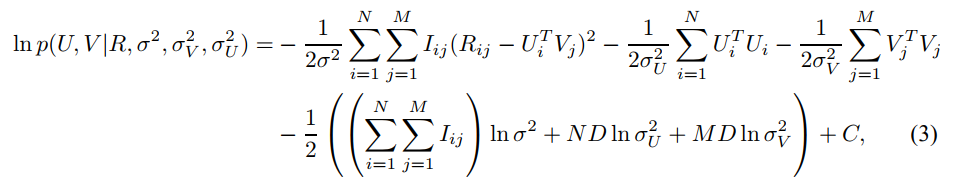
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
