Java入门基础笔记-8
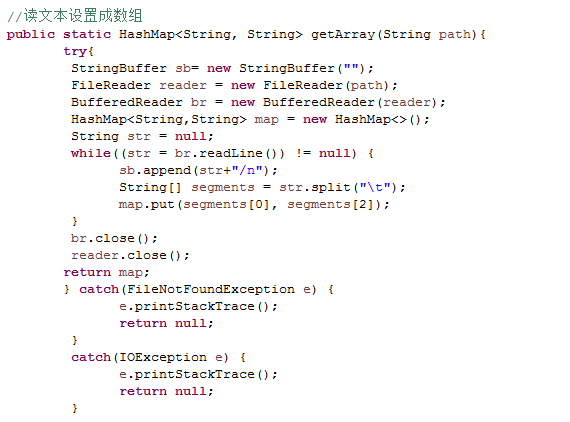
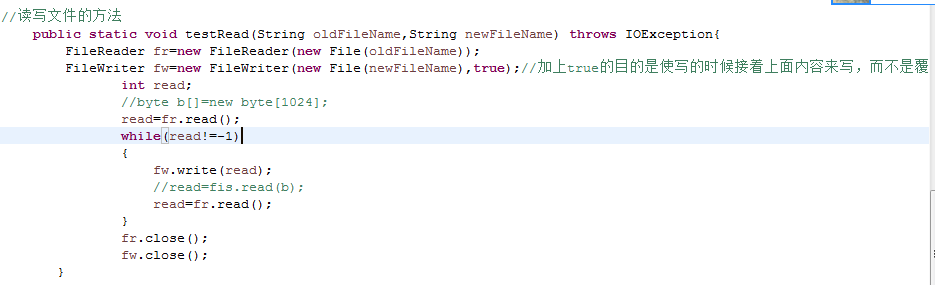
学习如何写TF-IDF的代码(1) 通过以上的学习,我们来具体完成一个任务,就是写出一个程序的代码。我们写代码不是凭空自己去写程序,对于一些解决方案,我们通过网络进行搜索,然后自己通过已经学到的知识进行修改,自己写的话太过于困难。具体任务如下: 数据描述:压缩文件中包含三类文件(夹): hotweibo:微博数据,是一个文件夹,里面是一串数字字母命名的文件,文件包含该类别下获取的热门微博内容 hotweibo_classification.txt:微博代号对应的分类文件,名字是,有三列,第一列是hotweibo文件夹下文件的名称,第二列是细分类别,第三列是大类别。 stopWords:停用词库,里面是所有的停用词 作业一:相同类别文件的合并操作 作业描述:按照hotweibo_classification.txt文件描述,请将相同大类别的文件内容合并到一起,保存到一个新的文件夹中。合并后每个文件的名字就是大类的名称。 作业二:数据预处理之文本初步清理 作业描述:将作业一中生成的数据的所有html标签数据(即<>括起来的内容)替换成“HTML”这个词,并将结果保存的新的文件夹中,每个文件名字不变。比如: @微博校园 清理后: HTML@微博校园HTML 作业三:数据预处理之中文文本分词 作业描述:请按照如下地址的教学情况导入NLPIR分词软件,对讲作业二处理的文件内容进行分词操作,并将分词结果对应存入新的文件夹的文件中,名字不变。 教学地址:http://www.datalearner.com/blog/1051461066435555 作业四:数据预处理之去除停用词 作业描述:针对作业三的分词结果,去除其中所有的停用词(即删除停用词),存入新文件中。 作业五:使用TF-IDF计算词权重 作业描述:针对作业四的结果,对每个类别文件中每个不同的词语计算其权重,计算单词t在当前类别下的权重公式如下:
W_t=[1+log(f_(t,d) )]*log(N/N_t)
其中,f_(t,d)表示当前类别下单词t的出现次数,N表示所有文档数量,N_t表示包含单词t的文档数量。
今天具体完成的是作业1,按照hotweibo_classification.txt文件描述,请将相同大类别的文件内容合并到一起,保存到一个新的文件夹中。合并后每个文件的名字就是大类的名称。 具体数据集可以私信获取。以下代码是我自己写的,最后会放上我的大神的代码。
首先第一步就是判断文件的行数。