使用kaggle房价预测的实例说明预测算法中OneHotEncoder、LabelEncoder与OrdinalEncoder的使用及其差异
在使用有监督的机器学习的方法时候,对特征的预处理是很重要的一个步骤。但特征包含有限个离散变量的时候,这类特征称为类别特征。通常情况下,类别特征是由字符组成的特征,例如gender=[“male”,”female”]。对于这类特征的处理,sklearn中常见的方法有两种,一种是OneHotEncoder,另一种很多人说是LabelEncoder,其实不对。sklearn中,还有一个OrdinalEncoder,二者似乎一样,但其实并不相同,差别很大。本文将用Kaggle的房价预测的实例来描述如何这些差异以及不同处理对预测算法的影响。
一、概述
类别特征下包含有限个离散的特征值,通常是字符型。但是大多数的模型都无法直接处理字符。所以,我们一般需要对类别特征做处理,之后才能应用模型。scikit-learn中目前有两类方法可以处理。
第一种是LabelEncoder。就是将类别编码用数字进行编码,这样就可以被很多模型使用了。如下所示:
import pandas as pd
from sklearn.preprocessing import OneHotEncoder, LabelEncoder, OrdinalEncoder
df = pd.DataFrame(
[
[1000, "male", 23],
[1001, "female", 22],
[1002, "male", 69]
],
columns=['id', 'gender', 'age']
).set_index("id")
print(df.head())
df["gender"] = df[["gender"]].apply(LabelEncoder().fit_transform)
print(df.head())
代码的输出为:
# 原始数据
gender age
id
1000 male 23
1001 female 22
1002 male 69
# LabelEncoder转换之后
gender age
id
1000 1 23
1001 0 22
1002 1 69
但是,显然这种方式并不是十分合理。因为转换成数字之后,显然female对应的数字比male小,在数学中这是有意义的。但实际并不是。所以,需要有其它的处理方法,即OneHotEncoder。
OneHotEncoder,也就是将类别特征变成0和1组成的独热编码。如下图所示:
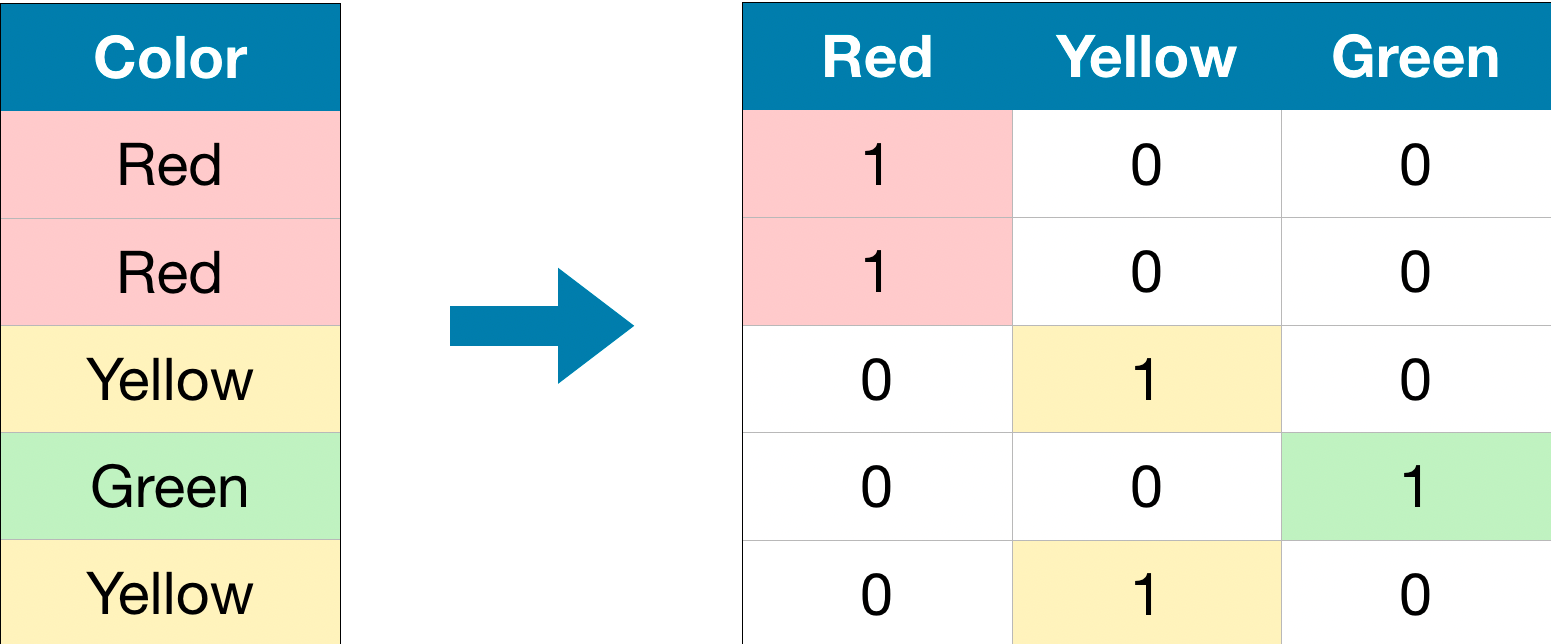
在类别特征值包含的种类比较少的情况下,这是一种很有效的方法。而且可以避免将无序的类别特征变成数字的时候引入数值的差异。实例如下:
df_encoded = pd.DataFrame(OneHotEncoder(sparse=False).fit_transform(df[["gender"]].values), index=df.index)
df = pd.concat([df, df_encoded], axis=1).drop(["gender"], axis=1)
print(df.head())
依然是上面的数据,这次的输出是:
age 0 1
id
1000 23 0.0 1.0
1001 22 1.0 0.0
1002 69 0.0 1.0
可以看到,gender已经被新的0和1特征列代替了。这样的结果依然可以输出。
但是,这里其实还有个问题。LabelEncoder其实本意并不是来处理特征的。sklearn中,对特征做编码处理的其实应该是OrdinalEncoder。LabelEncoder其实是处理分类的类别标签的。对于LabelEncoder,官方文档的描述是:
Encode target labels with value between 0 and n_classes-1.
而OrdinalEncoder的描述:
Encode categorical features as an integer array.
原因在于,类别标签一般来说是不需要顺序的。例如预测性别、国别等。而类别特征其实有时候是有顺序的。例如,房屋的质量分成好、中、坏其实是可以用数值表示,且数值可以有大小顺序的。它们的大小也许是有意义的。所以,OrdinalEncoder处理类别特征才是正确的,而且它里面包含了额外的很多参数用以控制顺序等。下面我们用实例说明。
二、房价的真实案例
通过前面的描述,我们可以看到,不同的场景使用不同的编码处理类别特征对模型的影响不同。在这里我们举一个房价预测的例子,这个数据来自Kaggle房价预测。我们用如下方法读取数据:
train_file = "F:/data/kaggle/house-prices-advanced-regression-techniques/train.csv"
numeric_features = ["MSSubClass", "LotArea", "OverallQual", "OverallCond", "YearBuilt", "YearRemodAdd", "BsmtFinSF1", "BsmtFinSF2", "BsmtUnfSF"]
category_features = ["BsmtQual", "FireplaceQu", "GarageQual", "GarageCond"]
target_feature = ["SalePrice"]
all_features = numeric_features + category_features + target_feature
# read data
df = pd.read_csv(train_file, usecols=all_features)
print(df.shape)
df.dropna(subset=category_features, how="all", inplace=True)
df[category_features] = df[category_features].fillna("NA").astype("category")
# define the label
y = np.log1p(df[target_feature].values)
这里我们非常简单的读取我们想要的列,并对房价这个预测的变量做了log1p的转换。
数据集中包含了很多的不同类型的特征,在这里我们使用其中的一些数值型特征,还有几个类别特征:
numeric_features = ["MSSubClass", "LotArea", "OverallQual", "OverallCond", "YearBuilt", "YearRemodAdd", "BsmtFinSF1", "BsmtFinSF2", "BsmtUnfSF"]
category_features = ["BsmtQual", "FireplaceQu", "GarageQual", "GarageCond"]
target_feature = ["SalePrice"]
在这里,数值特征都是数字,我们不做任何处理。而类别特征都是关于质量的,有如下几种:
Ex Excellent
Gd Good
TA Average/Typical
Fa Fair
NA None
显然,这些评价之间是有顺序的。尽管都是str类的数据,但是转换的时候需要考虑顺序。
接下来我们使用线性回归模型分别针对不同的特征处理计算看得到什么样的结果。
方案一:只用数值特征
代码如下:
# 原始数值特征
X = df[numeric_features].fillna(-1).values
# 交叉验证
scores = cross_val_score(clf, X, y, cv=5, scoring="neg_root_mean_squared_error")
print(f"original feature result:{np.sqrt(np.abs(np.mean(scores)))}")
这个很简单,没什么说的,结果是:0.4427966631997059
方案二:数值特征+OneHotEncoder
第二种方法,我们把类别特征引入,并做OneHot编码之后来训练:
train_df = df.drop(target_feature, axis=1).copy()
oe = OneHotEncoder(sparse=False)
df_encoded = pd.DataFrame(oe.fit_transform(train_df[category_features]), index=train_df.index)
train_df = pd.concat([train_df[numeric_features], df_encoded], axis=1)
X = train_df.values
scores = cross_val_score(clf, X, y, cv=5, scoring="neg_root_mean_squared_error")
print(f"one hot encoder:{np.sqrt(np.abs(np.mean(scores)))}")
在这里,我们的结果是:0.42941627539936705。显然,比仅仅使用数值特征要好。
方案三:数值特征+LabelEncoder以及数值特征+OrdinalEncoder
接下来,我们换一种方式,使用LabelEncoder与OrdinalEncoder,但是默认参数。看看二者的区别。代码如下:
# label encoding
train_df = df.drop(target_feature, axis=1).copy()
le = LabelEncoder()
train_df[category_features] = train_df[category_features].apply(le.fit_transform)
X = train_df.values
scores = cross_val_score(clf, X, y, cv=5, scoring="neg_root_mean_squared_error")
print(f"label encoder:{np.sqrt(np.abs(np.mean(scores)))}")
# ordinal encoding with auto
train_df = df.drop(target_feature, axis=1).copy()
oe = OrdinalEncoder()
df_encoded = pd.DataFrame(oe.fit_transform(train_df[category_features]))
train_df[category_features] = df_encoded.values
X = train_df.values
scores = cross_val_score(clf, X, y, cv=5, scoring="neg_root_mean_squared_error")
print(f"ordinal encoder with auto:{np.sqrt(np.abs(np.mean(scores)))}")
最终输出的结果都是:0.4397654309601027。是不是很奇怪,看起来都是一样的。但是问题在这里出现了。其实这不是OrdinalEncoder的真实用法。OrdinalEncoder有个参数是categories,默认是auto,意思是自动根据出现的类别特征,自动编码。这时候它的效果与LabelEncoder是一样的。但实际中,算法本身无法知道类别特征之间的顺序是什么样的,这时候,需要我们自己给定,这时候才能显示OrdinalEncoder威力。而LabelEncoder不存在这种用法。
方案四:数值特征+OrdinalEncoder,但是使用自定义的categories参数
由于我们事先了解了这些类别特征下的特征值是什么样的,而且我们认为是有顺序的。因此,我们可以手动指定编码规则:
# ordinal encoding with order
train_df = df.drop(target_feature, axis=1).copy()
oe = OrdinalEncoder(categories=[
["Ex", "Gd", "TA", "Fa", "Po", "NA"],
["Ex", "Gd", "TA", "Fa", "Po", "NA"],
["Ex", "Gd", "TA", "Fa", "Po", "NA"],
["Ex", "Gd", "TA", "Fa", "Po", "NA"]
])
df_encoded = pd.DataFrame(oe.fit_transform(train_df[category_features]))
train_df[category_features] = df_encoded.values
X = train_df.values
scores = cross_val_score(clf, X, y, cv=5, scoring="neg_root_mean_squared_error")
print(f"ordinal encoder with order:{np.sqrt(np.abs(np.mean(scores)))}")
这样的话,最终的编码会根据顺序进行。那么,这时候我们得到的结果是:0.42950404751743254。显然,结果好于categories为默认参数的情况。但是,这个结果与OneHotEncoder类似,甚至要略差于OneHotEncoder。实际中,这两者的性能可能与模型和数据有关,无法一概而论。但是总体而言,OrdinalEncoder设置自定义的编码排序是很重要的。
三、总结
根据这些内容,我们可以得到如下一些结论。
- 类别特征很多时候无法直接处理,需要预处理之后才能使用。而这种特征的处理需要很小心,因为它的影响可能很复杂。
- 对于类别特征的处理使用OneHotEncoder还是OrdinalEncoder,可以根据实际情况来。从效果来看,二者不一定谁一定好。但是对于类别值很多的时候,OneHotEncoder可能会产生过多的列,造成很大的输入数据,并不合适。因此,对于特征值类别较多的时候用OrdinalEncoder更合适。
- 千万要记得LabelEncoder与OrdinalEncoder是不一样的,不能互相代替。前阵针对的是类别标签这种无序的数据。所以最好以后将前者用在类别标签的处理上,后者才能用来处理特征。
- OrdinalEncoder中编码顺序很重要。对于有顺序的类别标签,需要我们自己手动设置。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
