重磅!学术论文处理预训练大模型GALACTICA发布!
自然语言处理预训练大模型在最近几年十分流行,如OpenAI的GPT-3模型,在很多领域都取得了十分优异的性能。谷歌的PaLM也在很多自然语言处理模型中获得了很好的效果。而昨天,PapersWithCode发布了一个学术论文处理领域预训练大模型GALACTICA。功能十分强大,是科研人员的好福利!

GALACTICA可以总结学术文献,解决数学问题,生成Wiki文章,编写科学代码,对分子和蛋白质进行注释等等。
信息过载是科学进步的一个主要障碍。科学文献和数据的爆炸性增长使得在大量的信息中发现有用的见解变得越来越难。今天,人们通过搜索引擎来获取科学知识,但它们却无法单独组织科学知识。PapersWithCode发布的Galactica是一个可以存储、组合和推理科学知识的大型语言模型。在一个由论文、参考资料、知识库和许多其他来源组成的大型科学语料库上进行训练。该模型在一系列科学任务上的表现超过了现有模型。在诸如LaTeX方程式的技术知识探测上,Galactica比最新的GPT-3高出68.2%和49.0%。Galactica在推理方面也表现良好,在数学MMLU上比Chinchilla高出41.3%对35.7%,在MATH上比PaLM 540B高出20.4%对8.8%。它还在PubMedQA和MedMCQA dev等下游任务上创下了77.6%和52.9%的最新水平。尽管没有经过一般语料库的训练,Galactica在BIG-bench上的表现超过了BLOOM和OPT-175B。
GALACTICA是可以处理很多任务。举例如下:
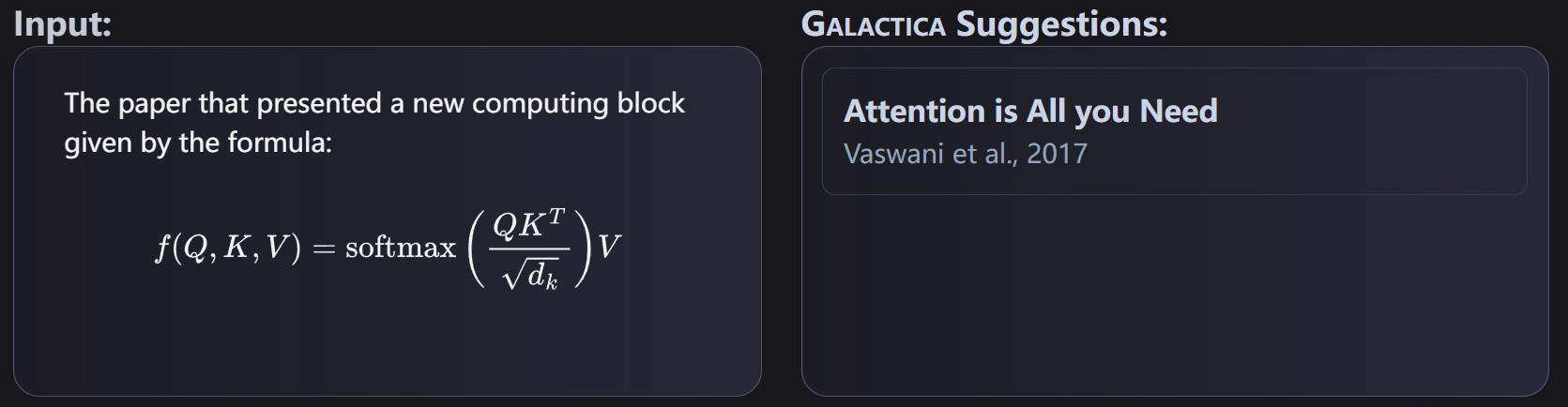
一、根据公式和内容,给出所引用的论文
Galactica模型是在一个大型语料库上训练出来的,该语料库包括超过3.6亿条上下文引文和超过5000万条在不同来源中规范化的独特引用。这使得Galactica能够建议引文并帮助发现相关的论文。 下图是根据公式给出所在论文的案例:
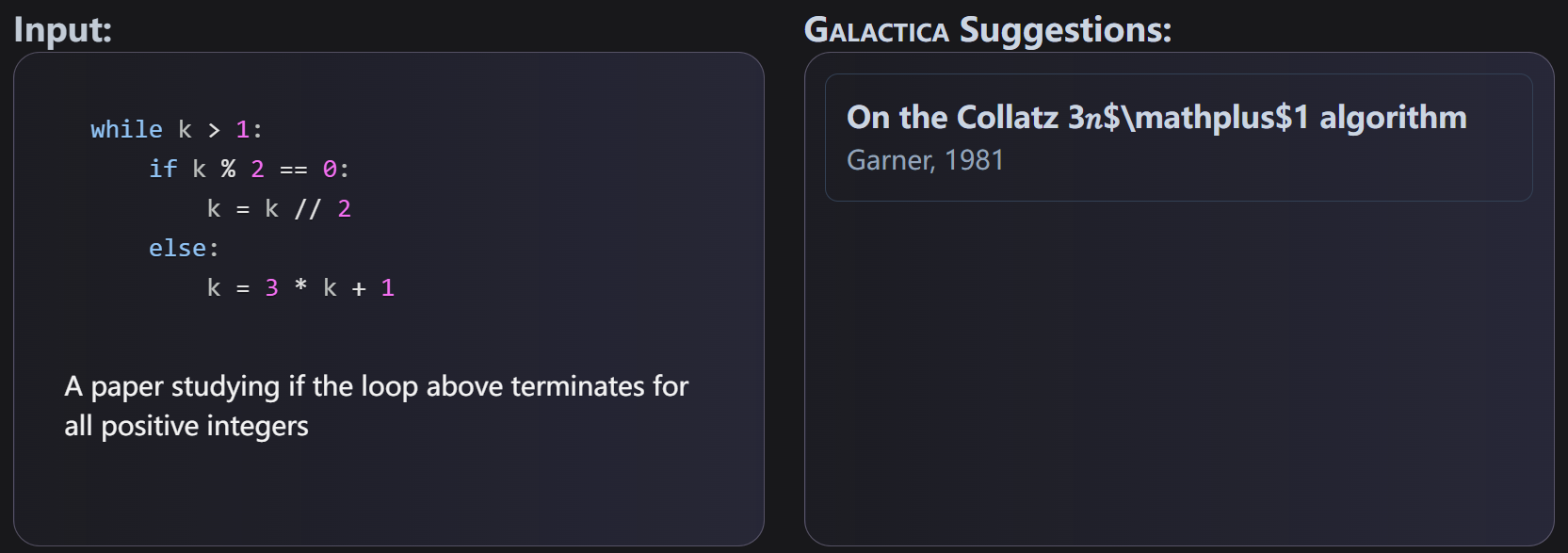
除了公式外,它甚至可以根据一段代码给出相关论文。如下图就是根据一篇研究循环是否对所有正整数终止的论文,十分强大!
二、翻译转换
这里的翻译不是指不同语言的翻译,而是公式与英语叙述、公式和代码以及不同语言代码甚至是代码与描述之间的翻译。如下图所示,是数学公式翻译成英语描述:

Python代码转换成Latex公式的结果:

Galactica模型是在一个名为NatureBook的高质量科学数据集上训练出来的,使模型能够处理科学术语、数学和化学公式以及源代码。
除了上面这些实例外,Galactica模型的能力概括如下:
- 引用预测
- LaTeX预测
- 推理
- 文档生成
- 分子式生成
- 预测蛋白质注释
不过,不像其它企业喜欢说优点,官方也将这个模型的限制描述了出来:
- 语言模型会产生幻觉。不能保证语言模型的真实或可靠的输出,即使是像Galactica这样在高质量数据上训练出来的大型模型。在没有验证的情况下,千万不要听从语言模型的建议。
- 语言模型是有频率偏向的。Galactica很适合生成关于引用率高的概念的内容,但对于引用率较低的概念和想法来说就不那么好了,在这种情况下,产生幻觉的可能性更大。
- 语言模型经常是自信但错误的。Galactica生成的一些文本可能看起来非常真实和高度自信,但可能在重要方面有微妙的错误。对于高度技术性的内容来说,这种情况尤其明显。
但是,最重要的是,他们的模型是开源的!最大的模型1200亿参数,最小的只有1.25亿参数,二进制预训练文件大小235MB。最大的模型应该是200-300GB之间!
模型详情:https://www.datalearner.com/ai-resources/pretrained-models/galactica
