OpenAI发布最新最强大的AI对话系统——GPT3.5微调的产物ChatGPT
今天,OpenAI公布了最新的一个基于AI的对话系统ChatGPT。根据官方介绍,ChatGPT以对话方式进行交互。对话格式使ChatGPT能够回答后续问题、承认错误、质疑不正确的前提和拒绝不适当的请求。ChatGPT是InstructGPT的兄弟模型,它被训练为在提示中遵循指令并提供详细的响应。
OpenAI开放了一个在线演示的系统(地址:https://chat.openai.com/auth/login ),不过由于访问人数太多,现在已经无法使用。
根据网友使用反馈,大家只有一个感觉,Google完蛋了。下图是几个例子。
一、直接根据描述给出latex公式结果
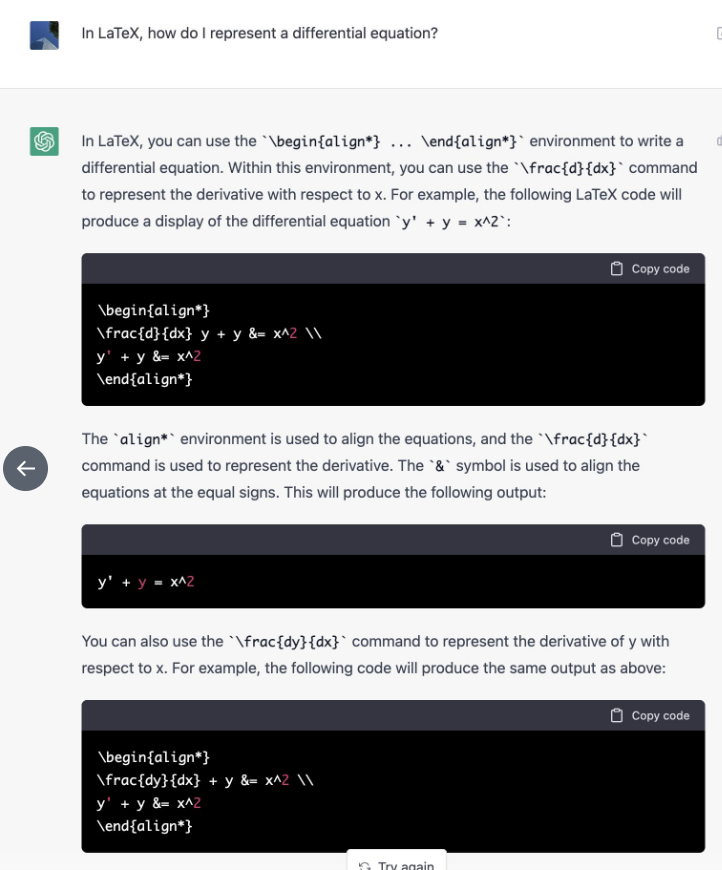
有人问如何使用latex表示微分结果,下图一个是谷歌一个是ChatGPT:
二、解释冒泡排序最坏时间复杂度
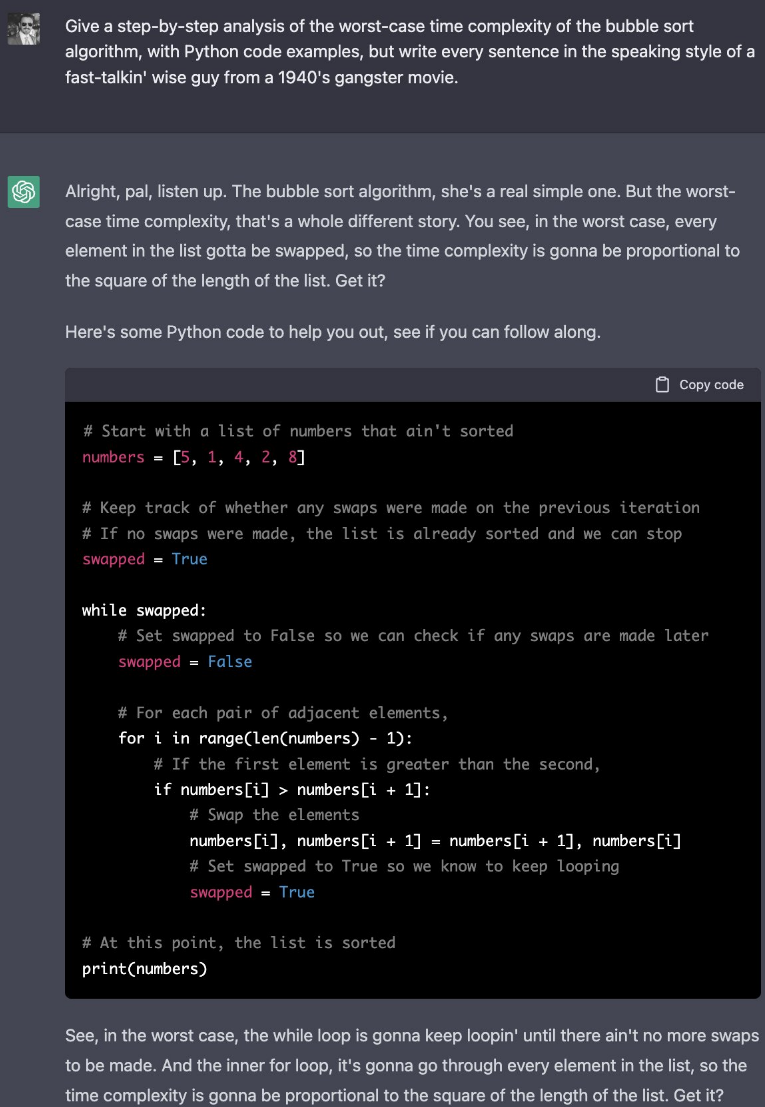
下图是直接让ChatGPT给出冒泡排序的最坏时间复杂度,需要一步一步解释:
三、根据描述编程
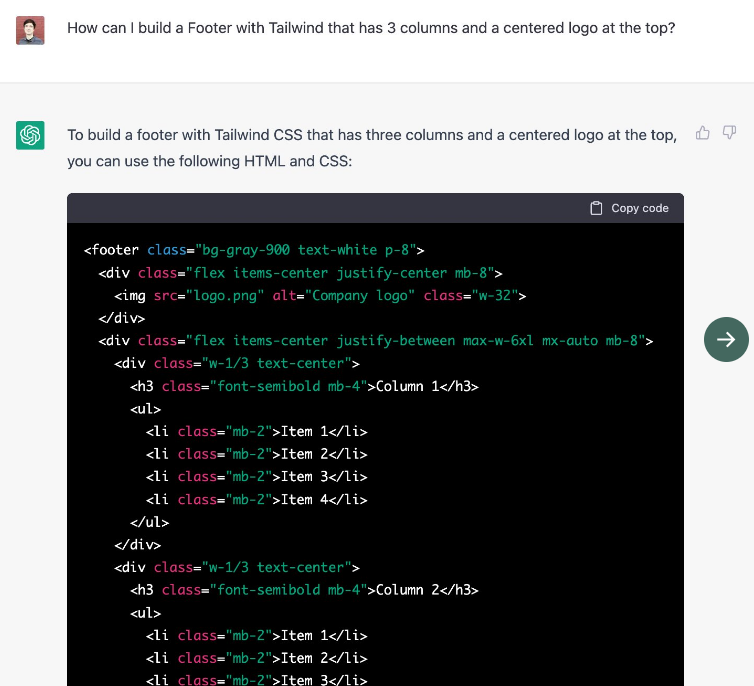
问如何使用Tailwind建立3列的页脚结果:
四、代码的review和解决问题
一个人写了一段buffer溢出代码,给出了运行错误,问为什么,ChatGPT也能给出解释。


五、自动修复bug
直接问下面代码的bug是啥

除了上述描述的内容,还可以根据需求设计装潢(给出装潢结果图)、解释AWS的IAM策略、采访关于债务可持续性、写一篇关于如何使用matplotlib画图的博客、写计算机网络的作业。
这个ChatGPT实在是太吓人了。官方介绍如下:
我们使用来自人类反馈的强化学习(RLHF)来训练这个模型,使用与InstructionGPT相同的方法,但数据收集设置略有不同。我们使用有监督的微调训练了一个初始模型:人工智能训练师提供对话,他们扮演用户和人工智能助手的双方角色。我们让培训师获得模型书面建议,以帮助他们撰写回复。
为了创建强化学习的奖励模型,我们需要收集比较数据,其中包括两个或多个按质量排序的模型响应。为了收集这些数据,我们进行了AI培训师与聊天机器人的对话。我们随机选择了一个模型撰写的消息,抽样了几个备选的完成,并让AI培训师对其进行排名。使用这些奖励模型,我们可以使用近端策略优化对模型进行微调。我们对这个过程进行了多次迭代。
ChatGPT是从GPT-3.5系列中的一个模型进行微调的,该系列于2022年初完成了培训。您可以在这里了解有关3.5系列的更多信息。ChatGPT和GPT 3.5在Azure AI超级计算基础设施上进行了培训。
