OpenAI世界最强的语音识别预训练模型WhisperV2即将来临
1,261 阅读
Whisper是由Open AI训练并开源的语音识别模型,它在英语语音识别方面接近人类水平的鲁棒性和准确性。该模型于2022年9月21日发布之后引起了广大的关注。由于模型的准确性太过惊人,大家已经认为可以直接用于视频的配音制作了。而今天有人发现Whisper的GitHub上有了一个新的提交记录,显示Whisper V2版本即将来临。
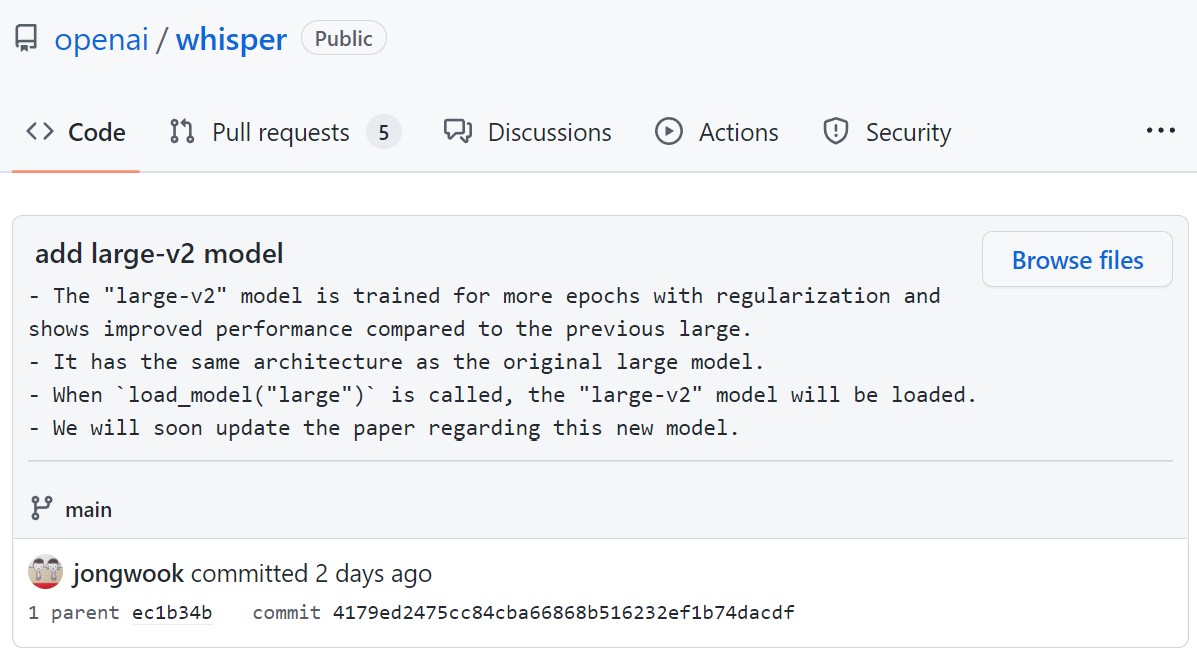
上图显示,V2版本的Whisper模型于第一个版本的结构一样,但是加了正则,且训练的迭代次数更多。这个模型的论文也将很快发布!由于第一版的效果已经很好,这第二版的提升十分令人期待!
Whisper是一个自动语音识别(ASR)系统,它是在从网络上收集的680,000小时的多语言和多任务监督数据上训练出来的。我们表明,使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术语言的稳健性。此外,它还能实现多种语言的转录,以及从这些语言翻译成英语。我们正在开放模型和推理代码,作为建立有用的应用程序和进一步研究稳健语音处理的基础。
关于Whisper的介绍:https://www.datalearner.com/ai-resources/pretrained-models/Whisper
