2022年11月底,OpenAI发布ChatGPT,2023年3月14日,GPT-4发布。这两个模型让全球感受到了AI的力量。而随着MetaAI开源著名的LLaMA,以及斯坦福大学提出Stanford Alpaca之后,业界开始有更多的AI模型发布。
根据DataLearner官方收集的数据统计,2023年4月份,在大语言模型和图像生成领域有20多个重要的模型发布。完整的2023年4月份模型列表:https://www.datalearner.com/ai-models/2023/04
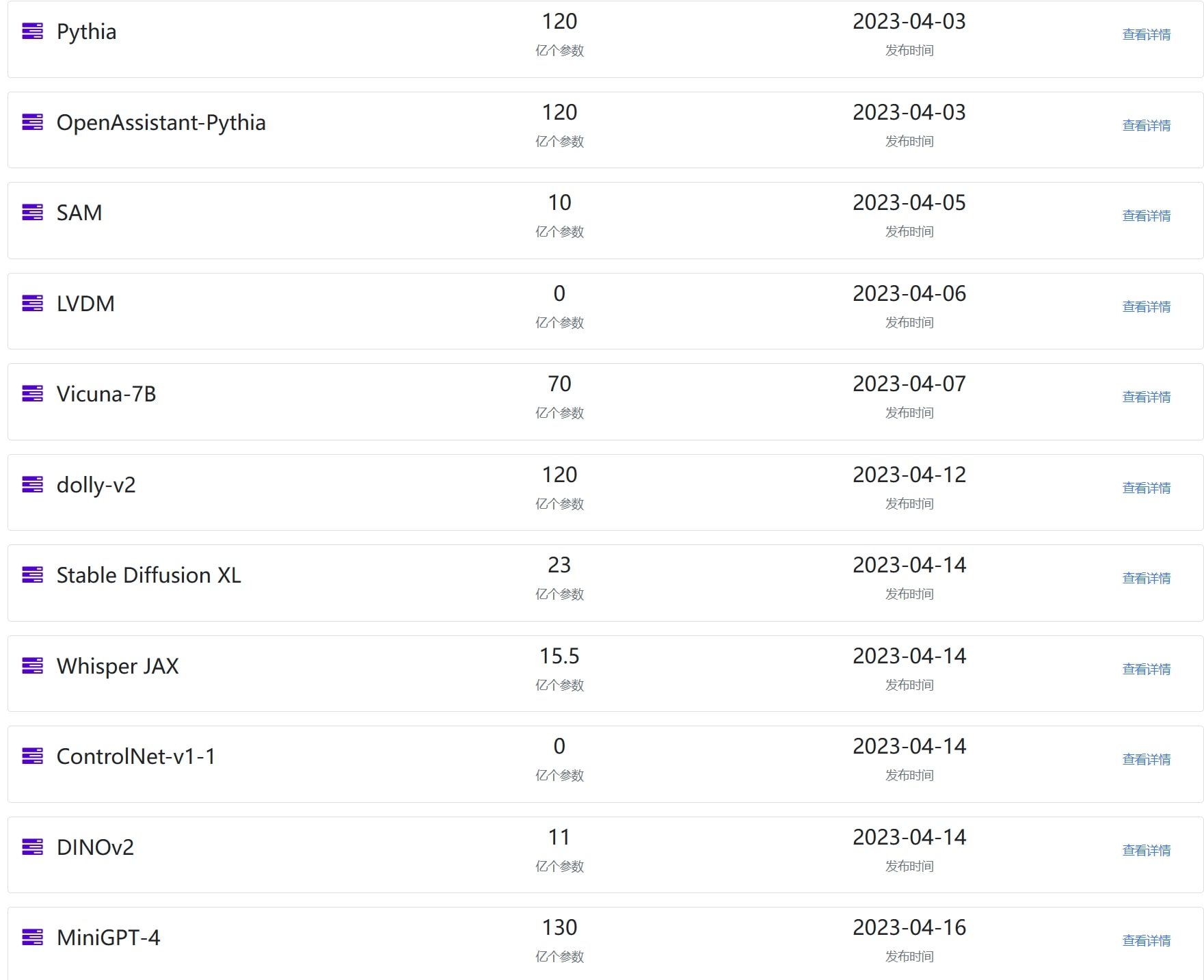 上图是部分模型展示,数据来源:https://www.datalearner.com/ai-models/pretrained-models
上图是部分模型展示,数据来源:https://www.datalearner.com/ai-models/pretrained-models
本文将对4月份发布的这些重要的模型做一个总结,并就其中部分重要的模型进行进一步介绍。
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
一、4月份业界发布的重要AI模型总结
2023年4月份业界发布的模型百花齐放,从UC Berkeley发布的Vicuna到MetaAI的SAM,开源AI模型繁荣发展!UC Berkeley、Stability AI、EleutherAI等产出丰富。
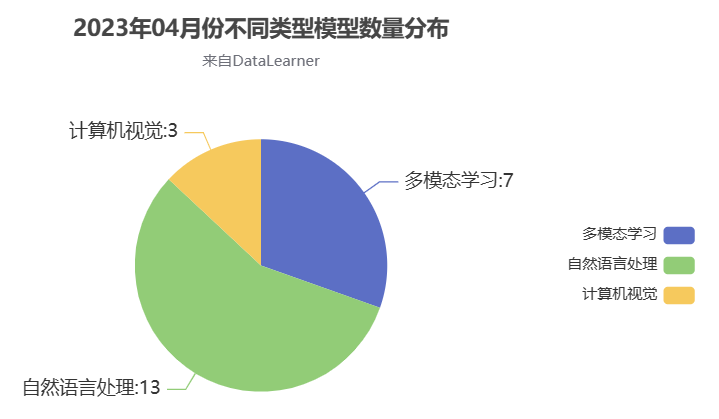
2023年4月份,业界发布的重要模型23个,自然语言处理领域的模型13个、计算机视觉领域3个、多模态模型7个。显然,相比较之前,模型的种类更加丰富,也开始从自然语言领域往其它领域发展。这其中最大的是StableLM模型,计划最高参数1750亿,而微软发布的LLaVA模型则是基于MetaAI发布的LLaMA继续开发得到的,因此最大规模650亿。
二、2023年4月份自然语言处理模型简介
2023年自然语言处理的模型主要是开源模型为主,其中Vicuna-7B可以运行在浏览器侧,表现亮眼。我们将挑选其中重要的几个介绍。
2.1、Pythia
Pythia是EleutherAI在4月3日发布的一系列开源的自回归语言模型。该模型共8个不同的规模,并且在2个不同的数据集上训练(分别是Pile数据集和去重的Pile数据集)。所以共16个模型。这个模型训练的主要目的是结合了可解释性分析和缩放定律,以了解知识在自回归变换器中的训练过程中是如何发展和演变的。
Pythia模型系列完全开源,包括代码和预训练结果,因此在后续的很多模型对比以及微调中都有出现。OpenAssistant、Dolly等模型都有基于Pythia继续微调的版本。
2.2、Dolly-V2
Dolly 2.0是一种基于EleutherAI pythia微调的模型(参数120亿)。在一个新的高质量人类生成的指令跟踪数据集上进行微调,这些数据集是由Databricks员工众包生成的。
这是继Databricks发布Dolly 1.0过去不到一个月时间又一个开源的Dolly模型。不过与Dolly 1.0不同的是,Dolly 2.0是基于pythia模型训练得到。
重点是Dolly 2.0的全部内容都是开源的,包括训练代码、数据集和模型权重,所有这些都适用于商业用途。这意味着任何组织都可以创建、拥有和定制强大的LLMs,可以与人们交流,而无需支付API访问费用或与第三方共享数据。
Dolly 2.0包含了一系列多个版本,最大的参数是120亿,还有70亿、30亿版本:即dolly-v2-12b、dolly-v2-7b和dolly-v2-3b。
2.3、Vicuna-7B与FastChat-T5
Vicuna-7B与FastChat-T5都是由LM-SYS发布的,这是一个由UC Berkeley与其它机构联合成立的一个研究小组。
Vicuna是一个开源的大语言模型,3月底发布了第一个130亿参数的版本。4月7日,70亿参数版本的Vicuna-7B发布,4月12日,Vicuna-7B的预训练结果更新到1.1版本,主要更新重构标记化和分隔符并修复有监督的微调损失计算。
Vicuna-7B的预训练结果只有13.5G,可以在M1芯片的苹果电脑上运行,也有人基于WebGPU做了浏览器的版本。也就是说,它可以轻松在本机上运行。
FastChat-T5是基于Google开源的Flan-T5-XL模型微调的。根据官网提供的数据,FastChat-T5-3B虽然只有30亿参数,但是比Dolly-V2-12B模型更好。
2.4、h2oGPT
h2oGPT是H2O公司开源的一个类似ChatGPT的应用。是基于EleutherAI发布的GPT-NeoX-20b模型微调的结果。使用的是H2O自己收集的数据集。
h2oGPT的最大特点是具有完全宽松、商业可用的代码、数据和模型。
2.5、StableLM和StableVicuna-13B
这两个模型都是由StabilityAI开源的大语言模型。StabilityAI是著名的开源软件Stable Diffusion的开发者,该系列模型完全开源,但是做的是文本生成图像方向。而StableLM是StabilityAI的第一个开源的大语言模型。
StableLM系列包含2种模型,一个是基础模型,名字中包含base。另一种是使用斯坦福Alpaca的微调流程在5个对话数据集上的联合微调得到的结果,名字中包含tuned。
StableVicuna是Vicuna v0 13b的进一步指令微调和RLHF训练版本,它是一个指令微调的LLaMA 13b模型。
2.6、其它自然语言处理领域的模型
除了上面比较知名的模型外,还有几个模型也很重要,只是可能因为尚在发布中。其中比较重要的是Replit家的2个模型:Replit Code V1-3b和Replit Finetuned V1-3b。这两个都是27亿参数,但是基于5250亿tokens的代码数据集训练,根据官方的测试结果,当前阶段,这两个小规模的模型已经超越了所有的开源模型效果了。其水平比650亿参数的LLaMA和120亿参数的Codex效果更好。Replit专注编程领域,且承诺Replit Code V1-3b将会开源。那么,这是一个值得期待的模型。
此外,TOGETHER发布的RedPajama项目也透露了一些新消息,包括70亿参数和28亿参数的两个版本训练模型结果已经超越了同等规模的其它模型。因为RedPajama训练数据是极其庞大的,它的模型也值得大家期待。
三、2023年4月份计算机视觉领域AI模型简介
4月份,计算机视觉领域的比较有影响力的模型共3个,尽管数量不多,但是相比之前,已经算得上很丰富了,而且模型的影响力都很高。而且MetaAI一家占了2个,看样子真是之前元宇宙的投资出成果了~
3.1、MetaAI开源的Segment Anything Model
SAM全称是Segment Anything Model,由MetaAI在4月5日发布的一个图像分割领域的预训练模型。该模型十分强大,并且有类似GPT那种基于Prompt的工作能力,在图像分割任务上展示了强大的能力!此外,该模型从数据集到训练代码和预训练结果完全开源!真Open的AI!
由于SAM效果非常好,且完全开源,已经有很多项目都在基于这个模型进行改进和应用。是计算机视觉领域近年来少有的开源力作!
3.2、MetaAI开源DINOv2
2021年4月30日,MetaAI公开了DINO算法,DINO的核心思想是在无需标注数据的情况下,学习图像的有意义表示。通过自监督学习,DINO可以从大量未标注的图像中提取视觉特征,这些特征对于各种下游计算机视觉任务非常有用,例如图像分类、物体检测和语义分割。时隔一年后的2022年4月8日,MetaAI开源了DINO的实现代码和预训练结果。
DINOv2是MetaAI最新开源的计算机视觉领域的预训练大模型。相比较DINO的第一个版本,作者做了很多的修改,使得v2版本的DINO模型性能更加强大。
3.3、ControlNet-V1.1发布
ControlNet是一种新的神将网络结构,由斯坦福大学的Lvmin Zhang和Maneesh Agrawala提出的可以用来增强扩散模型的方法。主要是基于已有的Text-to-Image预训练模型对特定数据进行微调以更加适合使用者的目的。这个结构最大的特点是可以在比较资源少的设备如个人PC上对大模型进行调整以获得更好的效果。
基于这个方法改进的StableDiffusion是目前应用最广范效果最好的模型。
ControlNet 1.1是ControlNet最新的发布版本,发布于4月14日,相比较最早的ControlNet,它最大的优点是提升了模型的鲁棒性和结果的质量。并且将会增加多个新的模型。是十分值得大家关注的模型。
四、2023年4月份多模态模型进展
由于文本生成图像的模型算是多模态领域的模型,所以多模态模型比纯计算机视觉的模型要多,共7个。
4.1、腾讯AI实验室发布视频生成模型LVDM
LVDM全称Latent Video Diffusion Models,是由香港科技大学与腾讯AI实验室发布的一个视频扩散模型,可以用来做文本生成视频以及视频编辑。
与该模型同步发布的是一个视频编辑工具:VideoCrafter,可以用来做视频生成和视频编辑。
与该模型同步发布的是一个视频编辑工具:VideoCrafter,可以用来做视频生成和视频编辑。从演示结果看,该模型的效果十分好,所以尽管技术细节还未公布,但是已经吸引了很多人的注意。
4.2、Stability AI最新的27亿参数的Stable Diffusion XL发布
Stable Diffusion是StabilityAI开源的一系列图像生成模型。它的效果随着模型的迭代也增强。因为是开源的模型,且效果很好,所以一直是大家使用最多的模型。
1.5版本之前的Stable Diffusion因为不控制NSFW内容,一直霸占Hugging Face上流行模型榜单。而之前的2.1版本也一直是大家使用很多的模型。本次发布的Stable Diffusion XL是其最新的版本,根据之前的数据,该模型参数27亿,效果十分逼真。
4.3、比原始Whisper快70倍的Whisper JAX发布
Whisper是由OpenAI开源的语言识别模型,Whisper JAX则是JAX的实现版本。主要基于? Hugging Face Transformers的Whisper实现。与OpenAI的PyTorch代码相比,Whisper JAX运行速度快了70多倍,是目前最快的Whisper实现。
4.4、快速将语言模型变成多模态模型的MiniGPT-4
这是一个被低估的多模态学习的方法。MiniGPT-4是一个可以理解图片的大语言模型,是由开源的预训练模型Vicuna-13B与BLIP-2结合的新模型。十分简单。
- 首先是使用500万个图像-文本数据训练,在4个A100上训练了10个小时左右,不过这个阶段的模型的生成能力受到了严重的影响,因此还有第二个阶段;
- 第二个阶段是通过模型本身和ChatGPT一起创建高质量的图像文本对,这是一个小而高质量的数据集(共计3500个对)。然后在对话模板中使用这个数据集进行训练,显著提高了其生成可靠性和整体可用性;但是这个阶段的微调效率很高,一个A100在大约7分钟内就可以完成。
研究发现,MiniGPT-4具有许多与GPT-4类似的功能,比如生成详细的图像描述和从手写草稿创建网站。MiniGPT-4还有其他新兴功能,包括根据给定的图像撰写故事和诗歌,提供解决图像中显示的问题的方法,以及基于食品照片教用户如何烹饪等。
4.5、StabilityAI联合DeepFloyd发布最新的图片生成模型DeepFloyd IF
DeepFloyd IF是由DeepFloyd、StabilityAI和LAION三家协作开发的一个Text-to-Image模型。它使用的是与Google Imagen类似的架构完成的一个图片生成模型。
DeepFloyd IF是一个具有高度照片级别真实感和语言理解能力的新型最先进的开源文本到图像模型。官方宣称,该模型超过了Google的Imagen和Stable Diffusion。
4.6、其它多模态模型
此外,浙江大学发布了AudioGPT模型AudioGPT是一个旨在在口语对话中优秀理解和生成音频模态的系统。具体而言,
- AudioGPT利用各种音频基础模型处理复杂音频信息,而LLM(即ChatGPT)被视为通用接口,这使得AudioGPT能够解决众多音频理解和生成任务;
- AudioGPT不是训练口语语言模型,而是将LLM与输入/输出接口(ASR、TTS)连接以进行语音对话;
微软也发布了一个多模态大模型LLaVA,LLaVA全称Large Language and Vision Assistant,是由微软与威斯康星大学麦迪逊分校教授一起提出的一个多模态大模型。
五、附录:2023年4月份业界发布的重要模型列表
| SAM | 2023-04-05 | 计算机视觉 | 10 | 否 | Facebook AI研究实验室 |
| LVDM | 2023-04-06 | 多模态学习 | 0 | 是 | 腾讯AI实验室 |
| Vicuna-7B | 2023-04-07 | 自然语言处理 | 70 | 是 | LM-SYS |
| dolly-v2 | 2023-04-12 | 自然语言处理 | 120 | 否 | databricks |
| DINOv2 | 2023-04-14 | 计算机视觉 | 11 | 否 | Facebook AI研究实验室 |
| Stable Diffusion XL | 2023-04-14 | 多模态学习 | 23 | 否 | Stability AI |
| Whisper JAX | 2023-04-14 | 多模态学习 | 15.5 | 否 | 个人 |
| ControlNet-v1-1 | 2023-04-14 | 计算机视觉 | 0 | 是 | 个人 |
| MiniGPT-4 | 2023-04-16 | 多模态学习 | 130 | 否 | King Abdullah University of Science and Technology |
| LLaVA | 2023-04-17 | 多模态学习 | 650 | 否 | Microsoft |
| RedPajama-7B | 2023-04-17 | 自然语言处理 | 70 | 是 | TOGETHER |
| h2oGPT | 2023-04-19 | 自然语言处理 | 200 | 是 | H2O |
| StableLM | 2023-04-20 | 自然语言处理 | 1750 | 是 | Stability AI |
| AudioGPT | 2023-04-25 | 多模态学习 | 0 | 是 | 浙江大学 |
| HuggingChat | 2023-04-26 | 自然语言处理 | 300 | 是 | Hugging Face |
| Replit Code V1-3b | 2023-04-26 | 自然语言处理 | 27 | 是 | Replit |
| DeepFloyd IF | 2023-04-26 | 多模态学习 | 43 | 是 | Deep Floyd |
| Replit-finetuned-v1-3b | 2023-04-26 | 自然语言处理 | 27 | 否 | Replit |
| StableVicuna-13B | 2023-04-28 | 自然语言处理 | 130 | 是 | Stability AI |
| FastChat-T5 | 2023-04-29 | 自然语言处理 | 30 | 是 | LM-SYS |
2023年4月业界发布的重要20多个AI模型总结:OpenAssistant、Segment Anything Model、StableLM、AudioGPT等 | DataLearnerAI