Google反击OpenAI的大杀器!下一代语言模型PaLM 2:增加模型参数并不是提高大模型唯一的路径!
Google在今年的I/O 2023大会上宣布了他们家下一代大语言模型:PaLM 2。这是Google反击OpenAI最强大的一个武器。PaLM是谷歌在2022年4月份发布的5400亿参数规模的大模型,也是Google Bard的底层模型。只是当时推出的时候与GPT-4差距太大而被吐槽。

作为PaLM的继任者,PaLM2的发布被谷歌寄予厚望。与OpenAI类似,谷歌官方没有透露很多关于模型的技术细节,虽然发布了一个92页的技术报告,但是,正文内容仅仅27页,引用和作者14页,剩余51页都是展示大量的测试结果。而前面的27页内容中也没有过多的细节描述。尽管如此,这里面依然有几个十分重要的结论供大家参考。
简要的结论如下:
- PaLM2支持一百多种语言
- PaLM2的模型参数比PaLM更小,但是能力更强
- PaLM2与GPT-4相比很有竞争力
- PaLM2有多个版本,最小的版本可以在移动端离线使用
下面是本文对PaLM2的详细分析:
PaLM2的改进
根据技术文档中透露的内容,PaLM2最大的改进包含4个方面,分别是架构改进、多语言的支持、更加高效以及能力更强。
- 架构的改进:PaLM2模型依然是基于transformer的架构。不过,相比之前的单一的因果或masked语言建模目标,PaLM2采用了UL2的思想(UL2是谷歌尝试的一种与GPT-3、PaLM不同的大语言模型路径,参考DataLearner关于UL2的模型卡信息:https://www.datalearner.com/ai-models/pretrained-models/UL2 ),使用了不同的预训练目标的混合,以训练模型理解语言的不同方面。
- 多语言的支持:PaLM第一代模型主要基于英文语料训练(非代码数据中英文语料占比78%),对于其它语言的支持不好(难怪Google Bard一直只支持英文~)。而PaLM2则是基于超过100种语言的语料进行训练,对多语言的支持很强大。
- 更加高效:相比较第一代的PaLM模型(5400亿参数),Google没有选择继续扩大模型的规模,反而重新设计了架构,让PaLM 2模型的参数规模远低于PaLM第一代。但是,PaLM2的效果却更好。这样做最大的好处是降低了部署成本,也会速度更快。这一点从Google Bard最近的表现也可以看出来,Google Bard回答的结果非常快,而且很多时候是直接给出一大段答案。
- 更强大的能力:除了在多语言语料中训练,PaLM2也在多个领域的数据集上做了训练,包括程序代码、数学等领域。因此,PaLM2更加强大,可以胜任更多领域的任务,包括自然语言生成、翻译、推理等。
PaLM2的训练数据集
PaLM2是在大规模文本数据集和代码数据集上训练的。尽管官方没有透露具体的训练数据,但是Google也说明了。相比较PaLM第一代,PaLM2使用的数据集规模大很多。并且,非英文的数据集比例也更高。
PaLM 2还使用涵盖数百种语言的平行数据进行训练,进一步提高了其理解和生成多语言文本的能力。因此,在翻译或者多语言理解能力上也是强很多。
去除英文语料之后,具体使用的不同语言的数据集如下表:
可以看到,除了英文外,使用最多的是西班牙语,其次是中文,再次是俄语。这个很有意思啊~不知道为啥前三是这三个。
除了更大的数据集和包含平行多语言数据之外,PaLM 2还被训练以显著增加模型的上下文长度,超出了PaLM的长度。这种改进对于实现长对话、长距离推理和理解、摘要和其他需要模型考虑大量上下文的任务至关重要。
PaLM2模型的参数规模实验
除了上面的内容外,PaLM2技术报告中最有价值的可能就是关于模型缩放规律的讨论了。
如前所述,PaLM模型参数规模维5400亿。PaLM 2系列中最大的模型PaLM 2-L比最大的PaLM模型小得多,但使用了更多的训练计算资源。评估结果显示,PaLM 2模型在包括自然语言生成、翻译和推理在内的各种任务中明显优于PaLM。这些结果表明,仅靠模型扩展并不是提高性能的唯一途径。相反,通过精心的数据选择和高效的架构/目标,可以实现性能的提升。此外,一个更小但更高质量的模型显著提高了推理效率,降低了服务成本,并使该模型在更多应用和用户中可以实现下游应用。
在2020年,由Kaplan等人发表的经典论文《Scaling laws for neural language models》研究了训练数据量(D)和模型大小(N)的扩展关系,并得出了经验结论,即其遵循幂律,N需要比D增长得更快。Hoffmann等人(2022)在这一观察结果的基础上进行了类似的研究,调整了较小模型的超参数。他们的结果证实了Kaplan等人(2020)的幂律结论,但在优化比例方面得出了不同的结果,显示N和D应该以相等的比例增长。
而Google独立地推导了大模型的扩展定律。得出了与Hoffmann等人(2022)类似的结论,即随着FLOPs预算的增加,D和N应该以相等的比例增长!下图是一个测试结果:
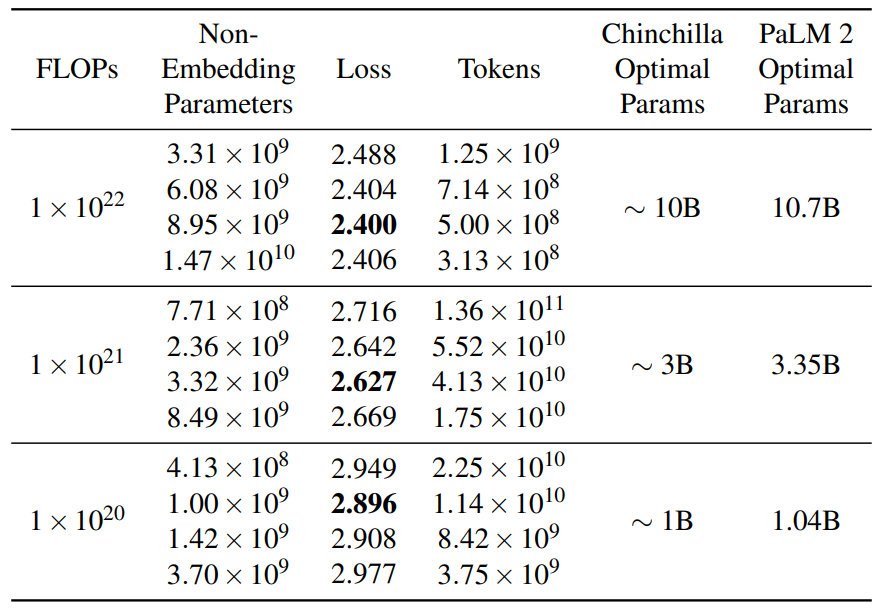
Google在给定FLOPs的情况下,基于参数D和训练tokens N组合寻找最优的模型设置。结果可以看到,最低loss是由大约遵循给定 FLOPs 的最佳模型参数 (D) 的模型所实现的。
PaLM2的评价
首先,与PaLM相比,PaLM2各方面都改进巨大。即使是PaLM2系列中小规模参数版本,效果也很不错。
下图是PaLM2系列与PaLM在多语言能力的对比。
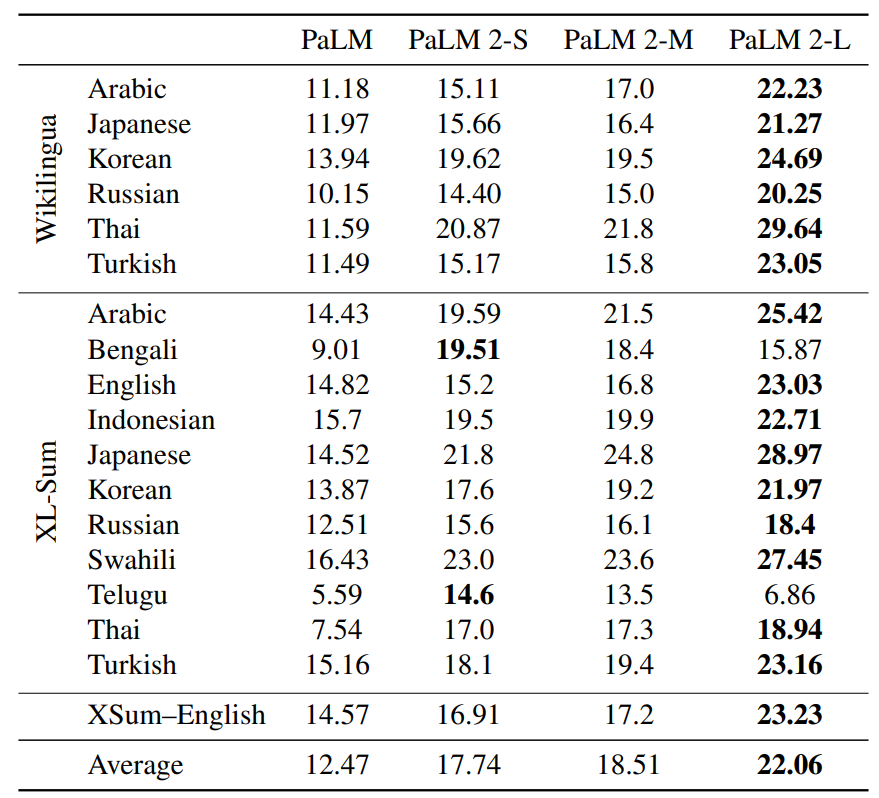
当然,在其它领域也有类似的结果。
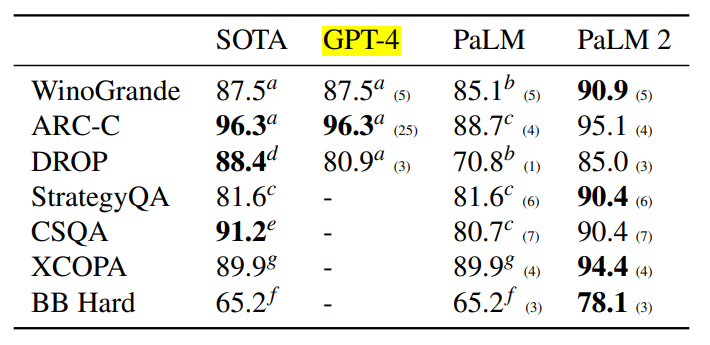
有意思的是官方说明了,即使与GPT-4相比,PaLM也是非常有竞争力的。
首先,PaLM2的推理能力要比GPT-4强~
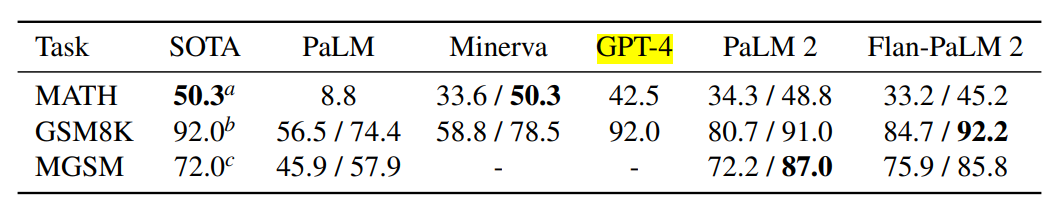
其次,PaLM2的Flan版本在数学方面要比GPT-4强~
最后,在编程方面,PaLM2的编程能力比GPT-4差很多!。下图是Google技术报告中PaLM2编程得分:


不过,PaLM-S是个参数比较小的模型。不能完全按照上图比较。但是,官方没有其它的对比。
PaLM2的小规模版本的低资源消耗
即使PaLM 2更强大,它也比以前的模型更快、更高效,而且有各种尺寸可供选择,因此可以轻松部署在广泛的用例中。Google提供四种不同大小的PaLM 2模型:Gecko、Otter、Bison和Unicorn。Gecko非常轻量级,可以在移动设备上使用,并且即使在离线状态下,也足够快速以支持良好的交互式应用程序!
这种移动端可离线使用的才是PaLM2显著区别GPT-4的优点!
另外,Google也会提供模型的API版本调用,目前已经出了chat-bison-001,价格是0.0005美元/1000个characters,如果一个token是4个characters,那么价格就是0.002美元/1000个tokens,与gpt-3.5-turbo一样。
PaLM2的模型卡信息:https://www.datalearner.com/ai-models/pretrained-models/PaLM-2 PaLM2的技术文档地址:https://ai.google/static/documents/palm2techreport.pdf
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
