解决大语言模型的长输入限制:MetaAI发布MegaByte最高支持几百万上下文输入!
尽管OpenAI的ChatGPT很火爆,但是这类大语言模型有一个非常严重的问题就是对输入的内容长度有着很大的限制。例如,ChatGPT-3.5的输入限制是4096个tokens。MetaAI在前几天提交了一个论文,提出了MegaByte方法,几乎可以让模型接受任意长度的限制!

本文将简单介绍这个方法!论文名称:《MEGABYTE: Predicting Million-byte Sequences with Multiscale Transformers》。
transformer模型的输入限制问题
尽管目前的大语言模型在较短序列(几千个tokens以内)的应用场景下有着惊人的效果,但是数百万序列的输入依然是一种刚需,包括音乐、图片、视频、小说、代码等,它们的输入长度通常都是远远超过当前大语言模型的输入限制。主要原因是自注意力机制的“成本”随着输入成二次方增长,以及每个位置都需要计算大型的前馈网络。
借用Raimi Karim博客里面的示意图如下:
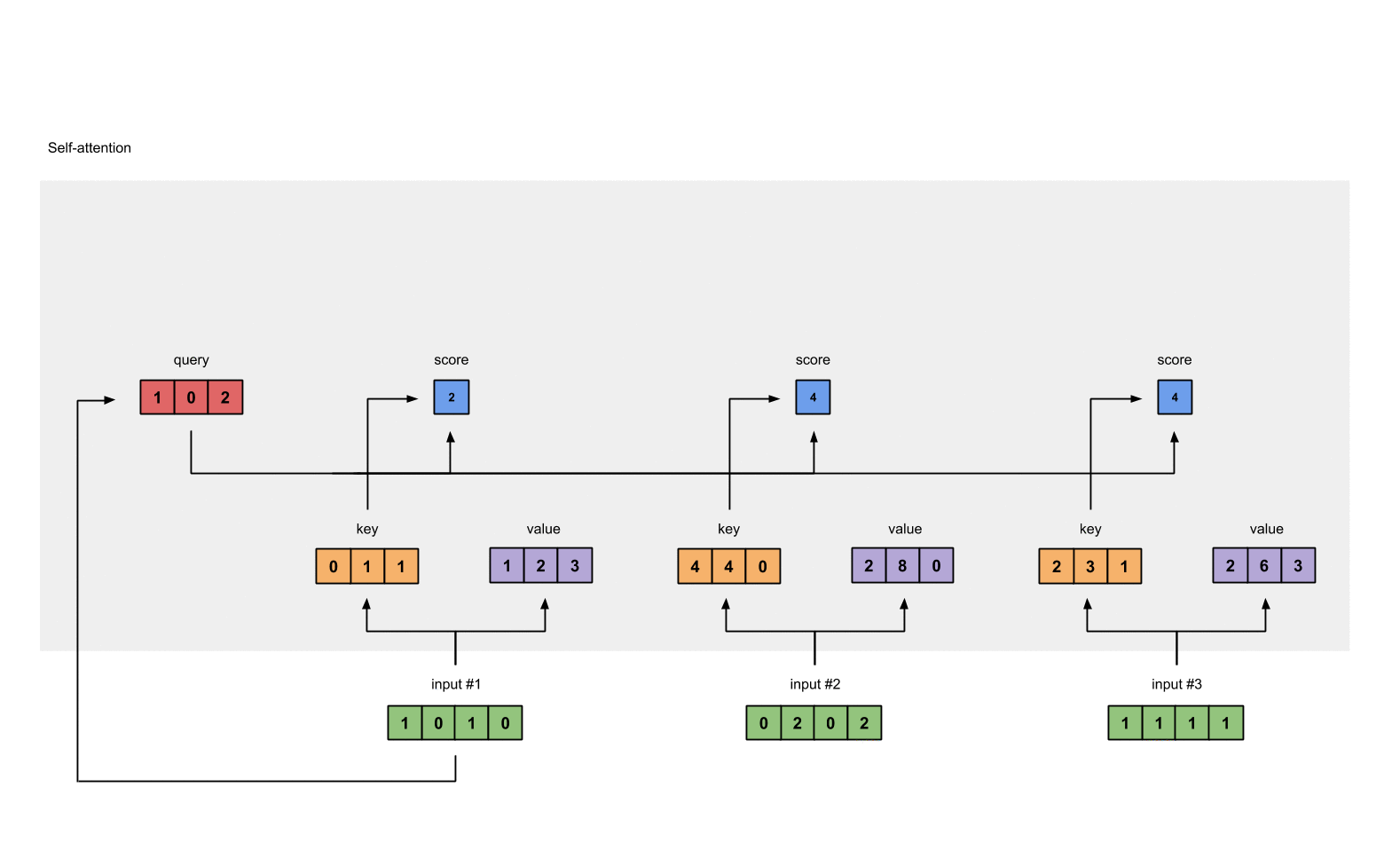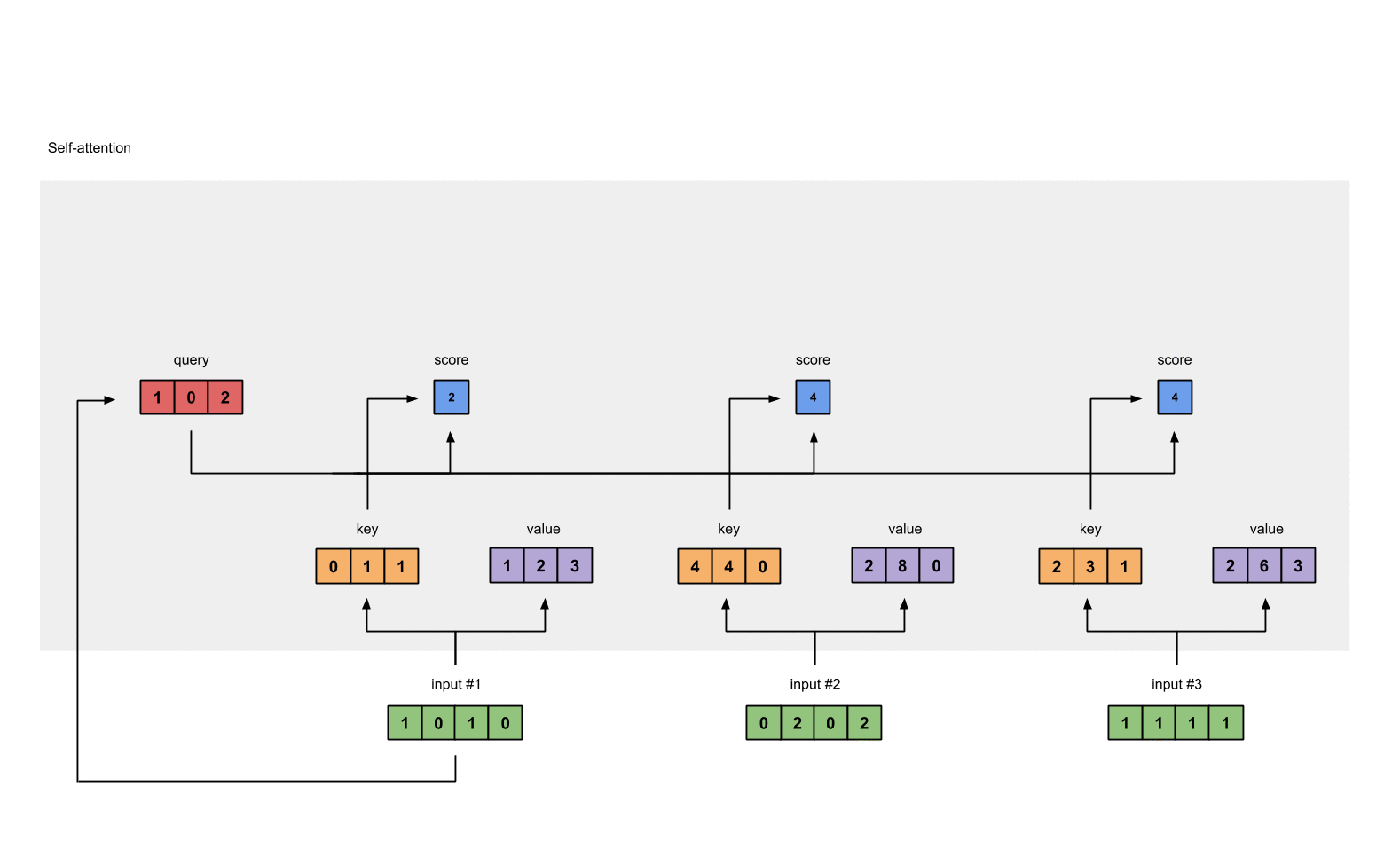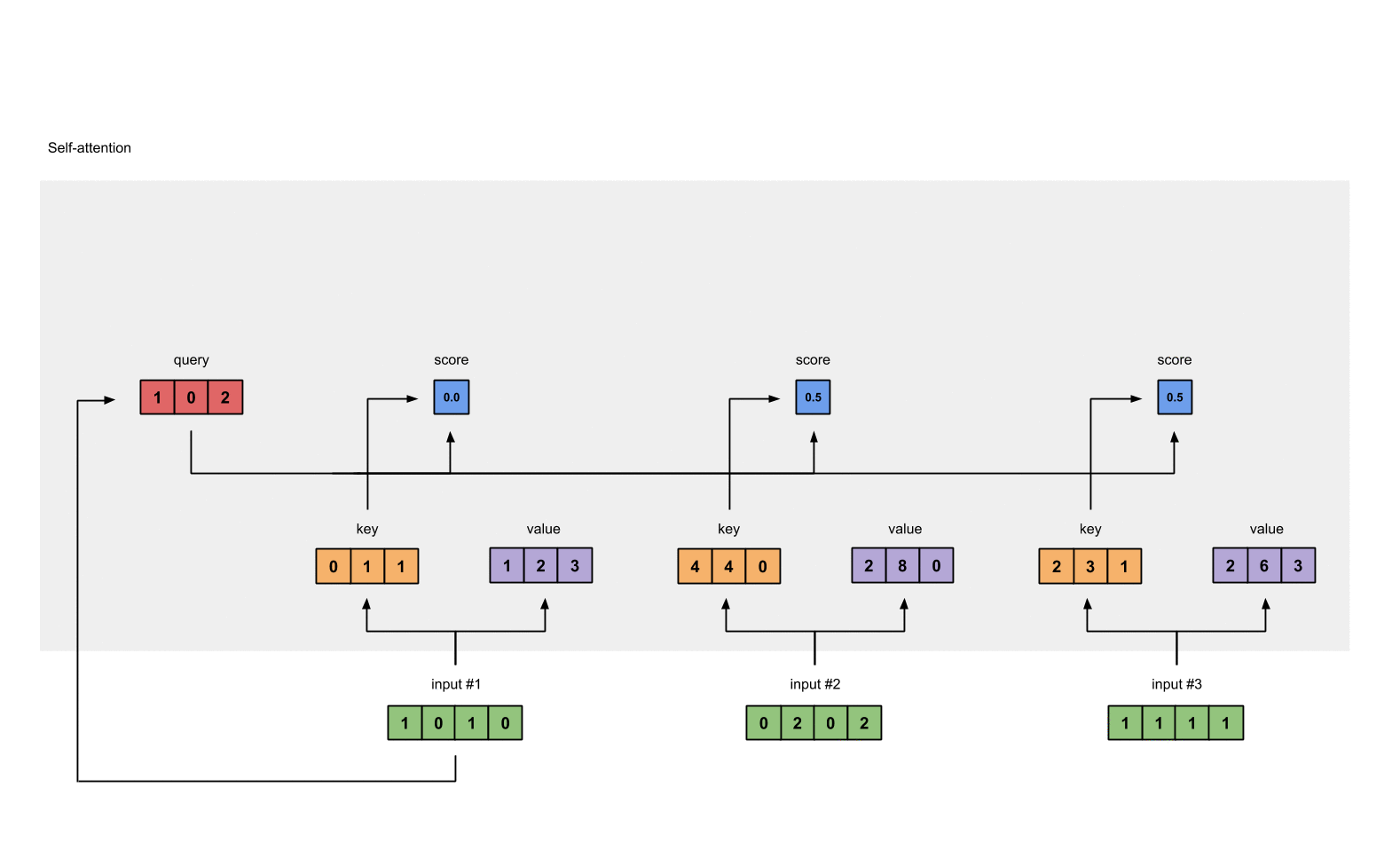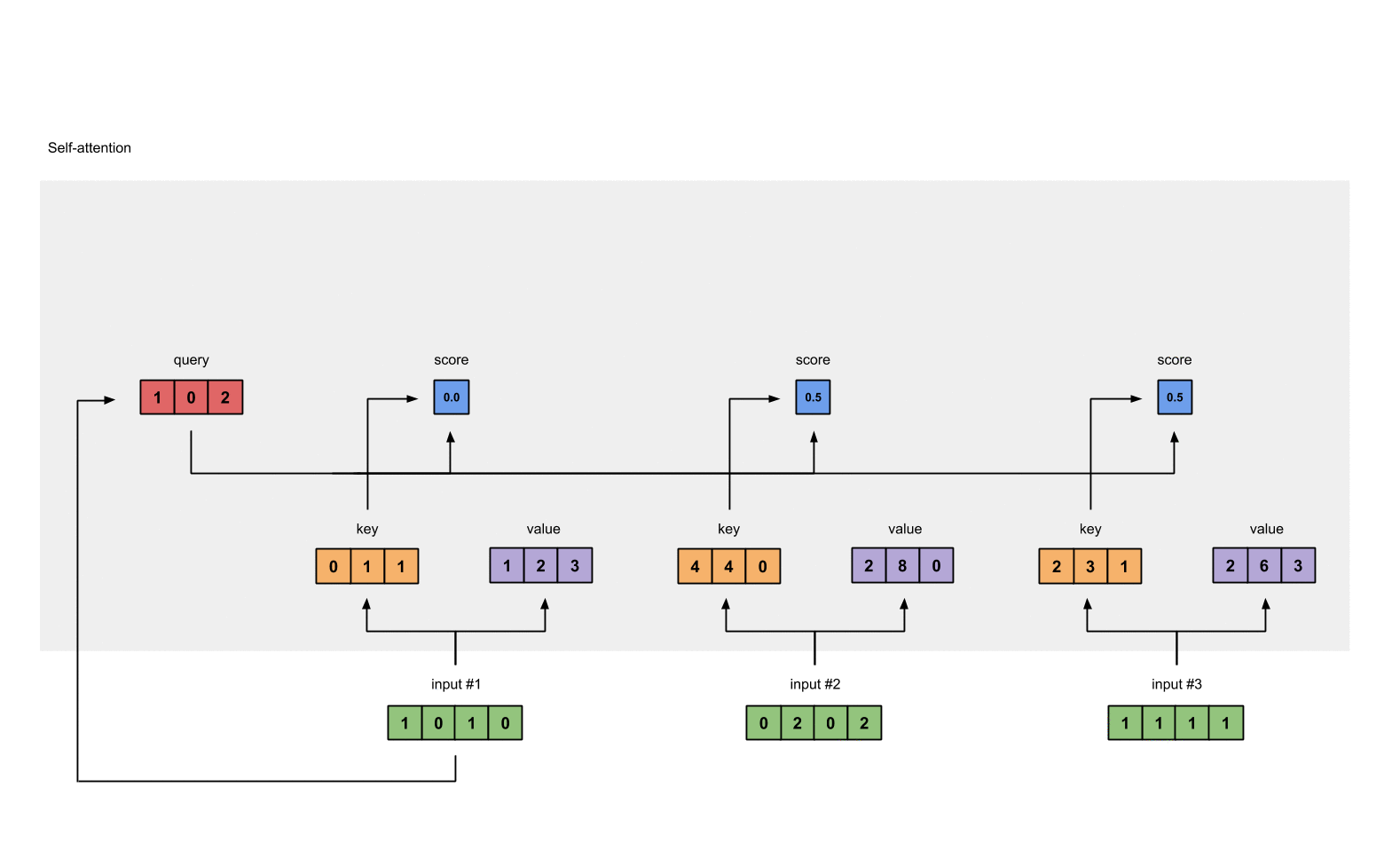
可以看到,在自注意力计算中,输入序列的每一个位置都要与其它位置计算得分,因此,对于输入为$n$的transformer模型来说,它的计算复杂度是$\mathcal{O}(n^2)$。尽管之前也有很多方法提出了一些很有效率的注意力机制,但是长序列建模最大的问题其实是每个位置都要计算巨大的前馈网络。这是其中最费时间的!
而本次MetaAI提出的这个方法,计算复杂度只有$\mathcal{O}(n^{4/3})$。其未来的应用前景巨大!
MetaByte核心思想简介
为了解决当前transformer模型对输入的限制,MetaAI提出的MetaByte引入了一个概念,称为patch,将模型的输入序列分割成固定大小的patches,这是一个类似于token的概念,但是显然比token覆盖的范围要宽。然后通过一个全局的模块,建立一个大的自回归transformer,把输入和输出从tokens变成patches。同时,引入了一个本地的模块,用于每个patch内部的字节的预测,其输入是从全局模块来的上下文patches表示结果,输出是预测下一个patch,这是一个小的自回归模型。
上述思想可以用下图表示:
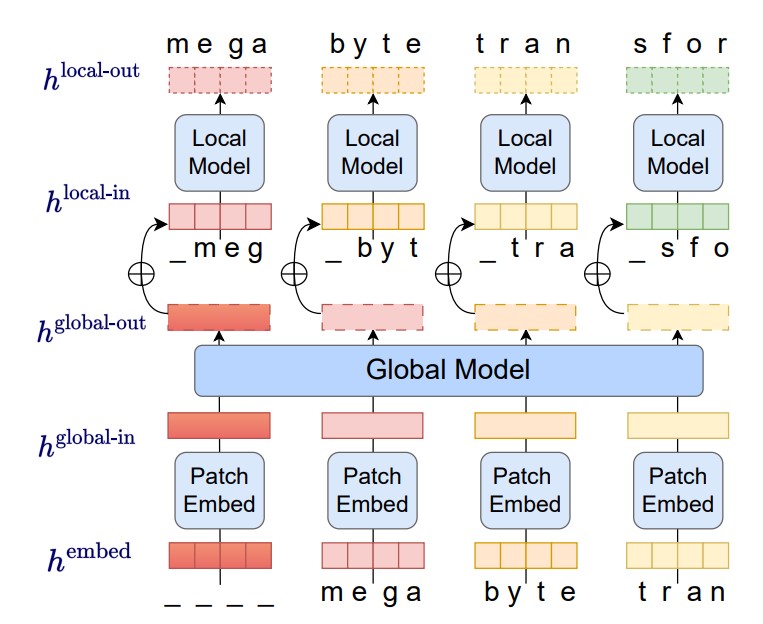
可以看到,MetaByte的输入就是patch,然后对每一个patch做embedding,将patch的embedding结果输入到全局模块(一个自回归transformer网络),它的输出继续作为本地模块的输入,即用一个个小的自回归transformer继续向前计算,得到结果。
这个方法与当前transformer模型还有一个最重要的区别是不需要做tokenization!这是一个非常重要的特性。tokenization是当前大语言模型的一种通用做法,尽管tokens相比较单词具有更好的一致性,处理起来更加容易。但是,Tokenization意味着LLMs实际上不是完全的端到端。还有一个完全不同的阶段,有自己的训练和推理,并且需要额外的库。它使得引入其他模态变得复杂。
Tokenization还具有许多微妙的问题,以如下的图为例,GPT-3模型能力很强,但是在简单的单词反转问题上却出错了。
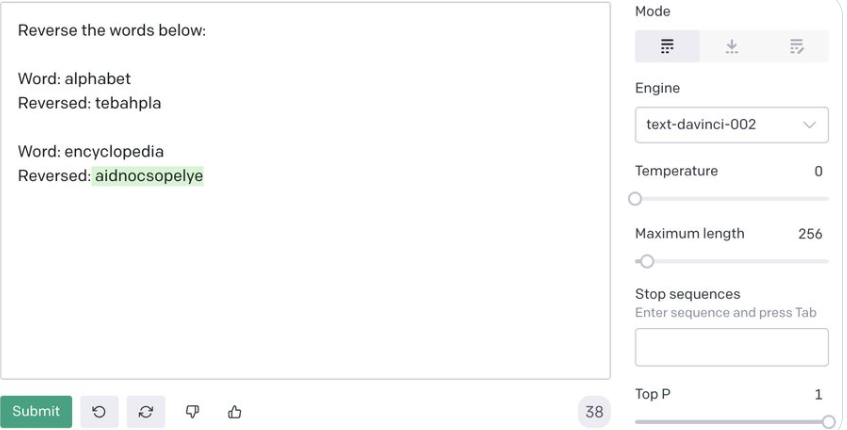
原因大概就是GPT-3看单词是以token的视角来的,alphabet在GPT-3看来是 alph和abet。该案例来自:https://twitter.com/npew/status/1525900849888866307
总结一下,MetaByte相比现有的transformer模型的差异为:
- 大多数优化长序列输入的模型都是关注减少自注意力机制的二次方成本上,而MetaByte将长序列分解为两个较短的序列,并通过优化patch大小将自注意力成本降至O(n^{4/3}),这仍然适用于长序列。
- 在GPT-3这样大小的模型上,98%的计算都是在做基于位置的前馈网络,而MetaByte计算的是基于patch的前馈网络。Patch的大小如果是P,那么它的计算效率就是同等规模模型的P倍。
- Transformers在生成过程中必须按照顺序生成。而MetaByte可以针对patches做并行的生成。例如,15亿参数的MetaByte生成速度比3.5亿参数规模的transformer模型还要快40%!
MetaByte的测试结果
MetaAI在论文中放出了很多测试结果。我们挑选几个具有代表性的结果给大家展示一下:
首先是训练的计算量对比:
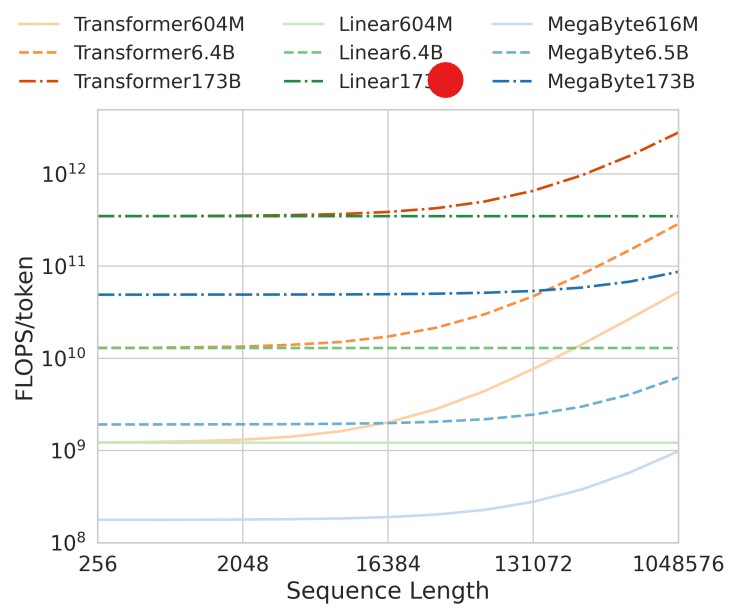
在不同规模的模型上,随着输入序列的增加,MetaByte的计算量几乎不变,增长远低于同等规模的transformer模型和线性transformer。
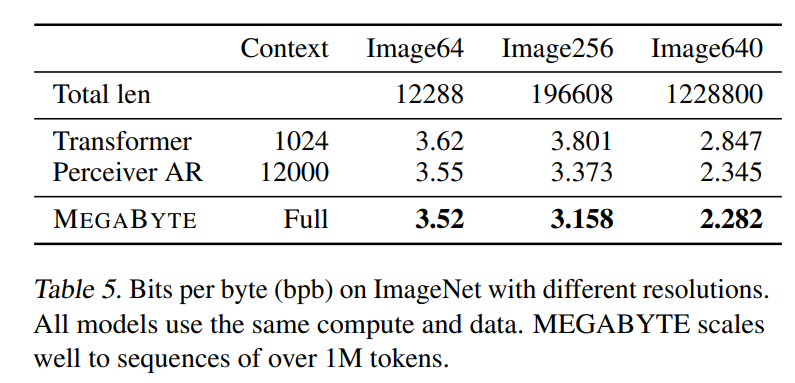
还有一个是ImageNet的bpb测试。
MetaByte的总结
MetaAI这项工作引起了很多人的注意。个人觉得MetaByte的最大的价值有2个:一个是将大语言模型的上下文限制能力大大拓展,按照论文的描述,可以支持到数百万的字节输入,这几乎是目前常规大语言模型的几百倍,也远超过前几天ClaudeAI-100k和GPT-4-32k,几乎可以解决当下大部分输入限制问题。而另一个最大的优点是没有tokenization,几乎可以完成一个端到端的transformer模型。
这个模型应该很快就会有开源实现跟进,到时候我们应该就可以看到它真正的威力。
不过,开源速度就是快,已经有老兄基于PyTorch实现了这个算法了:https://github.com/lucidrains/MEGABYTE-pytorch。难怪谷歌前段时间泄露的文件说谷歌和OpenAI最终可能都打不过开源,这速度真的是厉害!
