ChatGLM-6B升级!清华大学开源VisualGLM-6B:一个可以在本地运行的读懂图片的语言模型!
ChatGLM-6B是清华大学知识工程和数据挖掘小组(Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University)发布的一个开源的对话机器人。因其良好的性能和较低的部署成本,在国内受到了广泛的关注和好评。今天,THUDM开源了ChatGLM-6B的多模态升级版模型VisualGLM-6B。这是一个多模态对话语言模型,支持图像、中文和英文。
VisualGLM-6B在DataLearner模型卡的信息:https://www.datalearner.com/ai-models/pretrained-models/VisualGLM-6B
VisualGLM-6B模型简介
VisualGLM-6B是由语言模型ChatGLM-6B( https://www.datalearner.com/ai-models/pretrained-models/ChatGLM-6B )与图像模型BLP2-Qformer结合而得到的一个多模态大模型,二者结合后的参数为78亿(62亿+16亿)。
VisualGLM-6B的特别之处在于它能够整合视觉和语言信息。可以用来理解图片,解析图片内容。
该模型依赖于CogView数据集中3000万个高质量的中文图像-文本对,以及3亿个精选的英文图像-文本对进行预训练。这种方法使视觉信息能够很好地与ChatGLM的语义空间对齐。在微调阶段,该模型在长视觉问答数据集上进行训练,以生成符合人类偏好的答案。
VisualGLM-6B模型的技术细节
关于VisualGM-6B的具体技术信息如下:
VisualGLM-6B最令人兴奋的一个方面是其可访问性。由于集成了模型量化技术,用户可以在消费级显卡上本地部署模型,INT4量化级别只需要8.7G的显存。这意味着即使是拥有游戏笔记本的用户也可以快速且私密地部署这个模型,这在此类大小的ChatGPT-like模型中尚属首次。
VisualGLM-6B的运行硬件要求也还可以,FP16精度的模型需要15GB显存运行,而INT4量化版本需要8.7GB显存,比纯对话的ChatGLM-6B要求稍高。具体对比如下:
量化版本的模型支持CPU部署哦~
VisualGLM的局限性
尽管VisualGLM-6B是一项重大的成就,但它仍处于v1版本,并且已知存在一些限制,例如图像描述中的事实/幻觉问题、对图像细节信息的捕捉不足,以及一些来自语言模型的限制。然而,这些问题预计将成为未来VisualGLM版本优化的重点。
根据测试,这个模型可以对输入的图片进行理解,但是对图片的文本内容理解不太好,也无法生成图片。
VisualGLM-6B模型的实际测试结果
官方在HuggingFace上部署了一套VisualGLM-6B的模型供大家测试。模型对图片的解析速度很快,问答返回结果也很不错。
测试案例1:创意图片理解
下图是我通过Stable Diffusion XL生成的一个图片,用的prompt是“vicuna walking in the city”。可以看到,VisualGLM-6B对模型的理解十分准确:
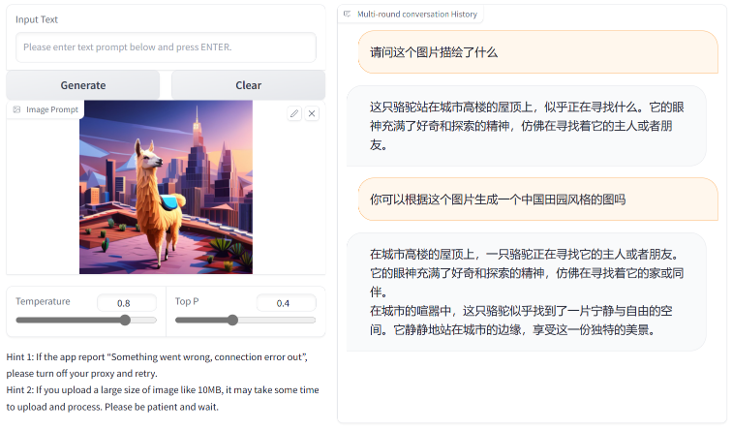
不过可惜的是它无法生成图片。
测试案例2:表格图片理解
接下来我测试了一个表格数据,这次VisualGLM-6B的理解虽然不错,但是内容识别就很差了。
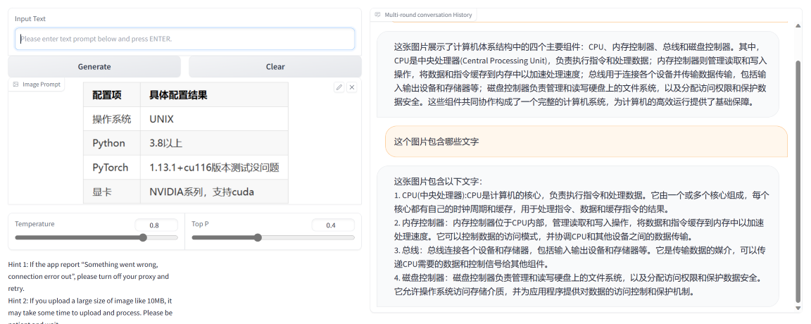
可以看到,尽管VisualGLM-6B知道这是一段描述配置,但是却没有理解或者没有解析正确里面的文字,这可能是与它的目的是理解图片而不是文本有关。
VisualGLM-6B的开源协议情况
需要注意的是,尽管VisualGLM-6B模型代码与预训练结果都是开源的,不过预训练结果的权重依然是不可以商用!
VisualGLM-6B的代码开源协议是Apache-2.0 license,没有啥限制,但是其模型的预训练权重的开源协议是THUDM自己定义的协议。
You will not use, copy, modify, merge, publish, distribute, reproduce, or create derivative works of the Software, in whole or in part, for any commercial, military, or illegal purposes.
关于VisualGLM-6B的本地部署教程我们将在后续提供!
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
