GPT4All:一个可以直接在本地运行各大商业友好的开源大模型解决方案
----------------2023年7月15日GPT4All增加支持embedding能力---------------- 2023年7月15日,NomicAI官方宣布最新版的GPT4All支持embedding模型,只需要1G内存即可运行: https://www.datalearner.com/blog/1051684590410303
**-------------------2023年6月1日GPT4All更新支持读取本地文档----------------------- ** 2023年6月1日,NomicAI官方宣布最新版的GPT4All支持加载本地文档,然后根据本地文档读取内容,使用不同的大模型来针对这个文档进行问答! **-------------------2023年6月1日GPT4All更新支持读取本地文档----------------------- **
大型语言模型如GPT-4,Google Bard等正在引领新一轮的技术革新。这些模型在许多任务中都表现出强大的性能,包括文本生成,情感分析,文本理解等。然而,使用这些大型语言模型往往需要联网访问,依赖于强大的GPU计算能力,且成本高昂,这给普通用户和小型开发团队带来了巨大的挑战。
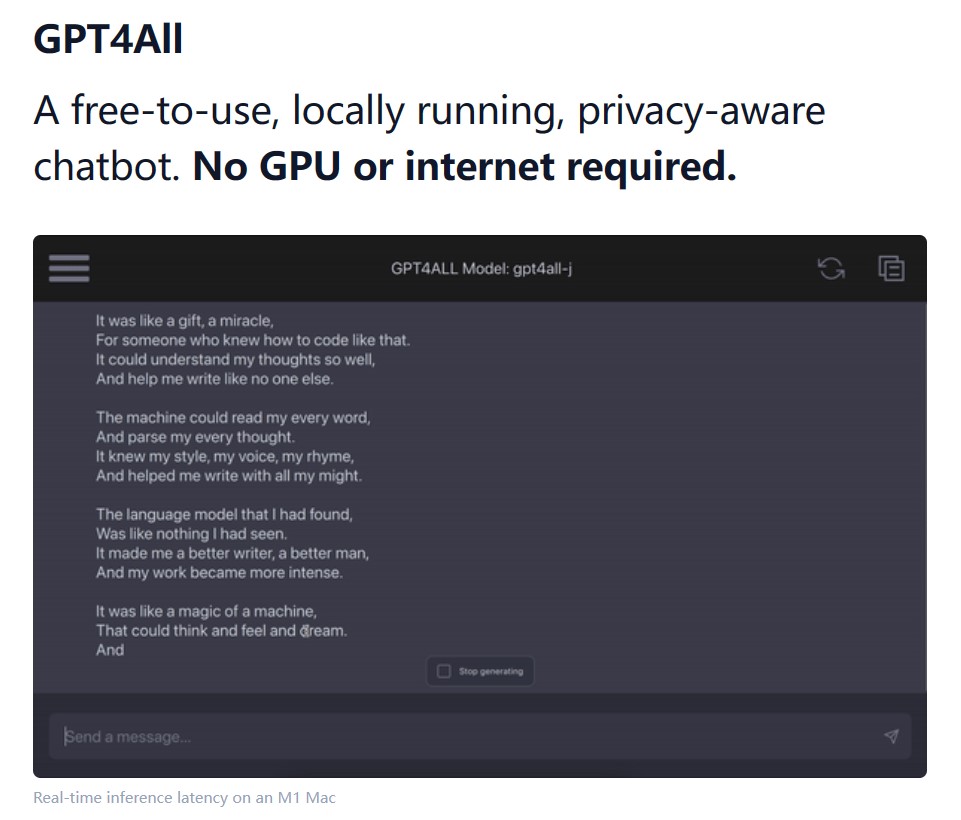
为此,NomicAI推出了GPT4All这款软件,它是一款可以在本地运行各种开源大语言模型的软件,即使只有CPU也可以运行目前最强大的开源模型。GPT4All将大型语言模型的强大能力带到普通用户的电脑上,无需联网,无需昂贵的硬件,只需几个简单的步骤,你就可以使用当前业界最强大的开源模型。
总结一下,GPT4All的特点如下:
- 多系统支持,目前可以在Windows、Mac/OSX以及Ubuntu上直接安装使用哦~
- 本地运行,无需联网
- 支持CPU运行,即使是老的只包含AVX指令集的CPU都可以
- 方便使用,它有一个非常友好的用户界面,让加载模型和使用的很方便
- 支持各种模型:目前已经支持13款开源模型和基于OpenAI APIkey的方式使用GPT-3.5和GPT-4(这个需要联网)
在接下来的文章中,我们将深入探讨GPT4All的优点,如何使用它,以及它支持哪些模型,由于官方的模型下载比较慢,本文也提供了下载链接,大家可以直接使用表格中提供的链接用下载工具下载即可,更加方便。
GPT4All的发展历史和简介
2023年3月29日,NomicAI公司宣布了GPT4All模型。此时,GPT4All还是一个大语言模型。如今,随着NomicAI运营思路的转变,GPT4All已经是一个专注于在本地运行开源模型的软件了。
如下图所示:
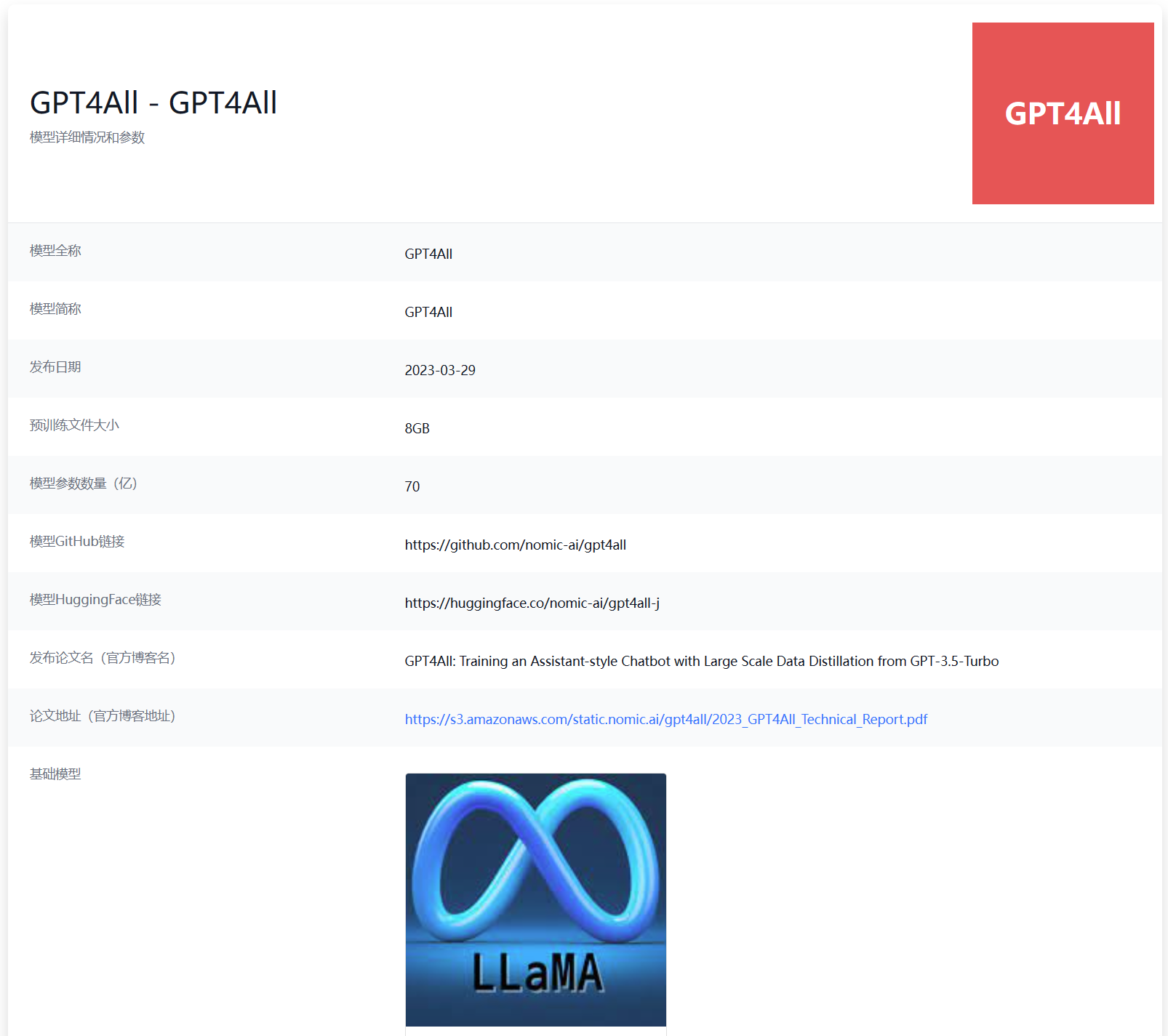
GPT4All在DataLearner上的模型卡信息:https://www.datalearner.com/ai-models/pretrained-models/GPT4All
NomicAI发布的所有模型:
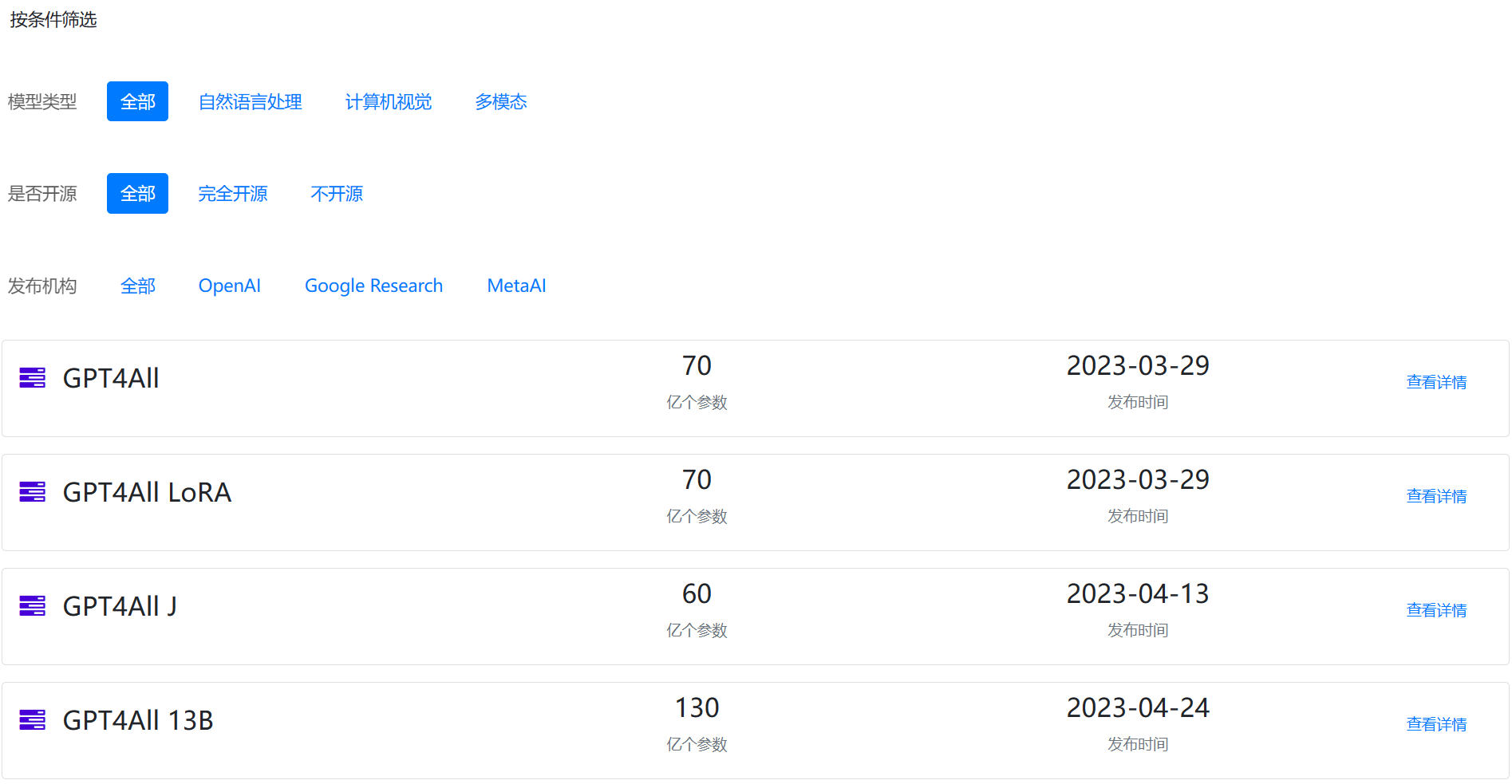
3月底才发布的时候,GPT4All还是基于MetaAI开源的LLaMA微调得到的大模型。其最大的特点是开源,并且其4-bit量化版本可以在CPU上运行!同时,因为NomicAI精心挑选了80万的 prompt-response对进行微调训练,因此其效果十分好!
此后,NomicAI分别发布了5个相关的模型:
上述五个模型中,基于GPL的都是来自MetaAI开源LLaMA模型微调的结果,不可商用的模型,且开源要求高。而剩余2个则是可以商用的。
GPT4All:一个本地运行“ChatGPT-Like”模型的软件
4月13日,NomicAI官宣GPT4All-J,这是一个可以在本地运行的大语言模型,但是是基于GPT-J微调的结果。由于GPT-J是EleutherAI公司自己训练的模型,开源协议友好,因此GPT4All-J变成了一个完全开源可商用的模型。
同时发布的还有一个可以在本地安装的软件包。这就是我们今天介绍的主角:GPT4All。
GPT4All现在已经是一个完全独立的安装软件,支持Windows、Mac/OSX和Ubuntu三个系统。直接下载安装之后就可以得到如下界面:
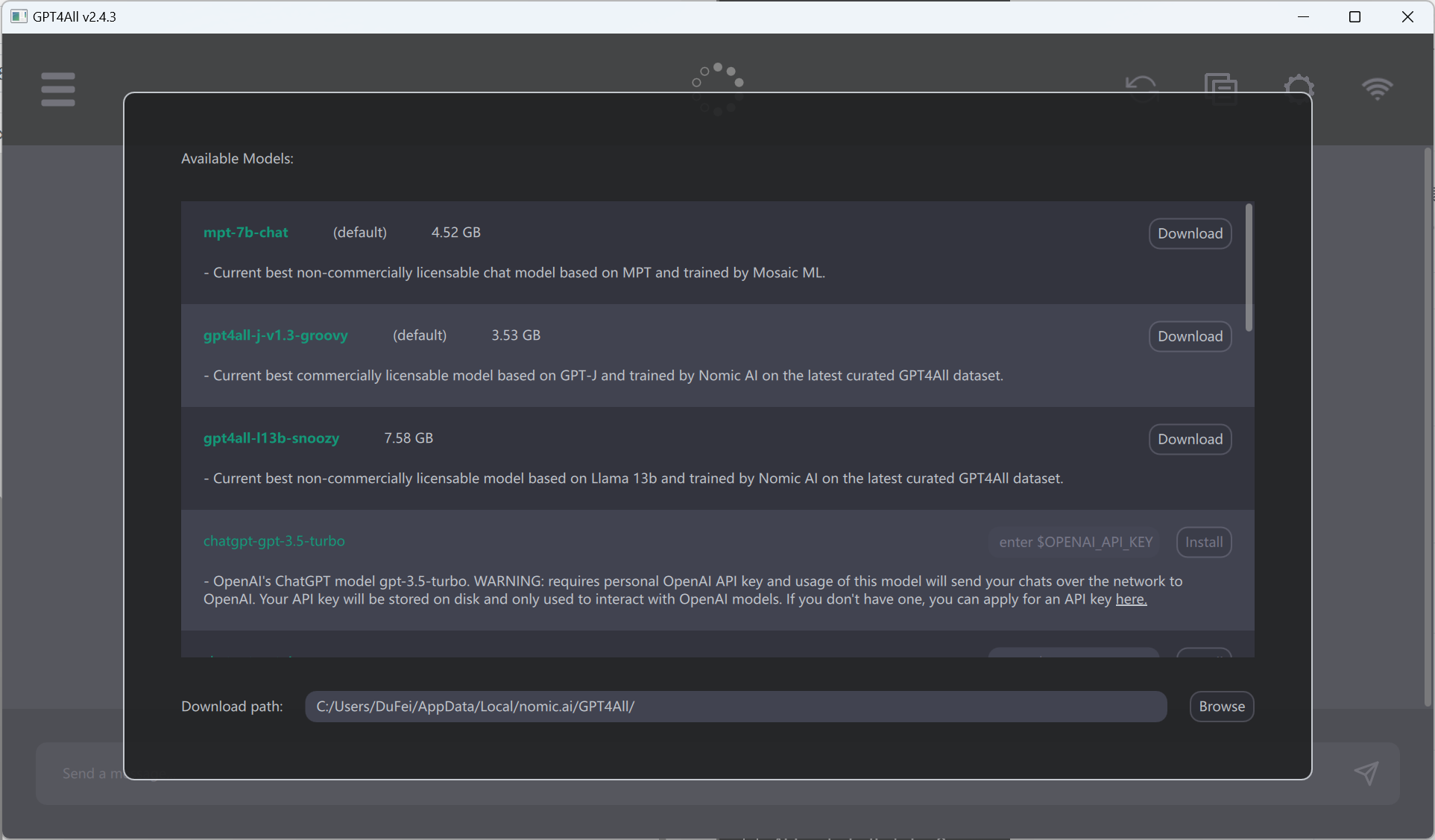
可以看到,里面提供了很多的开源可商用的模型给大家使用,大家按需下载之后选择即可。当然,也支持OpenAI的API Key来使用GPT-3.5和GPT-4。接下来就是一个聊天框了,可以根据需要选择不同的模型进行对话:
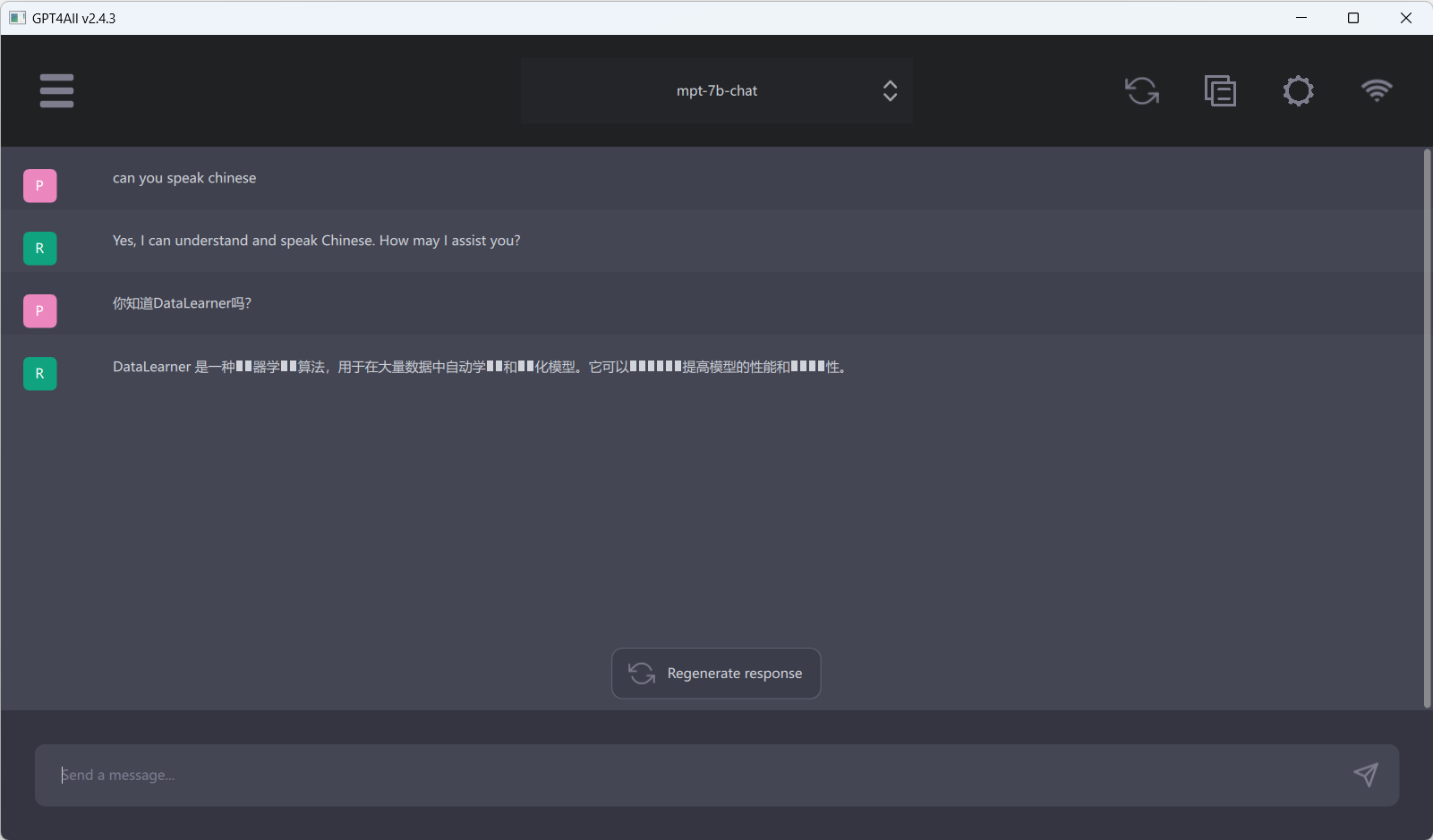
这就是我测试的结果,不过中文这“口”不知道是训练数据出了问题还是软件有bug……
GPT4All软件有很多优点,其中最突出的几个特点是:
- 多系统支持,目前可以在Windows、Mac/OSX以及Ubuntu上直接安装使用哦~
- 本地运行,无需联网
- 支持CPU运行,即使是老的只包含AVX指令集的CPU都可以
- 方便使用,它有一个非常友好的用户界面,让加载模型和使用的很方便
- 支持各种模型:目前已经支持13款开源模型和基于OpenAI APIkey的方式使用GPT-3.5和GPT-4(这个需要联网)
GPT4All支持的模型
GPT4All官方提供了很多可以下载后直接使用的二进制模型,不过,通过这个软件下载的话,模型可能比较慢,建议大家可以获得真实地址采用其它方式下载到指定的位置后重启GPT4All即可。我们这里已经列举出了GPT4All支持的所有的模型以及是否可以商用的结果。
显然,开源模型中,如果是基于MetaAI开源的LLaMA进行微调,那都是不可以商用的。这是因为MetaAI本身的限制。
2023年7月15日更新的GPT4All支持的所有模型如下:
|模型名称|参数数量|量化方式|文件大小|基础模型|内存要求|下载地址| |---------|---------|---------|---------|---------|---------| |Wizard v1.1|130亿|4bit量化(q4_0)|6.82GB|LLaMA|16GB|下载地址(DataLearner整理) |GPT4All Falcon|70亿|4bit量化(q4_0)|3.78GB|Falcon|8GB|下载地址(DataLearner整理) |Hermes|130亿|4bit量化(q4_0)|7.58GB|LLaMA|16GB|下载地址(DataLearner整理) |Groovy|70亿|4bit量化(q4_0)|3.53GB|GPT-J|8GB|下载地址(DataLearner整理) |Snoozy|130亿|4bit量化(q4_0)|7.58GB|LLaMA|16GB|下载地址(DataLearner整理) |MPT Chat|70亿|4bit量化(q4_0)|4.52GB|MPT|8GB|下载地址(DataLearner整理) |Mini Orca|70亿|4bit量化(q4_0)|3.53GB|OpenLLaMa|8GB|下载地址(DataLearner整理) |Mini Orca (Small)|30亿|4bit量化(q4_0)|1.8GB|OpenLLaMa|4GB|下载地址(DataLearner整理) |Mini Orca (Large)|130亿|4bit量化(q4_0)|6.82GB|OpenLLaMa|16GB|下载地址(DataLearner整理) |Vicuna|70亿|4bit量化(q4_2)|3.92GB|LLaMA|8GB|下载地址(DataLearner整理) |Vicuna (large)|130亿|4bit量化(q4_2)|7.58GB|LLaMA|16GB|下载地址(DataLearner整理) |Wizard|70亿|4bit量化(q4_2)|3.92GB|LLaMA|8GB|下载地址(DataLearner整理) |Stable Vicuna|130亿|4bit量化(q4_2)|7.58GB|LLaMA|16GB|下载地址(DataLearner整理) |MPT Instruct|70亿|4bit量化(q4_0)|4.52GB|MPT|8GB|下载地址(DataLearner整理) |MPT Base|70亿|4bit量化(q4_0)|4.52GB|MPT|8GB|下载地址(DataLearner整理) |Nous Vicuna|130亿|4bit量化(q4_0)|7.58GB|LLaMA|16GB|下载地址(DataLearner整理) |Wizard Uncensored|130亿|4bit量化(q4_0)|7.58GB|LLaMA|16GB|下载地址(DataLearner整理) |Replit|30亿|f16(无量化)|4.84GB|Replit|4GB|下载地址(DataLearner整理) |Bert|1百万|f16(无量化)|0.04GB|Bert|1GB|下载地址(DataLearner整理)
GPT4All支持对本地文档读取和解析
在2023年6月1日的更新上,GPT4All增加了一个插件能力,即读取本地文档解析。只需要在设置中,选择你的文档目录即可:
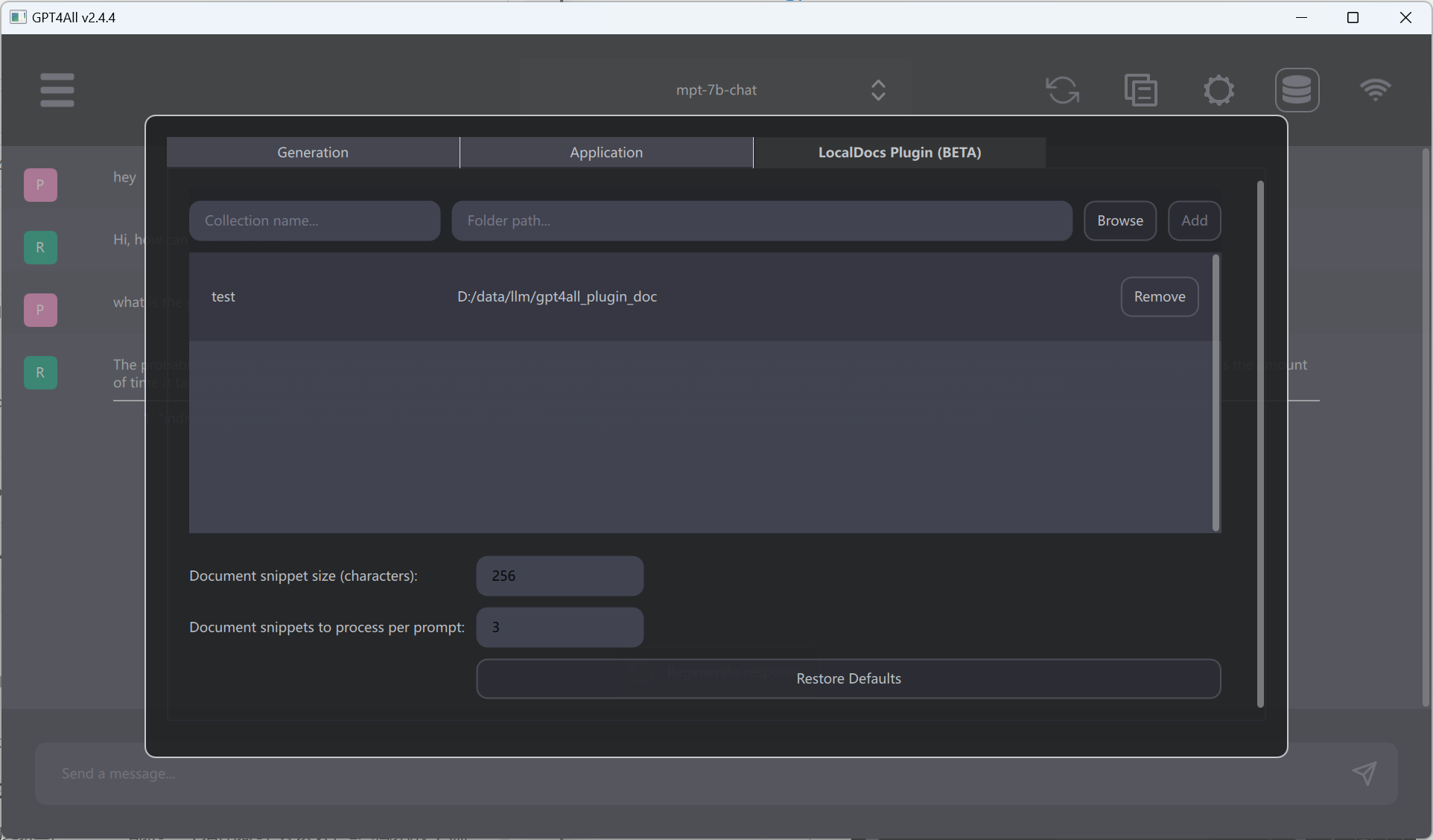
上面选择好目录之后,对话中右上角数据库那个图标,选择需要对话的文档即可。
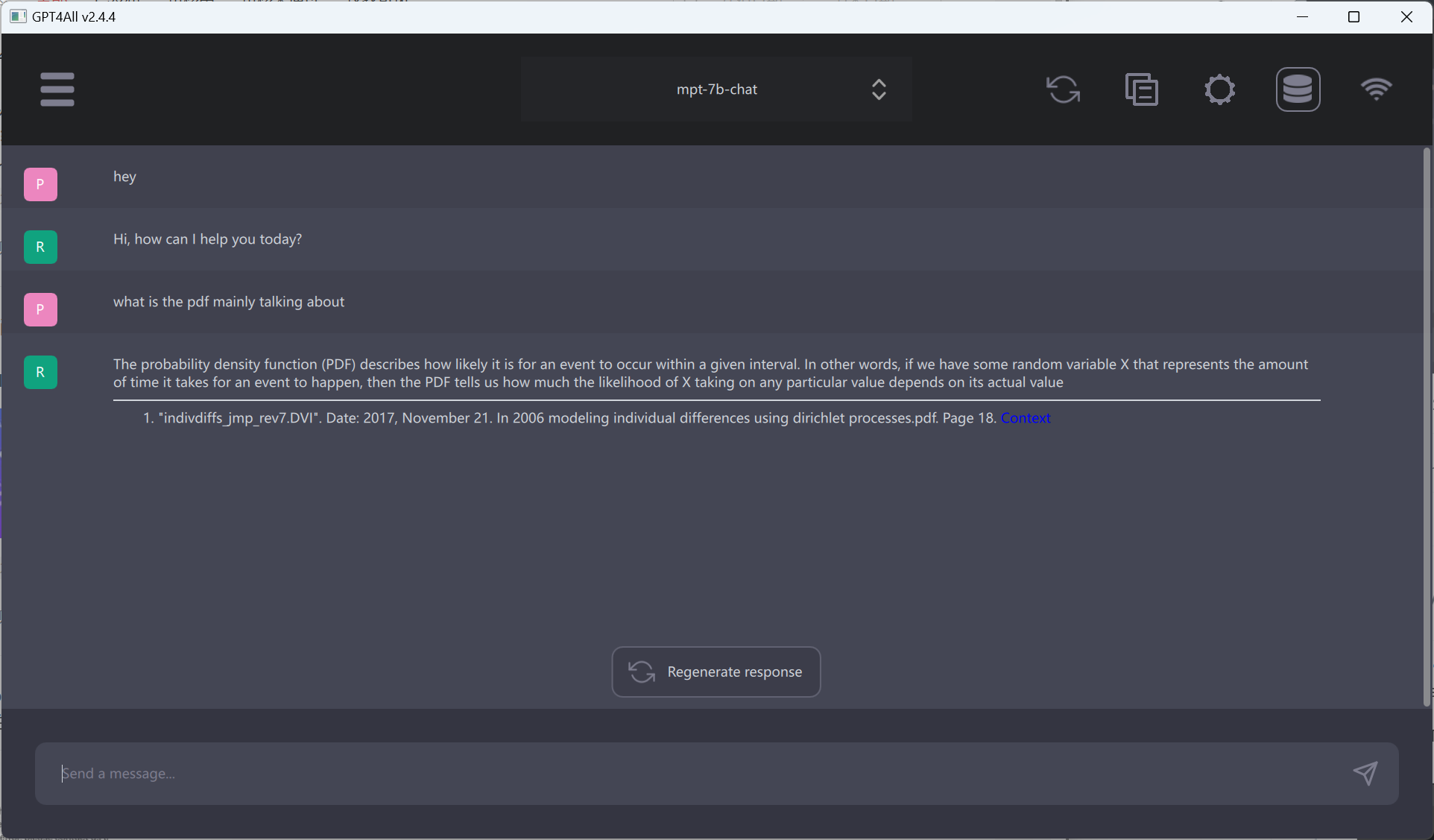
上图就是我测试的一个2006年论文的结果!可以用你选择的任意的大模型对文档进行解读。接下来你就可以针对这个文档继续提问了!
GPT4All的总结
尽管AI大模型的发展很快,ChatGPT的强大能力已经让很多人感到AI带来的变化。不过,目前商业化较高的AI大模型基本都是需要联网或者账号才能使用,这对于普通用户来说很不方便。尤其是对于国内的我们来说,更是难上加难。而开源的模型虽然丰富,但是如果不会计算机想要使用也不太容易。而GPT4All提供的解决方案基本上让所有普通用户都可以感受到开源大模型带来的方便。
因此,作为一个普通的对于目前的大模型使用感到困难,但是依然希望可以体验的童鞋来说,GPT4All是一个十分不错的方案。而对于隐私敏感的用户来说,这种方法也是一种不错的解决思路。而且随着开源模型的发展,相信它的能力也会越来越强的!
GPT4All的官方地址:https://gpt4all.io/index.html
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
