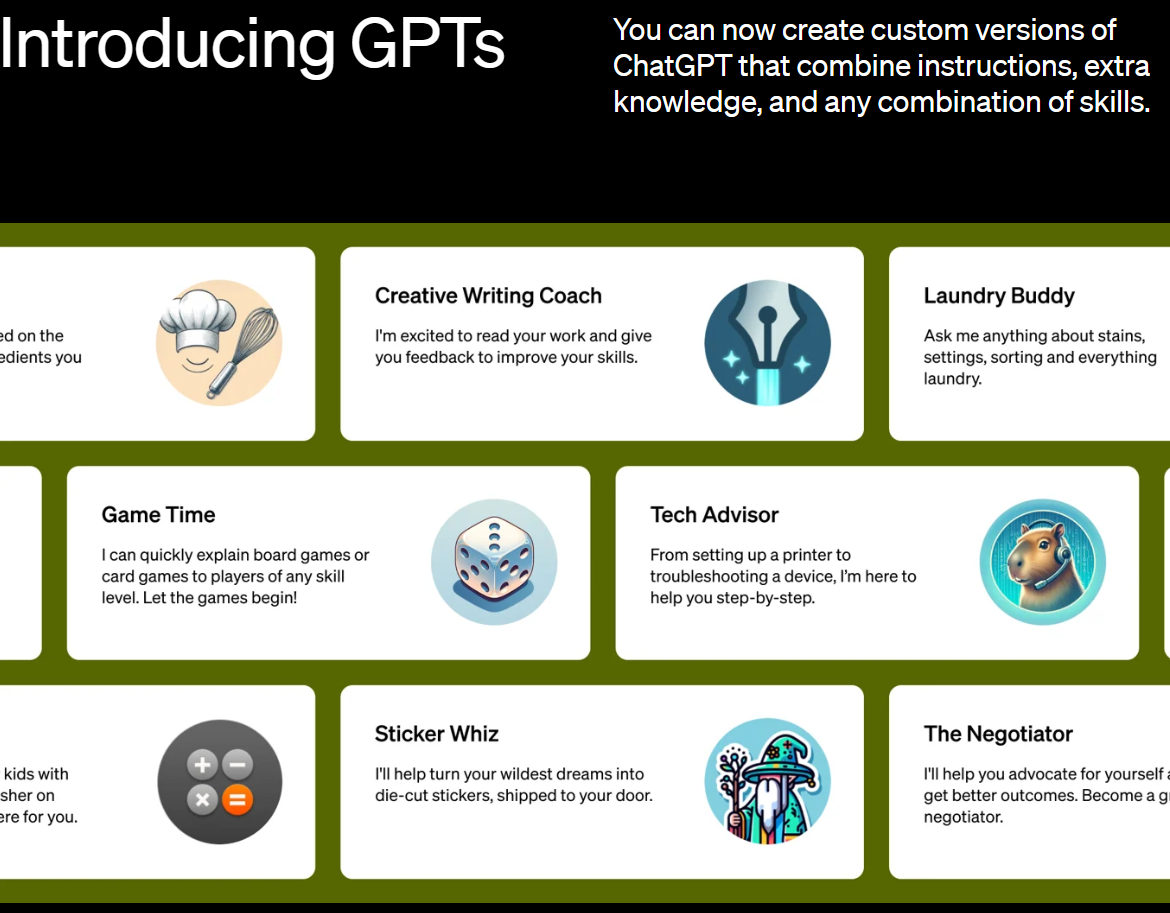
OpenAI发布2周后有哪些GPTs受欢迎?访问量如何?GPTs两周数据分析
GPTs是OpenAI在其开发者日发布的一项最新的个性化GPT功能。所有人可以基于现有的GPT-4,配合网络流量、文件访问等功能,上传自己的数据,对接自己的接口来构建个性化的GPT,并对外提供服务。那么,2周后的今天GPTs的发展怎么样?有哪些受欢迎的GPTs被大量使用?本文结合各方数据介绍一下当前GPTs的情况。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
GPTs是OpenAI在其开发者日发布的一项最新的个性化GPT功能。所有人可以基于现有的GPT-4,配合网络流量、文件访问等功能,上传自己的数据,对接自己的接口来构建个性化的GPT,并对外提供服务。那么,2周后的今天GPTs的发展怎么样?有哪些受欢迎的GPTs被大量使用?本文结合各方数据介绍一下当前GPTs的情况。
ChatGPT是当前大模型服务最前沿和风向标,每一次改动都会引起巨大的关注。此前,在ChatGPT的js脚本中就隐藏了即将发布的ChatGPT Team计划。而现在,新的ChatGPT UI代码和功能也被发现。新的GPT除了界面的巨大变化外,还有一个类似自定义AI Agent能力,可以直接接入自己的私有数据和API接口对外提供服务!十分震惊!
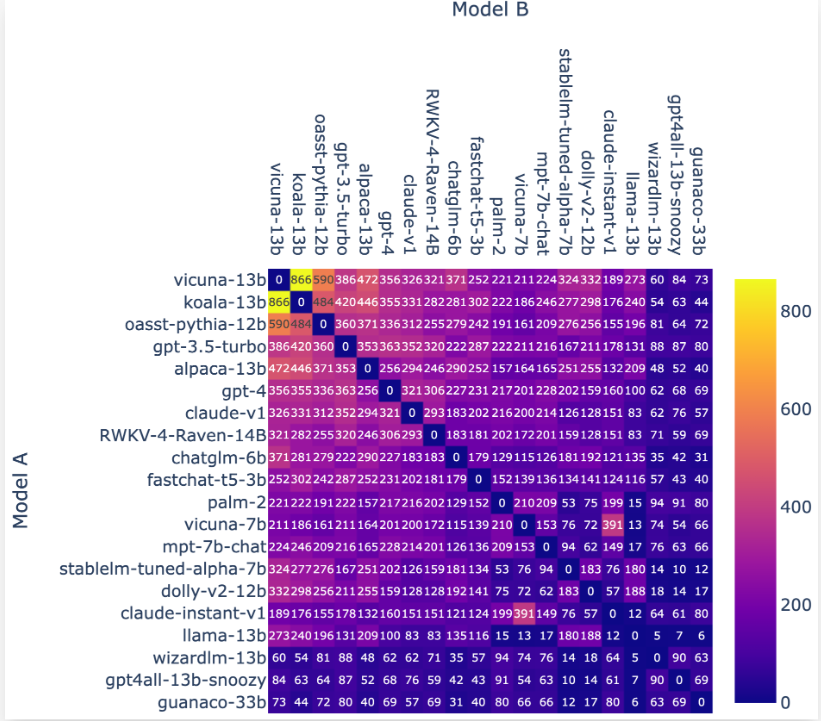
LM-SYS全称Large Model Systems Organization,是由加利福尼亚大学伯克利分校的学生和教师与加州大学圣地亚哥分校以及卡内基梅隆大学合作共同创立的开放式研究组织。该团队在2023年3月份成立,目前的工作是建立大模型的系统,是聊天机器人Vicuna的发布团队。今天开源 了包含3.3万包含真实人类偏好的对话数据集和3000条专家标注的对话数据集:Chatbot Arena Conversation Dataset和MT-bench人工注释对话数据集。
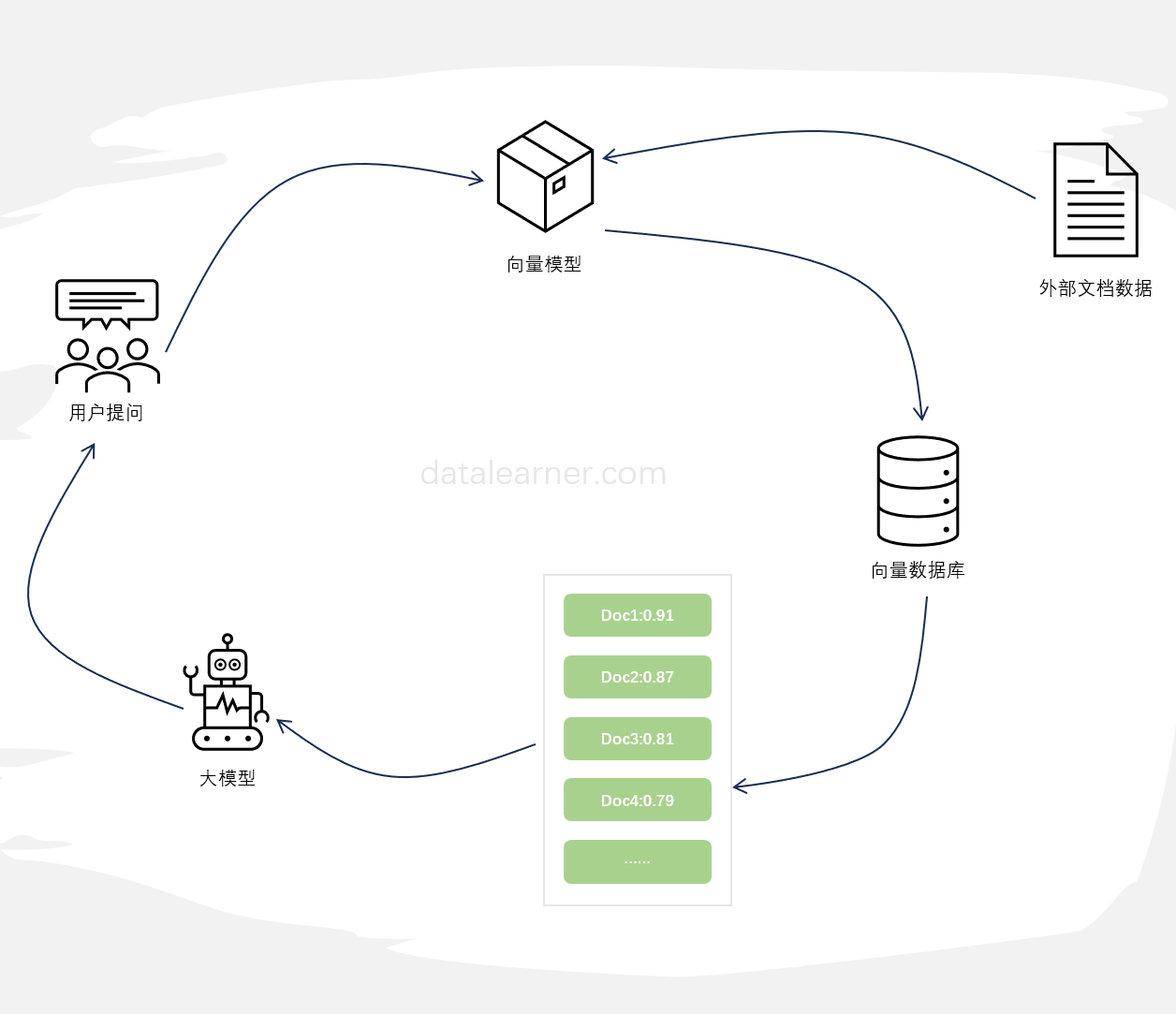
检索增强生成(Retrieval-augmented generation,RAG)是一种将外部知识检索与大型语言模型生成相结合的方法,通常用于问答系统。当前使用大模型基于外部知识检索结果进行问答是当前大模型与外部知识结合最典型的方式,也是检索增强生成最新的应用。然而,近期的研究表明,这种方式并不总是最佳选择,特别是当检索到的文档数量较多时,这种方式很容易出现回答不准确的情况。为此,LangChain最新推出了LongContextReorder,推出了一种新思路解决这个问题。
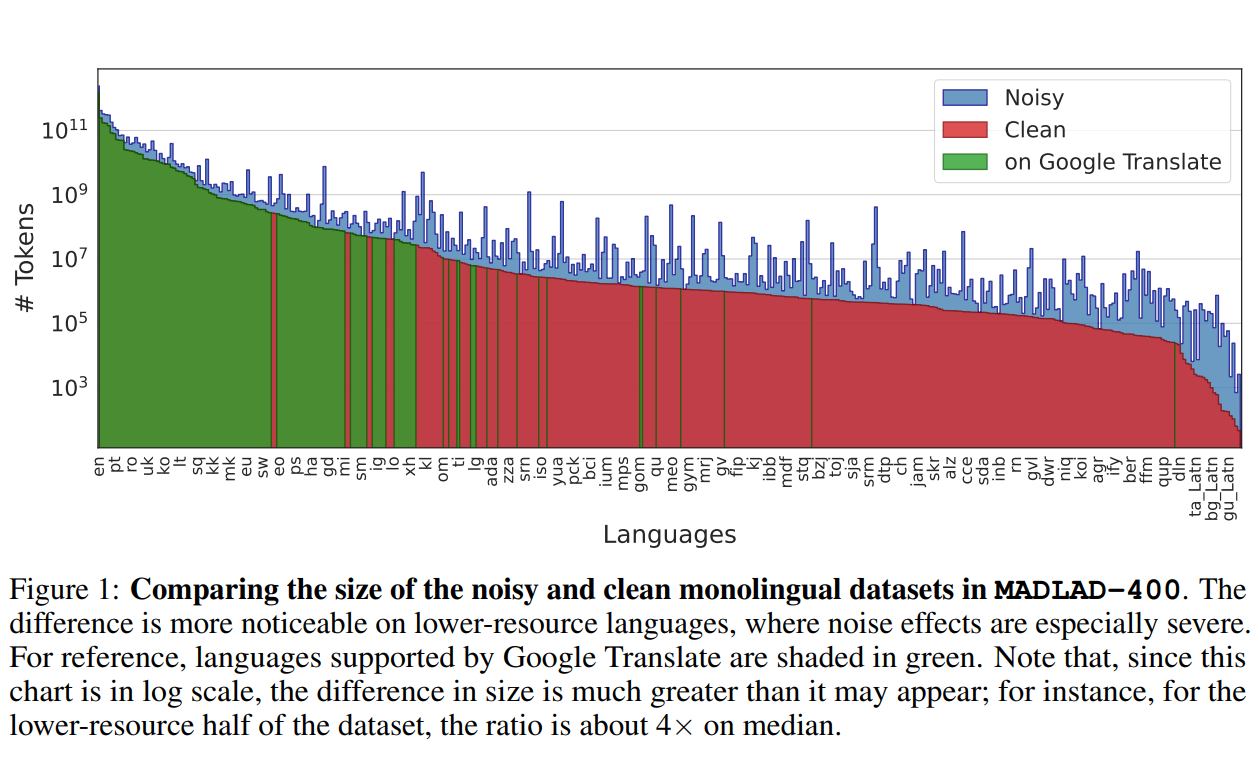
Google DeepMind与Google Research的研究人员推出了一个全新的多语言数据集——MADLAD-400!这个数据集汇集了来自全球互联网的419种语言的大量文本数据,其规模和语言覆盖范围在公开可用的多语言数据集中应该是最大的。研究人员从Common Crawl这个庞大的网页爬虫项目中提取了大量数据,并进行了人工审核,删除了许多噪音,使数据集的质量得到了显著提升。

MetaAI在2023年8月31日开源了一个全新的图像数据集,FACET(FAirness in Computer Vision EvaluaTion),FACET数据集包含32,000张图片和50,000人,这些图片由专家进行了详细的标注,包括人口统计属性(如感知性别表达和感知年龄组)和其他物理属性(如感知肤色和发型)。这样的设计使得研究人员可以更全面、更深入地评估模型在不同人群中的表现,从而更准确地识别和解决模型的不公平性问题。

随着近年来GPT-3、ChatGPT等大模型的兴起,高质量的数据集在模型训练中扮演着越来越重要的角色。但是当前领先的预训练模型使用的数据集细节往往不公开,开源数据的匮乏制约着研究社区的进一步发展。特别是大规模中文数据集十分缺乏,对中文大模型以及业界模型的中文支持都有很大的影响。此次,上海人工智能实验室发布的这个数据集包含了丰富的中文,对于大模型的中文能力提升十分有价值。

OpenAI在2023年8月份发布了GPT-3.5的微调接口,并表示会在2023年秋天开放16K的gpt-3.5-turbo-16k模型和GPT-4的微调(参考:[重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口](https://www.datalearner.com/blog/1051692752268726 "重磅!GPT-3.5可以微调了!OpenAI发布GPT-3.5 Turbo微调接口"))。然而,微调并不是一个简单的问题,如何对大模型微调以及如果微调出现问题

Allen Institute for AI简称AI2,是2014年成立的一个非营利性研究组织,其创办者是之前的微软联合创始人Paul G. Allen。目前该组织主导了几个非常大的项目,希望借助AI来推动科学、医学等领域的进步。此前也开源过大模型OLMo等。这次是该组织第一份发布AI数据集相关的项目,名称位Dolma,是一个包含了3万亿tokens的数据集,目前第一版本仅仅包含英文。
大语言模型训练的一个重要前提就是高质量超大规模的数据集。为了促进开源大模型生态的发展,Cerebras新发布了一个超大规模的文本数据集SlimPajama,SlimPajama可以作为大语言模型的训练数据集,具有很高的质量。除了SlimPajama数据集外,Cerebras此次还开源了处理原始数据的脚本,包括去重和预处理部分。官方认为,这是目前第一个开源处理万亿规模数据集的清理和MinHashLSH去重工具。
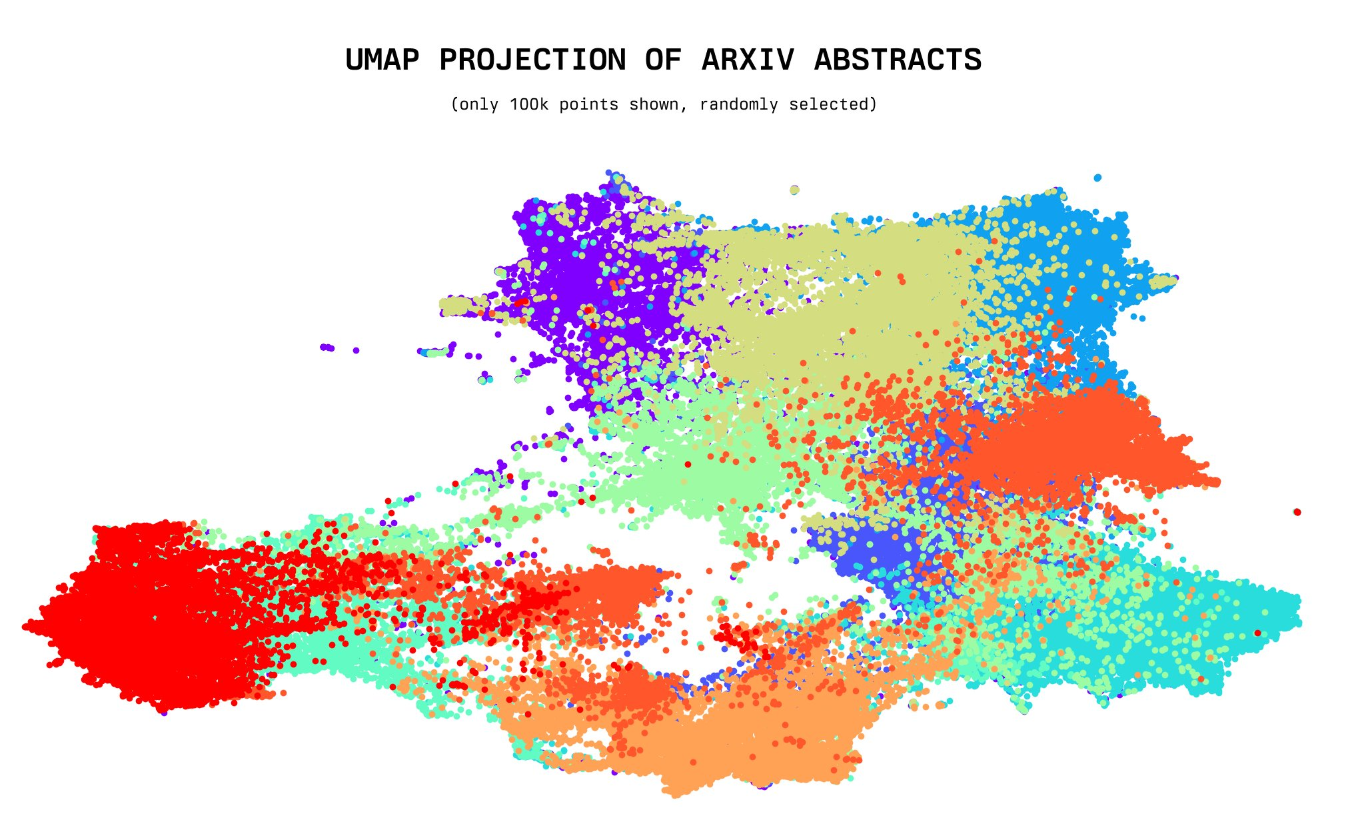
今天,一位年仅20岁的小哥willdepue 开源了230万arXiv论文的标题和摘要的embedding向量数据集,完全开源。该数据集包含截止2023年5月4日的所有arXiv上的论文标题和摘要的embedding结果,使用的是开源的Instructor XL抽取。未来将开放更多其它相关数据的embedding结果
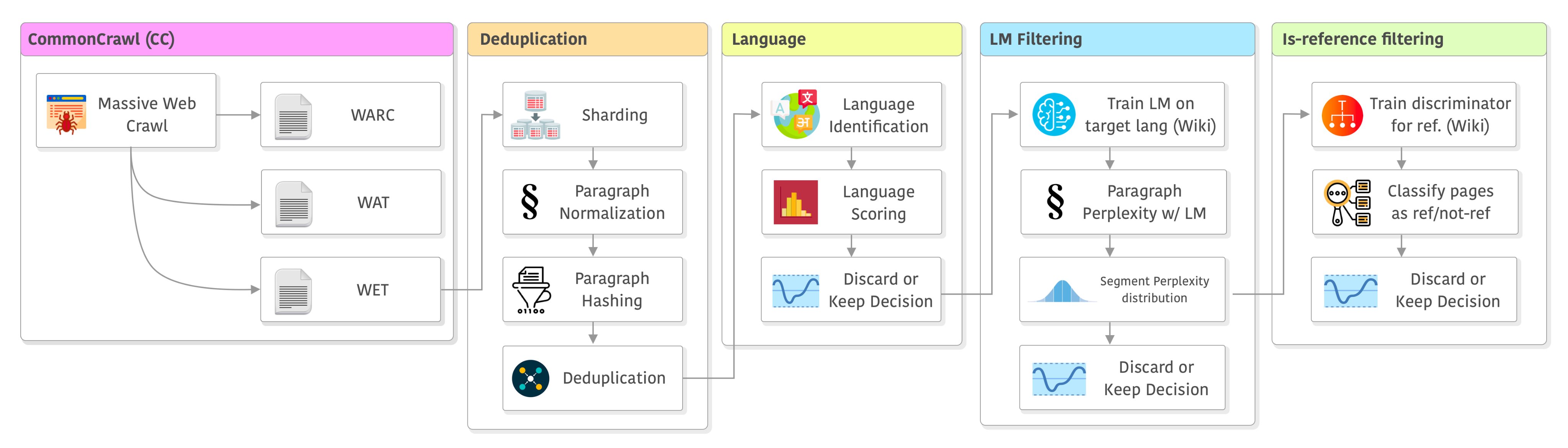
大语言模型的训练是一个十分复杂的技术,不仅涉及到模型的开发与部署,还涉及到数据的获取。与常规的算法模型不同的是,大语言模型通常需要大量的数据处理步骤。本文是根据英国一位自动工程师总结的大语言模型训练之前的数据处理步骤和决策过程。
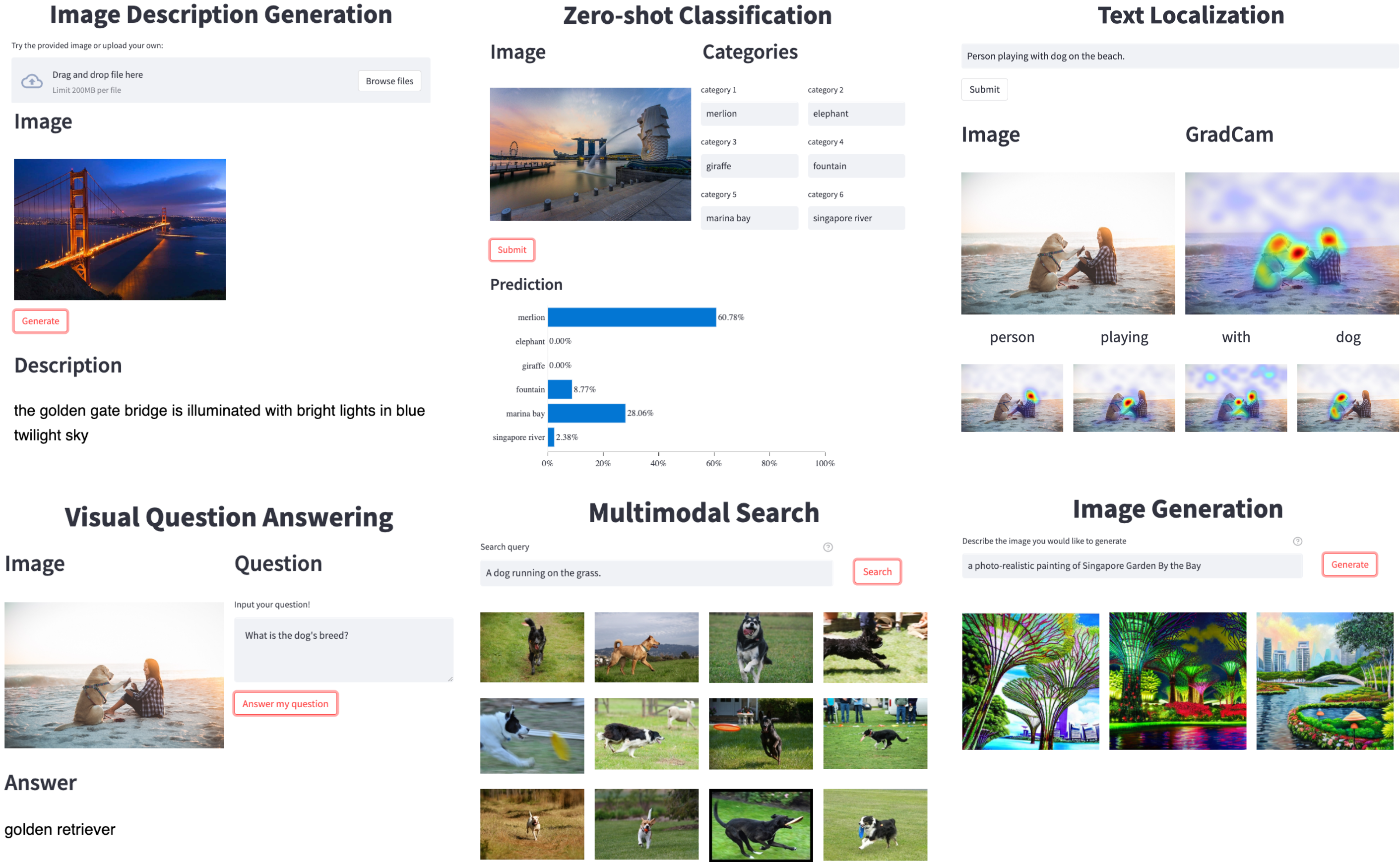
Salesforce的研究人员开发了LAVIS(LAnguage-VISION的缩写),这是一个开源的库,用于在丰富的常见任务和数据集系列上训练和评估最先进的语言-视觉模型,并用于在定制的语言-视觉数据上进行现成的推理。

今天Google发布了TensorStore,这是一个开源的C++和Python软件库,设计用于存储和操作大规模n维数据。TensorStore已经被用来解决科学计算中的关键工程挑战(例如,管理和处理神经科学中的大型数据集,如石油级的三维电子显微镜数据和神经元活动的 "4d "视频)。TensorStore还被用于创建大规模的机器学习模型,如PaLM,解决了分布式训练期间管理模型参数(检查点)的问题。

LAION全称Large-scale Artificial Intelligence Open Network,是一家非营利组织,成员来自世界各地,旨在向公众提供大规模机器学习模型、数据集和相关代码。他们声称自己是真正的Open AI,100%非盈利且100%Free。在九月份,他们公布了一个全新的图像-文本对(image-text pair)数据集。该数据集包含4亿条数据。

前几天,北京智源人工智能研究院引入了一个名为WuDaoMM的大规模多模态语料库,总共包含超过6.5亿对图像-文本。具体来说,约有6亿对数据是从图像和标题呈现弱相关的多个网页中收集的,另外5000万对强相关的图像-文本是从一些高质量的图片网站中收集的。
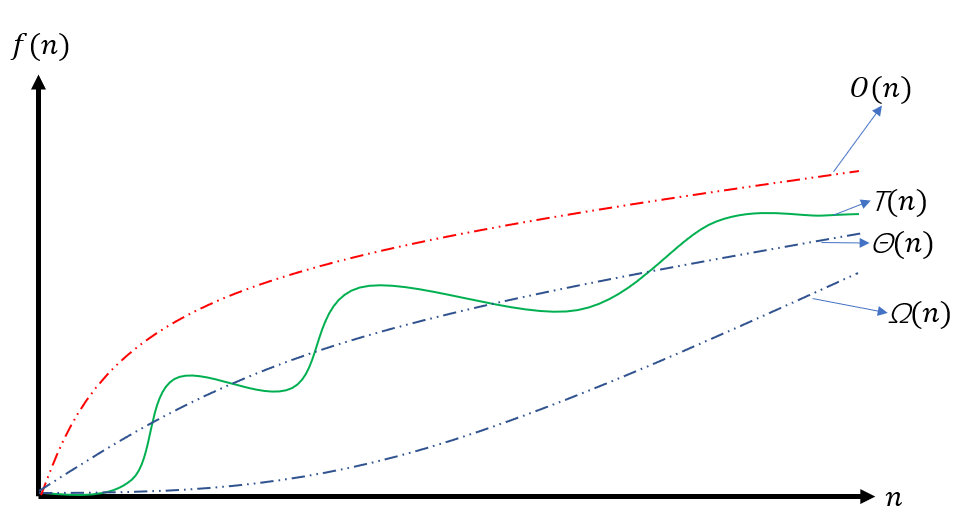
在程序设计和编程中,我们经常会看到关于时间复杂度的讨论。比如为什么A方法比B方法好?是因为A方法的时间复杂度低。那么,这里的时间复杂度如何去理解,又怎么计算呢?常见的O(n)的含义是什么?本文将简单的解释这个概念。
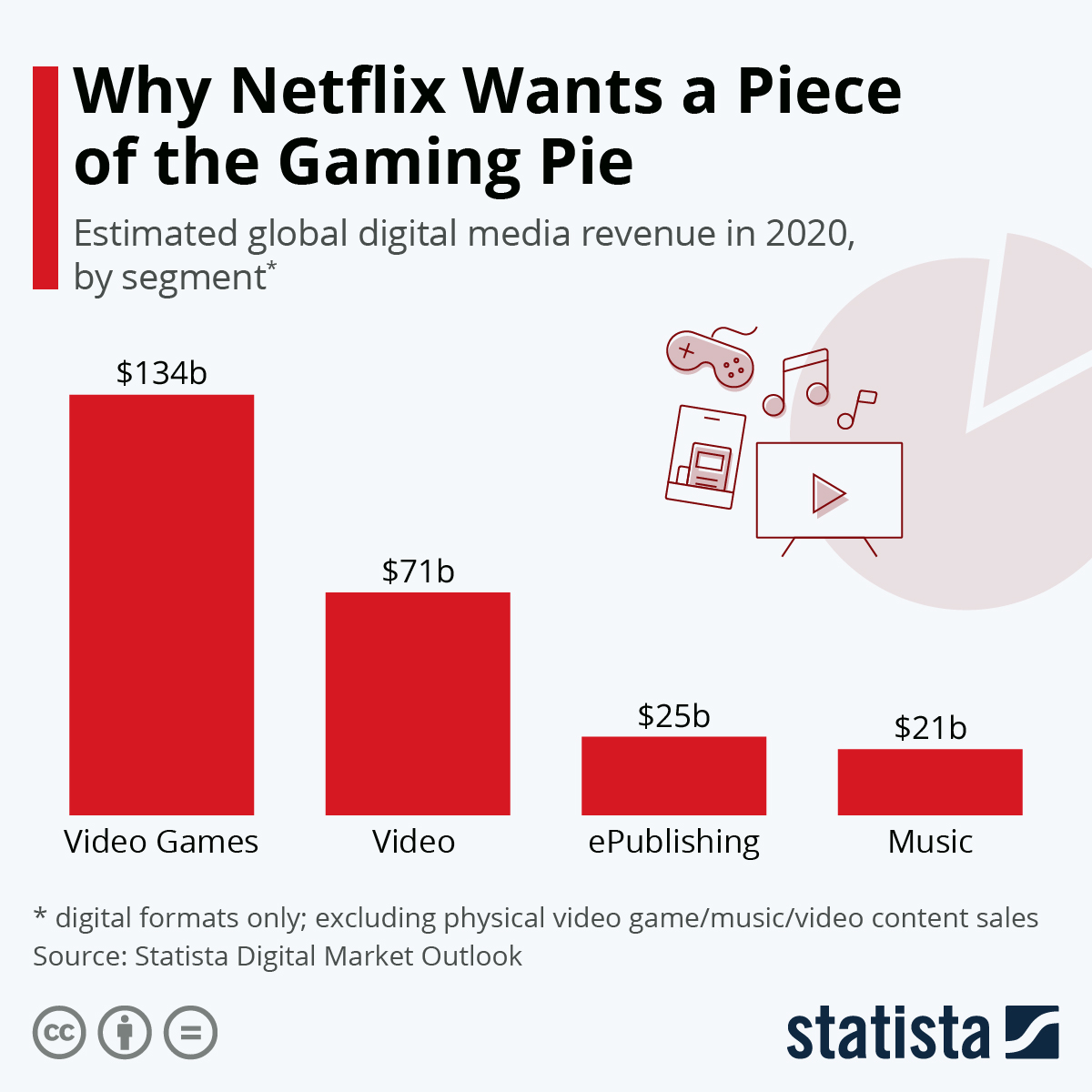
Netflix是一家网络视频服务公司,国内的爱奇艺、腾讯视频都与此类似。前几年大火的《纸牌屋》也就是这家公司提供的。当时最热吵的就是说Netflix凭借大数据选择的剧本形式与演员,让搞数据科学的人风光了好一阵。最近很火的《鱿鱼游戏》也是在Netflix全球独家播出。那么,网络视频搞得这么火热的Netflix为啥要开始搞游戏呢?这里有几个统计数据图可以解释Netflix这样做的原因。
新浪博客转入
当数据量达到一定程度,单机的处理能力会无法达到性能的要求,采用并行计算,并利用多台服务器进行分布式处理可能会提升数据处理的速度,达到性能要求。然而如果使用不当,并行处理可能并不会提升处理的速度。这篇博客介绍了Dask中关于并行处理的一些效率方面的建议,尽管是针对Dask的说明,但对于所有的并行处理来说都是适用的。
时间序列数据分析的基础包含大量的统计知识。这篇博客主要用通俗的语言描述时间序列数据中涉及到的一些基本统计知识。

数据结构中,自平衡二叉查找树搜索效率高,但是需要通过旋转和变色维护平衡。而列表虽然简单,但是对元素的查找需要比对列表中的每个元素,查找速度较慢。为了兼顾列表的简单易用,并提高查找效率,跳跃列表(Skip List)应运而生。

红黑树(Red-Black Tree)也是一种自平衡二叉查找树,与AVL不同的是它依靠节点颜色来维护树的平衡,在自平衡操作的时候,依赖变色和旋转两种操作来进行。