
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



美国有一家上市企业,叫做Roblox,号称是元宇宙龙头企业,被市场炒的火热。这家企业到底是什么样的业务,可以被认为是一家纯正的元宇宙企业。本文根据我收集的资料,为大家介绍一下。


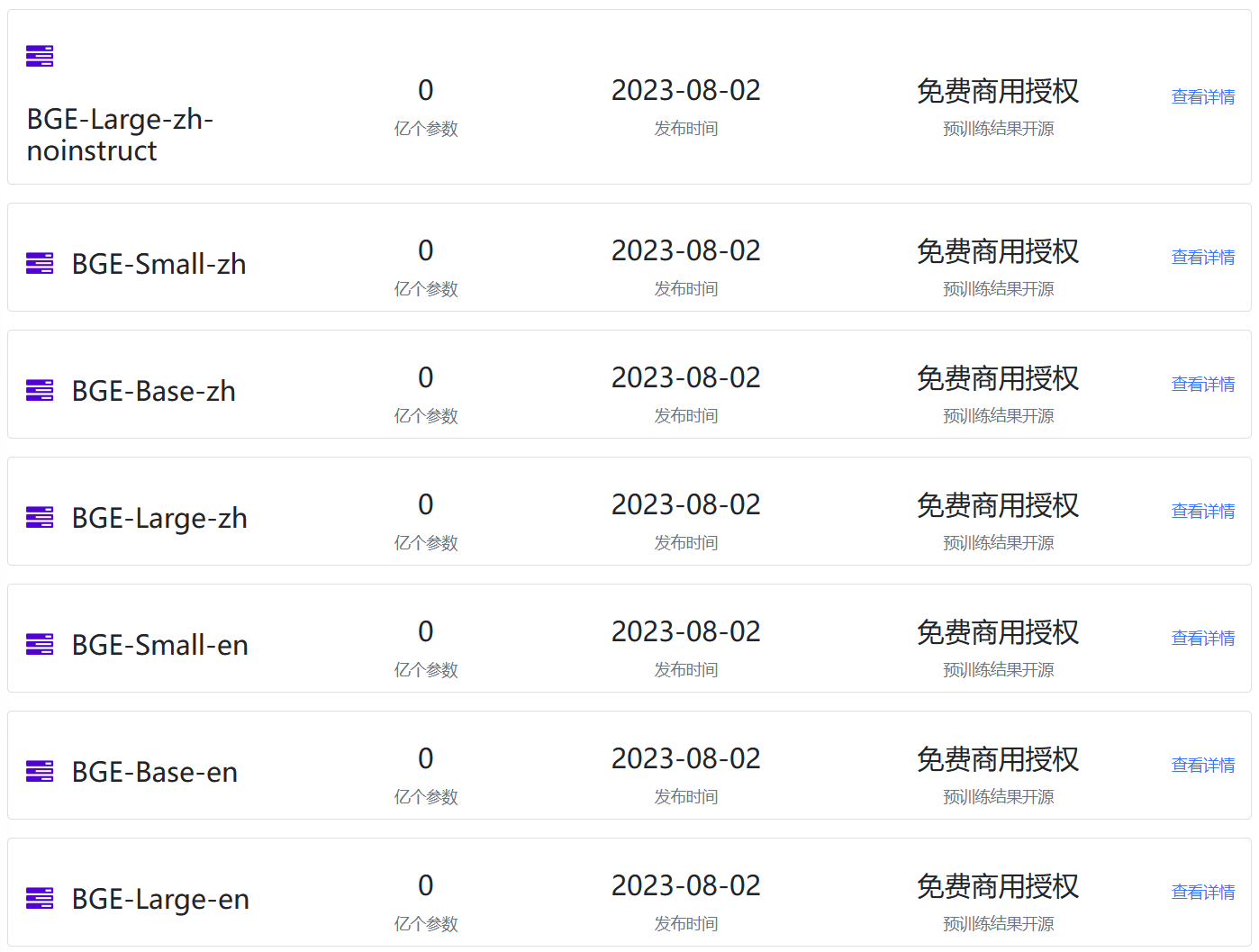
Embedding模型作为大语言模型(Large Language Model,LLM)的一个重要辅助,是很多LLM应用必不可少的部分。但是,现实中开源的Emebdding模型却很少。最近,北京智源人工智能研究院(BAAI)开源了BGE系列Embedding模型,不仅在MTEB排行榜中登顶冠军,还是免费商用授权的大模型,支持中文,应该可以满足相当多人的需要。
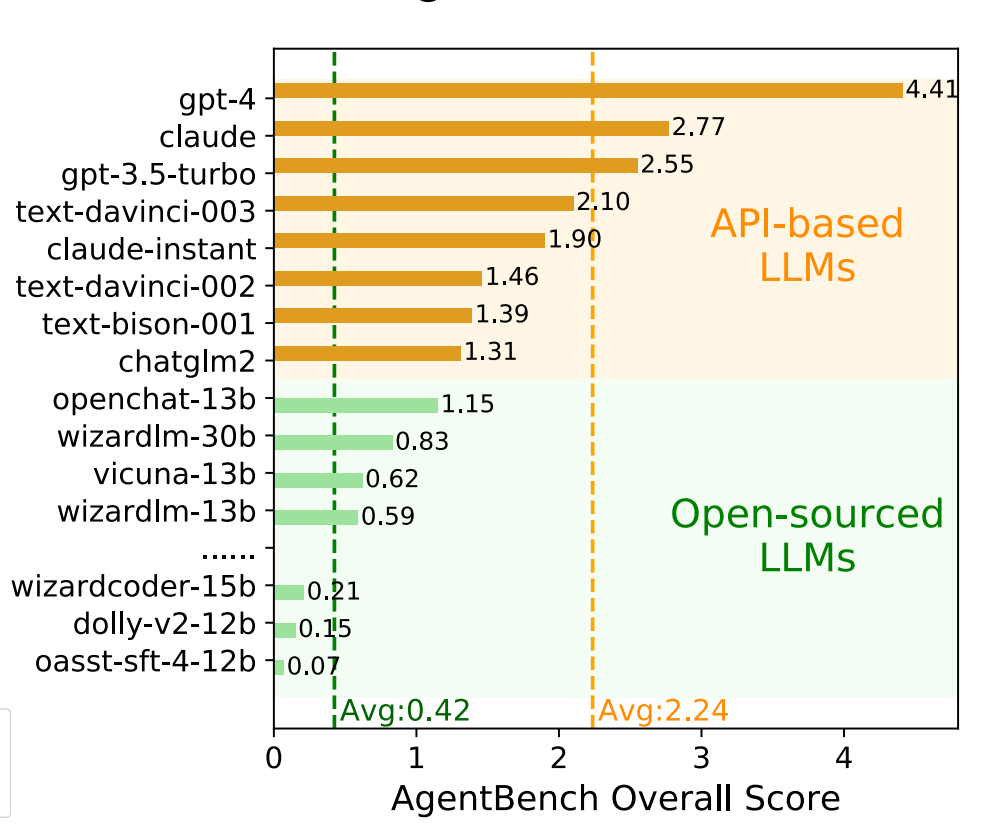
所谓AI Agent就是一个以LLM为核心控制器的一个代理系统。业界开源的项目如AutoGPT、GPT-Engineer和BabyAGI等,都是类似的例子。然而,并不是所有的AI Agent都有很好的表现,其核心还是取决于LLM的水平。尽管LLM已经在许多NLP任务上取得进步,但它们作为代理完成实际任务的能力缺乏系统的评估。清华大学KEG与数据挖掘小组(就是发布ChatGLM模型)发布了一个最新大模型AI Agent能力评测数据集,对当前大模型作为AI Agent的能力做了综合测评,结果十分有趣。
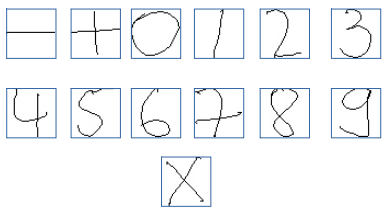
本文是发在Medium上的一篇博客:《Handwritten Equation Solver using Convolutional Neural Network》。本文是原文的翻译。这篇文章主要教大家如何使用keras训练手写字符的识别,并保存训练好的模型到本地,以及未来如何调用保存到模型来预测。
昨天,吴恩达宣布与OpenAI联合推出了一个新的面向开发者的ChatGPT的Prompt课程。课程主要教授大家如何使用Prompt做ChatGPT的应用开发、使用ChatGPT的新方法、建立自己的个性化的Chatbot,以及最重要的,基于OpenAI的API来练习Prompt工程技巧!


目前开源领域已经有一些模型宣称支持了8K甚至是更长的上下文。那么这些模型在长上下文的支持上表现到底如何?最近LM-SYS发布了LongChat-7B和LangChat-13B模型,最高支持16K的上下文输入。为了评估这两个模型在长上下文的表现,他们对很多模型在长上下文的表现做了评测,让我们看看这些模型的表现到底怎么样。
Vicuna是开源领域最强最著名的大语言模型,是UC伯克利大学的研究人员联合其它几家研究机构共同推出的一系列基于LLaMA微调的大语言模型。这个系列的模型因为极其良好的表现以及官方提供的匿名评测而广受欢迎。今天,LM-SYS发布Vicuna 1.5版本,包含4个模型,全部基于LLaMA2微调,最高支持16K上下文输入,最重要的是基于LLaMA2的可商用授权协议!免费商用授权!
今日推荐
最像OpenAI的企业Anthropic的重大产品更新:GPT-4最强竞争模型Claude2发布!免费!具有更强的代码能力与更长的上下文!
帮助你提升知识和技能的17个数据科学项目(都是可以免费获取的)
Falcon-40B:截止目前最强大的开源大语言模型,超越MetaAI的LLaMA-65B的开源大语言模型
一张图总结OpenAI看好的未来AI应用——OpenAI Startup Fund支持的创业企业简介
ChatGPT颠覆更新!即将发布的ChatGPT新版本带来巨变,新界面和可以自定义GPT-4功能:可以对接私有数据与私有接口的个性化ChatGPT即将到来!