
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




Dirichlet Process and Stick-Breaking(DP的Stick-breaking 构造)
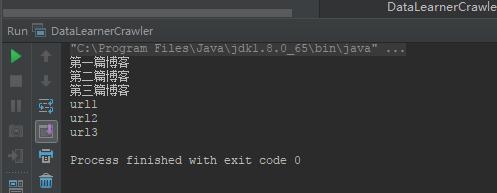
使用爬虫获取数据对科研来说及其重要,本系列博客将讲述如何使用Java编写爬虫工具获取网页数据。在这篇博客里,我们将简单介绍Jsoup解析HTML页面的操作。

当前大模型本质是一种大语言模型(Large Language Models, LLM),其核心能力是对语言的处理。良好的意图识别和文本生成能力让LLM超越了之前的模型,有了巨大的实用价值。但是,现实问题涉及了很多超越语言模型之外的能力,如基于最新数据的文本摘要、向用户提供实时数据分析和可视化结果、为代码提供debugging等。目前,让LLM解决这些问题的一个最有前景的方向就是建立大模型驱动的自动代理。也就是让LLM作为核心控制者来学会使用不同工具,进而完成最终任务。
本文介绍了文本领域的相关任务和技术,探讨了循环神经网络在文本领域的优势,并进一步研究了应用在文本领域的卷积网络方法,原文地址:https://medium.com/@TalPerry/convolutional-methods-for-text-d5260fd5675f
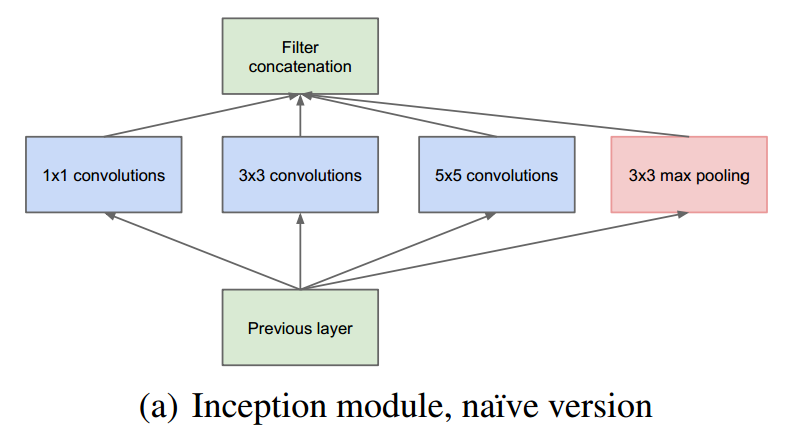
GoogLeNet是谷歌在2014年提出的一种CNN深度学习方法,它赢得了2014年ILSVRC的冠军,其错误率要低于当时的VGGNet。与之前的深度学习网络思路不同,之前的CNN网络的主要目标还是加深网络的深度,而GoogLeNet则提出了一种新的结构,称之为inception。GoogLeNet利用inception结构组成了一个22层的巨大的网络,但是其参数却比之前的如AlexNet网络低很多。是一种非常优秀的CNN结构。

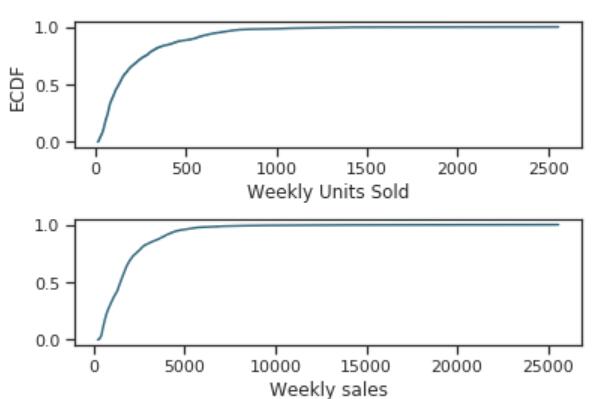
这是一篇来自Towards Data Science上面的一篇个人实践分享,主要是针对销量进行预测。一般来说,销量受到价格、季节等因素影响较大。这里就是考虑这些因素进行的一个实践。值得大家一试。这里我们翻译一下,并对其中的某些工作做一些简单的解释。
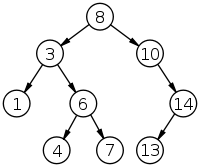
二叉查找树是一种特殊的二叉树结构,它改善了二叉树的查找效率,二叉查找树相比于其他数据结构的优势在于查找、插入的时间复杂度较低。与一般的二叉树的主要区别就是它对子节点的键值排序有一定要求。

去年5月份的时候,Python创始人Guido van Rossum在参加Language Summit时候说他希望Python3.11能在性能上获得巨大的提升,可以实现性能翻倍。目前看,似乎已经有了很大的希望!
前几天,北京智源人工智能研究院引入了一个名为WuDaoMM的大规模多模态语料库,总共包含超过6.5亿对图像-文本。具体来说,约有6亿对数据是从图像和标题呈现弱相关的多个网页中收集的,另外5000万对强相关的图像-文本是从一些高质量的图片网站中收集的。
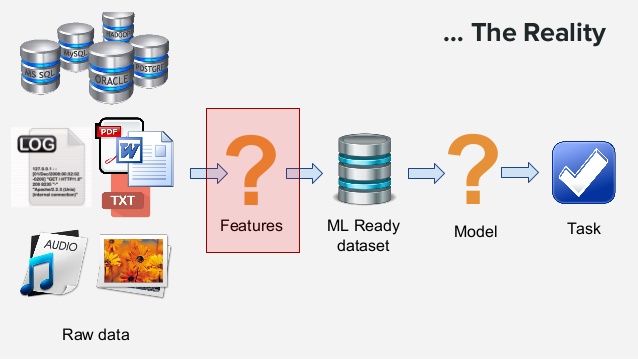
机器学习的特征工程是将原始的输入数据转换成特征,以便于更好的表示潜在的问题,并有助于提高预测模型准确性的过程。找出合适的特征是很困难且耗时的工作,它需要专家知识,而应用机器学习基本也可以理解成特征工程。

机器学习是这几年很热门的学习和工作的方向。但是机器学习相关算法的入门却并不容易。本文参考自MLTUT的博文,列举了2021年适合初学者的十个最佳机器学习网络课程供大家学习参考。
在进行编程操作的时候,我们常常会遇到很多与编程无关的项目管理工作,如下载依赖、编译源码、单元测试、项目部署等操作。一般的,小型项目我们可以手动实现这些操作,然而大型项目这些工作则相对复杂。构建工具是帮助我们实现一系列项目管理、测试和部署操作的工具。本文将对Java构建工具做简单介绍。
今日推荐
pandas的get_dummies方法在机器学习中的应用及其陷阱
开源王者!全球最强的开源大模型Llama3发布!15万亿数据集训练,最高4000亿参数,数学评测超过GPT-4,全球第二!
Google发布Gemini 2.5 Pro: Gemini系列第一个2.5版本的模型,最高支持200万上下文,全模态输入,推理大模型,LMArena排名第一
近期ChatGPT Plus用户发现GPT-4性能大幅下降!GPT-4性能下降的现象和原因总结
GPT-4来了!微软德国CTO透露GPT-4将是多模态模型,并于下周发布!
大模型领域最著名开源模型小羊驼Vicuna升级!Vicuna发布1.5版本,可以免费商用了!最高支持16K上下文!