
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~




百川智能是前搜狗创始人王小川创立的一个大模型创业公司,主要的目标是提供大模型底座来提供各种服务。虽然成立很晚(在2023年4月份成立),但是三个月后便发布开源了Baichuan系列开源模型,并上架了Baichun-53B的大模型聊天服务。这些模型受到了广泛的关注和很高的平均。而2个月后,百川智能再次开源第二代baichuan系列大模型,其能力提升明显。
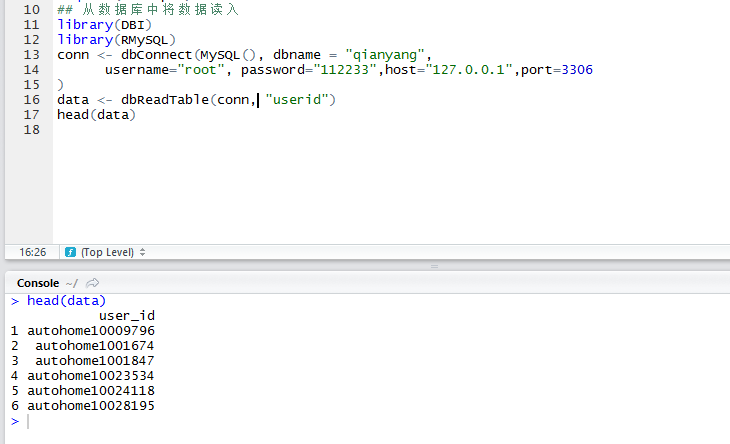
原来直接用root账户授权远程访问失败,最新的MySQL8不允许直接创建并授权用户远程访问权限,必须先让自己有GRANT权限,然后创建用户,再授权。
Microsoft Visual C++ 14.0 is required

今天,OpenAI官方宣布GPT接口新增一个能力:即支持以更加精确的JSON视图格式返回大模型的结果。比去年的单纯的让GPT输出JSON更加强大,它可以确保模型生成的输出能够完全匹配开发者提供的JSON模式。这种能力是在官方的API接口中增加了`return_format={"type":"json_schema","json_schema": {...}}`参数实现的。但是仅支持最新的模型版本,但这可能是未来的趋势!

在Java中,自增是一种非常常见的操作,在自增中,有两种写法,一种是前缀自增(++i),一种是后缀自增(i++)。这里主要简单介绍两种自增的差别。
主题模型聚类匹配
随着互联网的高速发展,人类进入了一个信息爆炸的时代,每个人的生活都充满了结构化和非结构化的数据。另外,随着以博客、社交网络、基于位置的服务LBS为代表的新型信息发布方式的不断涌现,以及云计算、物联网技术的兴起,数据正以前所未有的速度在不断地增长和积累,数据已经渗透到当今每一个行业和业务职能领域成为重要的产生因素,以数据为驱动的大数据时代已经不可避免地到来。本文主要围绕大数据特征、处理系统、以及大数据分析来阐述大数据环境下的数据分析在思想、流程、方法等方面的转变,以及围绕此主题而出现的相关关键技术与方法。
本文是Effective Java第三版笔记的第一个之创建静态工厂方法而不是使用构造器