
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~






数据科学项目为我们提供了很好的机会提升我们的技能和知识。这篇博客提供了17个数据科学的项目,都是可以免费获取的项目,大家可以通过这些诶项目学习数据科学相关知识。
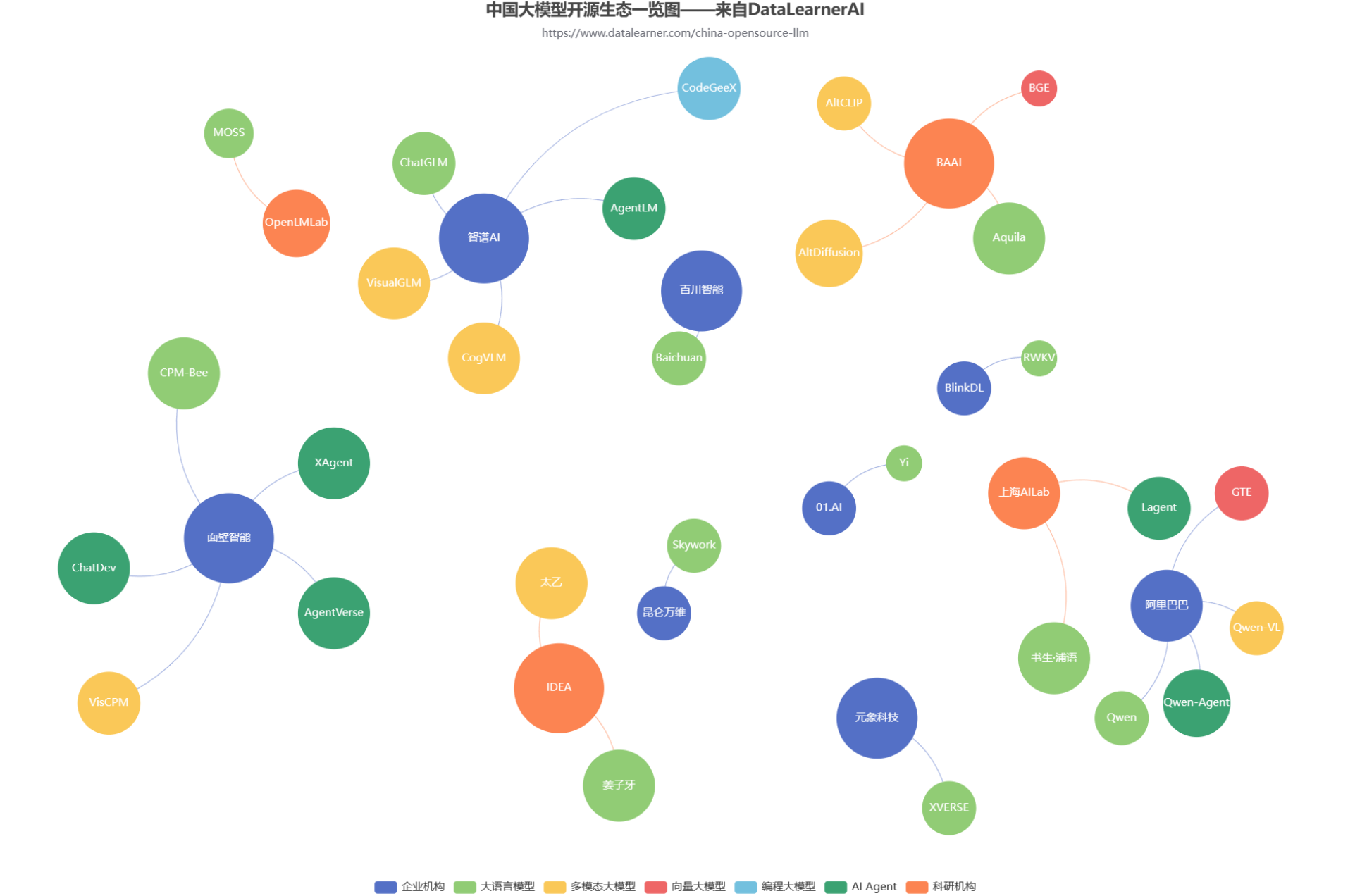
随着GPT的一路爆火,国内大模型的开源生态也开始火热。各大商业机构和科研组织都在不断发布自己的大模型产品和成果。但是,众多的大模型产品眼花缭乱。为了方便大家追踪国产开源大模型的发展情况,DataLearnerAI发布了中国国产大模型生态系统全景统计(地址:https://www.datalearner.com/china-opensource-llm ),本文也将根据这个统计结果简单分析当前国产开源大模型的生态发展情况。
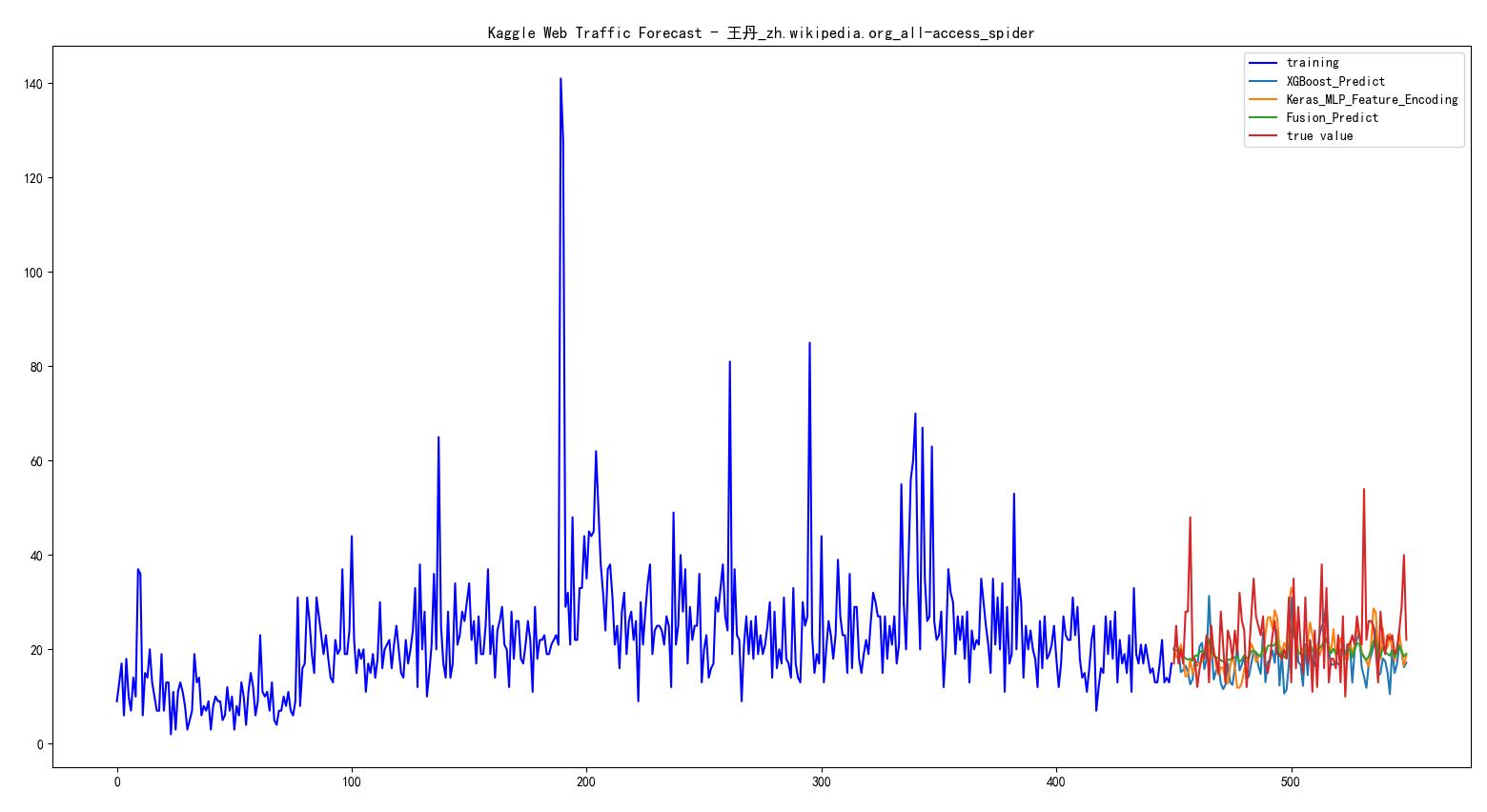
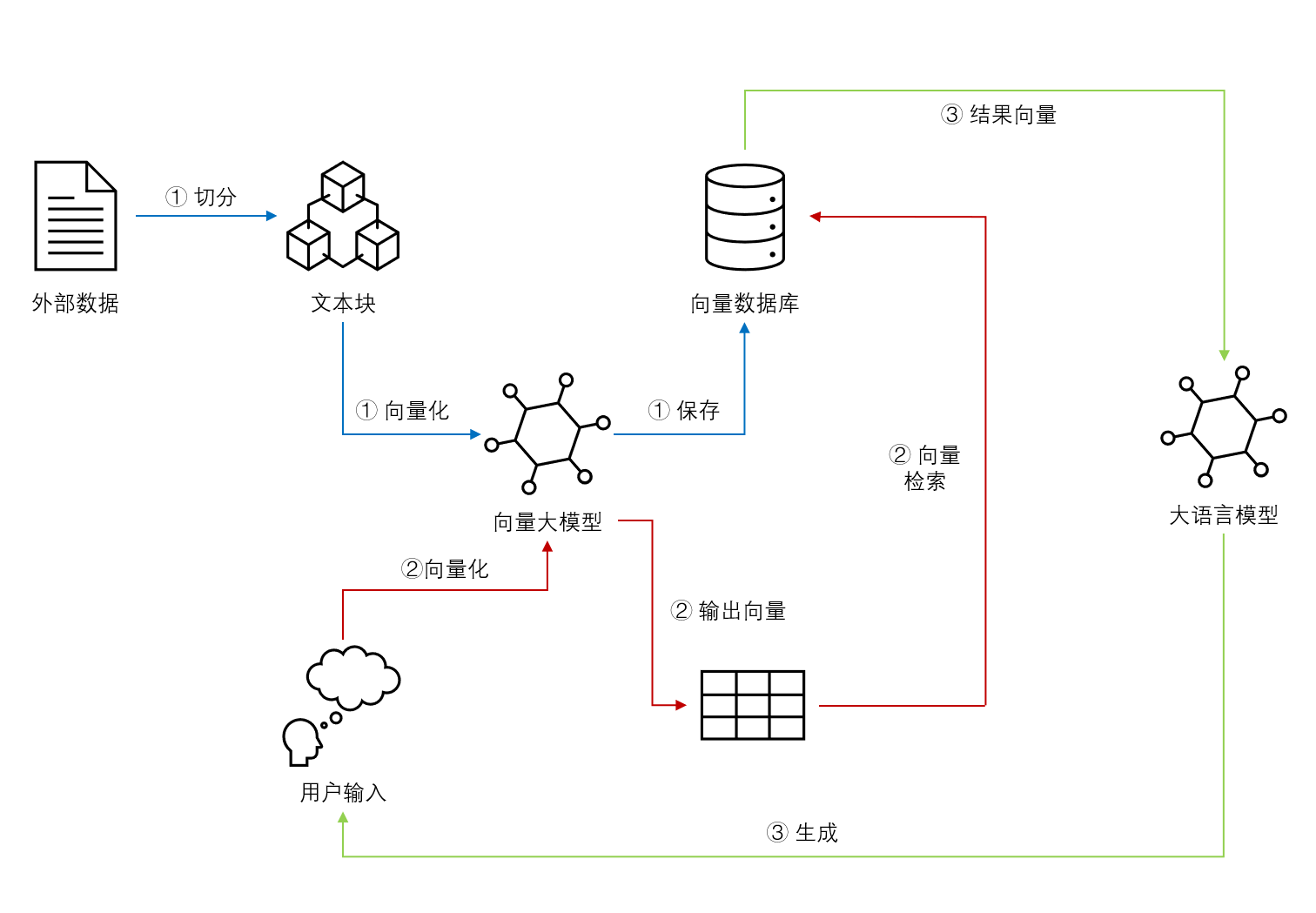
基于Embedding模型的大语言模型检索增强生成(Retrieval Augmented Generation,RAG)可以让大语言模型获取最新的或者私有的数据来回答用户的问题,具有很好的前景。但是,检索的覆盖范围、准确性和排序结果对大模型的生成结果有很大的影响。Llamaindex最近对比了主流的`embedding`模型和`reranker`在检索增强生成领域的效果,十分值得关注参考。

马尔可夫链(Markov Chain)是由马尔可夫性质推导出来的一种重要的概率模型。马尔科夫链是一种离散时间的随机过程,作为现实世界的统计模型,有很多应用。在热力学、统计力学、排队理论、金融领域等都有重要的应用价值。 作为一种离散时间的随机过程,与其对应的模型是马尔可夫过程(Markov Process),这是一种连续时间随机过程的模型。本节将主要介绍马尔科夫链。

Stable Diffusion是最近很火的Text-to-Image预训练模型(详细信息:https://www.datalearner.com/ai-resources/pretrained-models/stable-diffusion )。而现在,相关的视频教程已经出现。fast.ai的团队宣布了一门新的深度学习课程《From Deep Learning Foundations to Stable Diffusion》上线!
大语言模型训练的一个重要前提就是高质量超大规模的数据集。为了促进开源大模型生态的发展,Cerebras新发布了一个超大规模的文本数据集SlimPajama,SlimPajama可以作为大语言模型的训练数据集,具有很高的质量。除了SlimPajama数据集外,Cerebras此次还开源了处理原始数据的脚本,包括去重和预处理部分。官方认为,这是目前第一个开源处理万亿规模数据集的清理和MinHashLSH去重工具。

德国的一位博士生开源了一个使用LoRA(Low Rank Adaptation)技术和PEFT(Parameter Efficient Fine Tuning)方法对Whisper模型进行高效微调的项目。可以让大家在消费级显卡(显存8GB)上对OpenAI开源的WhisperV2模型进行微调!

今天,时隔一年后,OpenAI发布了第二代的DALL·E模型。相比较第一代的模型,DALL·E 2,以4倍的分辨率生成更真实和准确的图像。
今日推荐
MistralAI开源240亿参数的多模态大模型Mistral-Small-3.1-24B:评测结果与GPT-4o-mini与Gemma 3 27B有来有回,开源且免费商用,支持24种语言
20条关于DeepSeek的FAQ解释DeepSeek发布了什么样的模型?为什么大家如此关注这些发布的模型?他们真的绕过CUDA限制,打破了Nvidia的护城河了吗?
使用SpringMVC创建Web工程并使用SpringSecurity进行权限控制的详细配置方法
pandas的get_dummies方法在机器学习中的应用及其陷阱
准备迎接超级人工智能系统,OpenAI宣布RLHF即将终结!超级对齐技术将接任RLHF,保证超级人工智能系统遵循人类的意志
MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!
重磅!阿里巴巴开源自家首个MoE技术大模型:Qwen1.5-MoE-A2.7B,性能约等于70亿参数规模的大模型Mistral-7B