
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



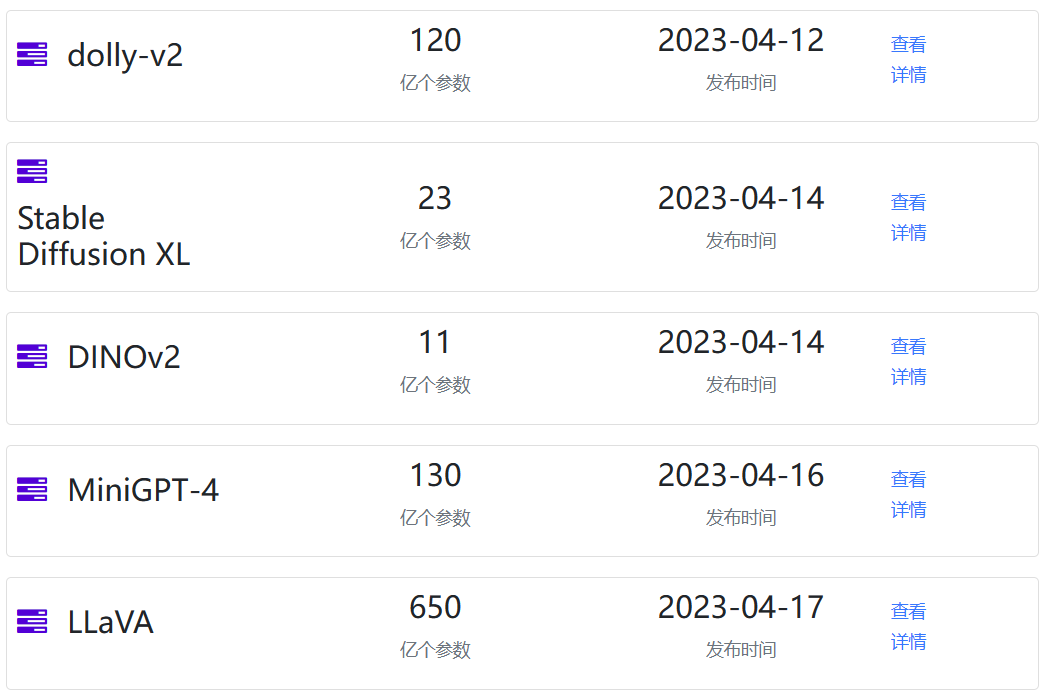
AI模型的发展速度令人惊讶,几乎每天都会有新的模型发布。而2023年4月中旬也有很多新的模型发布,我们挑出几个重点给大家介绍一下。
Awesome ChatGPT Prompts是由JavaScript开发者Fatih Kadir Akın创建的一个网站和应用,里面收集了160多个关于ChatGPT的Prompt模板,可以让ChatGPT变成Linux终端、JavaScript控制台、Excel页面等。这些Prompts收集自优秀的实践案例。

随着大型语言模型(LLM)如 GPT-3 和 BERT 在 AI 领域的崛起,如何在实际应用中高效地进行模型推断成为了一个关键问题。为此,英伟达推出了全新的大模型推理提速框架TensorRT-LM,可以将现有的大模型推理速度提升4倍!
苹果刚刚发布了一个全新的机器学习矿机MLX,这是一个类似NumPy数组的框架,目的是可以在苹果的芯片上更加高效地运行各种机器学习模型,当然最主要的目的是大模型。


最近一段时间,很多人普遍反映GPT-4变得懒散和愚笨,很多此前可以回答的问题在最近一段时间都无法回答,或者回答比较简单。为此,OpenAI官方也在前几天发布信息说的确收到了这样的信息,但是模型并没有在最近一个多月更新过,所以他们也在好奇是什么原因。而今天的一些测试表明,GPT-4模型会像人一样在不同的时间段有不同的效率。


大模型的微调是当前很多人都在做的事情。微调可以让大语言模型适应特定领域的任务,识别特定的指令等。但是大模型的微调需要的显存较高,而且比较难以估计。与推理不同,微调过程微调方法的选择以及输入序列的长度、批次大小都会影响微调显存的需求。本文根据LLaMA Factory的数据总结一下大模型微调的显存要求。

开源软件在现代互联网技术的发展中扮演者重要的作用。很多技术的进步和发展都是由开源软件推动的。而开源软件的发展离不开背后强大的开源组织的管理。本文列举最著名的五个开源组织,简述其背景,欢迎大家阅读。

《Python for Data Analysis: Data Wrangling with pandas, NumPy, and Jupyter》是由Wes McKinney撰写的Python数据分析专业工具书籍。很容易理解,这本书就是教大家如何使用Pandas、NumPy以及Jupyter分析数据的。
使用Dask进行分布式处理的时候一个最常见的场景是有很多个文件,每个文件由一个进程处理。这种操作经常会遇到一个程序挂起的问题,使得程序永远运行,无法结束。本文描述如何解决。

机器学习相关的竞赛为大家学习使用算法提供了一个非常好的平台和机会。既能检验大家学习的算法的实际应用情况,也可以帮助我们学习到很多有用的技巧。很多竞赛也都产生了优秀的算法思想与经验。所以积极参加比赛是一种非常重要的学习方式。本文总结目前正在举办的比赛,各位可以根据自己的情况参与。

Visual Studio Code简称VS Code,是由微软开发的跨平台免费开源的源代码编辑器。相比较Eclipse、PyCharm等软件,它很轻量,并不太像一个完整的IDE(Integrated Development Environment,集成开发环境)。但是,由于其轻量、快速、第三方扩展生态强大等原因,在2015年推出之后就迅速发展成为最受欢迎的开发环境。2019年的Stack Overflow的开发者调查中名列第一,使用占比月50.7%。
今日推荐
深度学习中为什么要使用Batch Normalization
DeepGraph Library(DGL)发布了0.81版本
OpenAI正式开放ChatGPT Team订阅计划,价格每个月贵25%,更多的GPT-4,附ChatGPT付费计划对比
全球首个200万上下文商业产品开始内测!月之暗面Kimi助手开启最长上下文模型内测邀请。
重磅!第二代ChatGLM发布!清华大学THUDM发布ChatGLM2-6B:更快更准,更低成本更长输入!
层次狄利克雷过程(Hierarchical Dirichlet Processes)
阿里开源截止目前为止参数规模最大的Qwen1.5-110B模型:MMLU评测接近Llama-3-70B,略超Mixtral-8×22B!