
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~





今天,吴恩达在推特上宣布和OpenAI、LangChain以及Lamini三家公司共同推出了3门短视频课程,分别是《使用ChatGPT API构建系统》、《基于LangChain的大语言模型应用与开发》和《Diffusion模型是如何工作的》。三门课程都是1个小时的短视频课程,而且配有详细的Jupyter Notebook使用方法。

Batch Normalization(BN)是一种深度学习的layer(层)。它可以帮助神经网络模型加速训练,并同时使得模型变得更加稳定。尽管BN的效果很好,但是它的原理却依然没有十分清晰。本文总结一些相关的讨论,来帮助我们理解BN背后的原理。

OpenAI发布的产品中,有2个产品可以用来将GPT当作一个类似AI Agent工具使用,同时支持接入自定义的接口和数据。那就是GPTs和Assistant API,前者可以在界面直接操作,后者则是一个API,两者功能接近,为了让大家更加清晰理解二者区别,OpenAI官方最近发布了二者的解释。

Stable Diffusion XL是StabilityAI最新的开源模型。是目前业界流行的免费开源图像生成大模型。2023年4月份StabilityAI就宣布了SD XL的存在并在2023年7月26日开源。SD XL相比较此前的模型速度更快、提示词更短、生成的图像更加真实。但是,大多数人可能并没有实际运行过,感受过这个模型的魅力。在这篇博客中,我们给大家展示如何利用Google Colab的免费GPU资源,部署一个SD XL模型,并通过prompt生成一些图片。
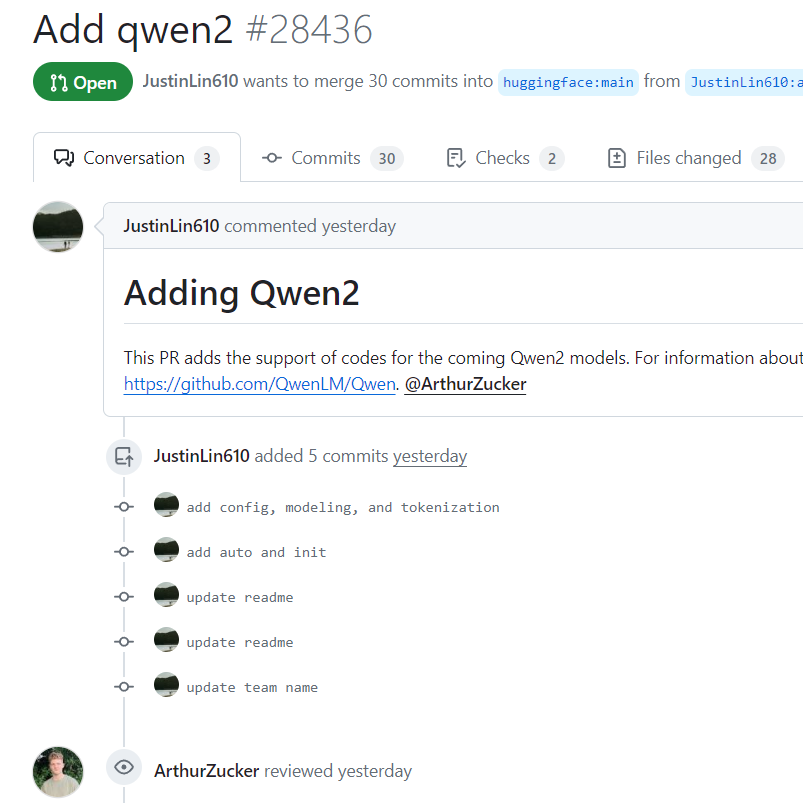
通义千问是阿里巴巴开源的一系列大语言模型。Qwen系列大模型最高参数量720亿,最低18亿,覆盖了非常多的范围,其各项评测效果也非常好。而昨天,Qwen团队的开发人员向HuggingFace的transformers库上提交了一段代码,包含了Qwen2的相关信息,这意味着Qwen2模型即将到来。

OpenAI是全球最著名的人工智能研究机构,发布了许多著名的人工智能技术和成果,如大语言模型GPT系列、文本生成图片预训练模型DALL·E系列、语音识别模型Whisper系列等。由于这些模型在各自领域都有相当惊艳的表现,引起了全世界广泛的关注。

今天,HuggingFace官方宣布了Transformers最大胆的功能:Transformers Agents。这是继AutoGPT开创性发布之后,AI Agent被业界接受的另一个重要的里程碑。

OpenAI在3月15日发布了一个最新的GPT-3和Codex的版本,这个版本最大的能力就是可以在已有的文本上插入或者编辑新的内容。而不是续写已有的文本。这个能力最大的应用就是重写已有文本,或者用来重构代码。
几个小时前SemiAnalysis的DYLAN PATEL和DYLAN PATEL发布了一个关于GPT-4的技术信息,包括GPT-4的架构、参数数量、训练成本、训练数据集等。本篇涉及的GPT-4数据是由他们收集,并未公开数据源。但是内容还是有一定参考性,大家自行判断。
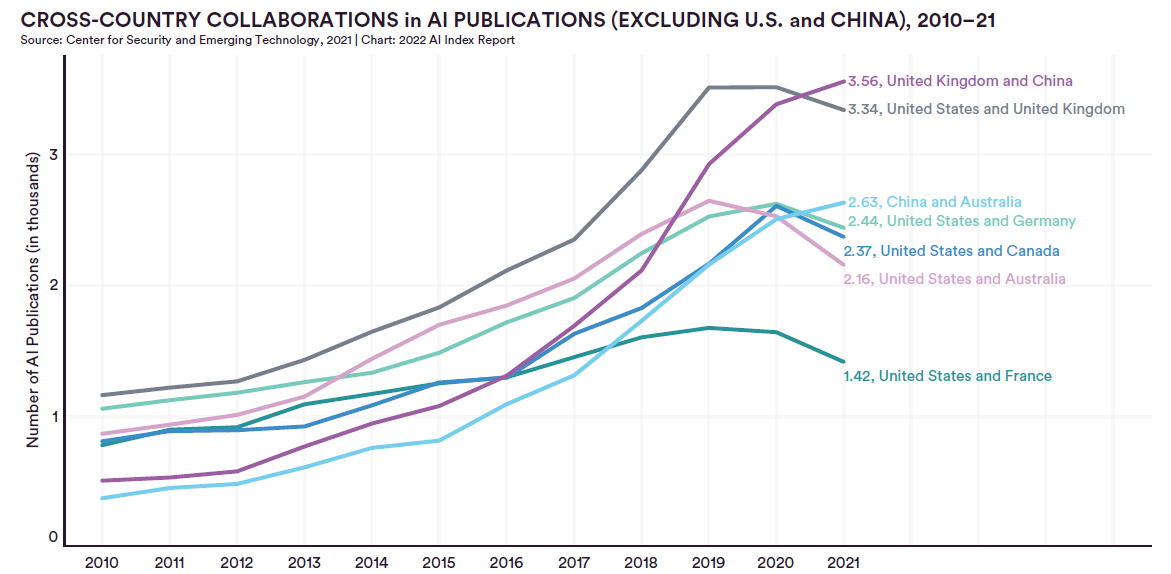
人工智能指数是斯坦福大学以人为本人工智能研究所(Stanford Institute for Human-Centered Artificial Intelligence (HAI))联合学术界、工业界的专家一起发布的人工智能相关的发展报告。2022年度AI指数报告在近几日发布。

当前的大模型的参数规模较大,数以千亿的参数导致了它们的预训练结果文件都在几十GB甚至是几百GB,这不仅导致其使用成本很高,在不同平台进行交换也非常困难。因此,大模型预训练结果文件的保存格式对于模型的使用和生态的发展来说极其重要。昨天HuggingFace官方宣布将推动GGUF格式的大模型文件在HuggingFace上的使用。

The AI Index报告是斯坦福大学发布的人工智能发展研究报告。最早的报告开始于2017年,每年一个版本,主要是总结过去一年人工智能的发展情况。2023年斯坦福The AI Index已经在近日发布。相比较之前的报告,今年的报告新增对Foundation模型的分析。让我们看看斯坦福大学如何总结2022年人工智能领域的发展情况。

微软在去年4月份的时候推出了一个构建虚拟助手的指南:《构建人工智能应用的开发者指南·第二版》。这份报告帮助我们借助微软的工具构建一个虚拟助手,本文将简要描述一下这份报告,文末有相关资源下载。