
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



Gemini是谷歌发布的一系列大语言模型。最早是2023年12月发布1.0版本,在2023年2月中旬,劈柴哥亲自宣布Gemini Pro升级到1.5版本。Gemini 1.5 Pro是一个全新的MoE模型(Mixture of Experts,混合专家),在各项评测结果中都接近Gemini Ultra 1.0的水平。而在今天,Gemini Pro 1.5再次迎来重大更新,包括音频理解、无限制文件阅读以及更好地指令遵从性等。本文将介绍这次更新,并做一些简单的实际测试。
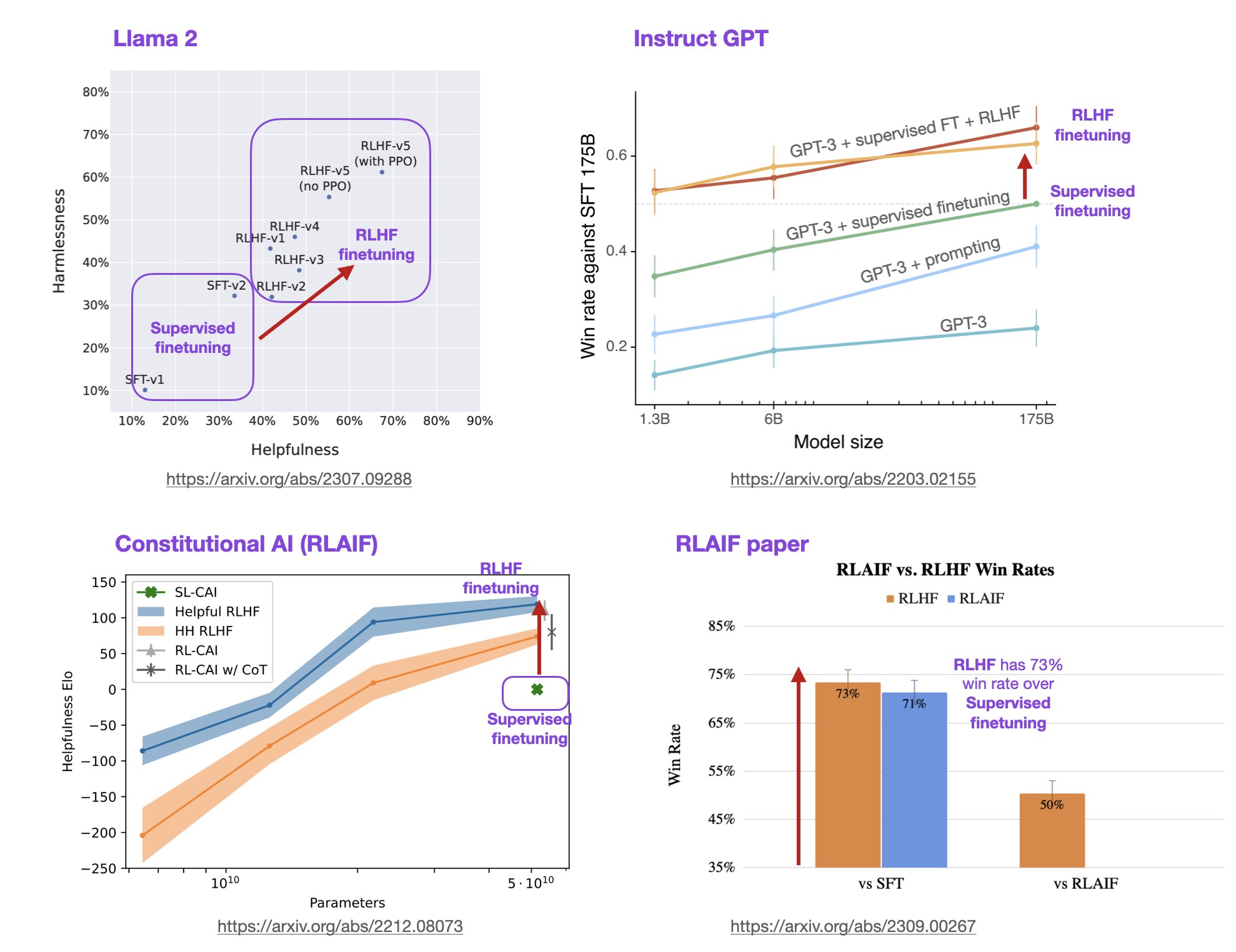
基于人类反馈的强化学习方法(Reinforcement Learning with Human Feedback,RLHF)是一种强化学习(Reinforcement Learning,RL)的变种,它利用人类的专业知识和反馈来指导机器学习模型的训练和决策过程。这种方法旨在克服传统RL方法中的一些挑战,例如样本效率低、训练困难和需要大量的试错。在大语言模型(LLM)中,RLHF带来的模型效果提升不仅仅是模型偏好与人类偏好的对齐,模型的理解能力和效果也会更好。

大模型的进展非常快,但是如何在移动端部署和使用依然是一个非常大的挑战。今天,CerebrasAI联合Opentensor一起开源了一个30亿参数规模的模型BTLM-3B-8K,官方宣称其性能接近70亿参数规模的大模型,但是运行的资源却很低,最低量化版本只需要不到4GB显存即可。
电影《流浪地球2》里面一个非常重要的情节就是数字生命计划。将人类的意识上传到计算机之后,可以通过AI技术让人类以数字化的形式在计算机中存活。而今天HeyGen官方宣布的即将推出的真人视频生成技术,可以根据真人的照片生成非常逼真的数字人视频,其动作、表情、声音等全部由AI技术生成,而几乎无法分辨是真人拍摄的视频还是AI生成的视频。


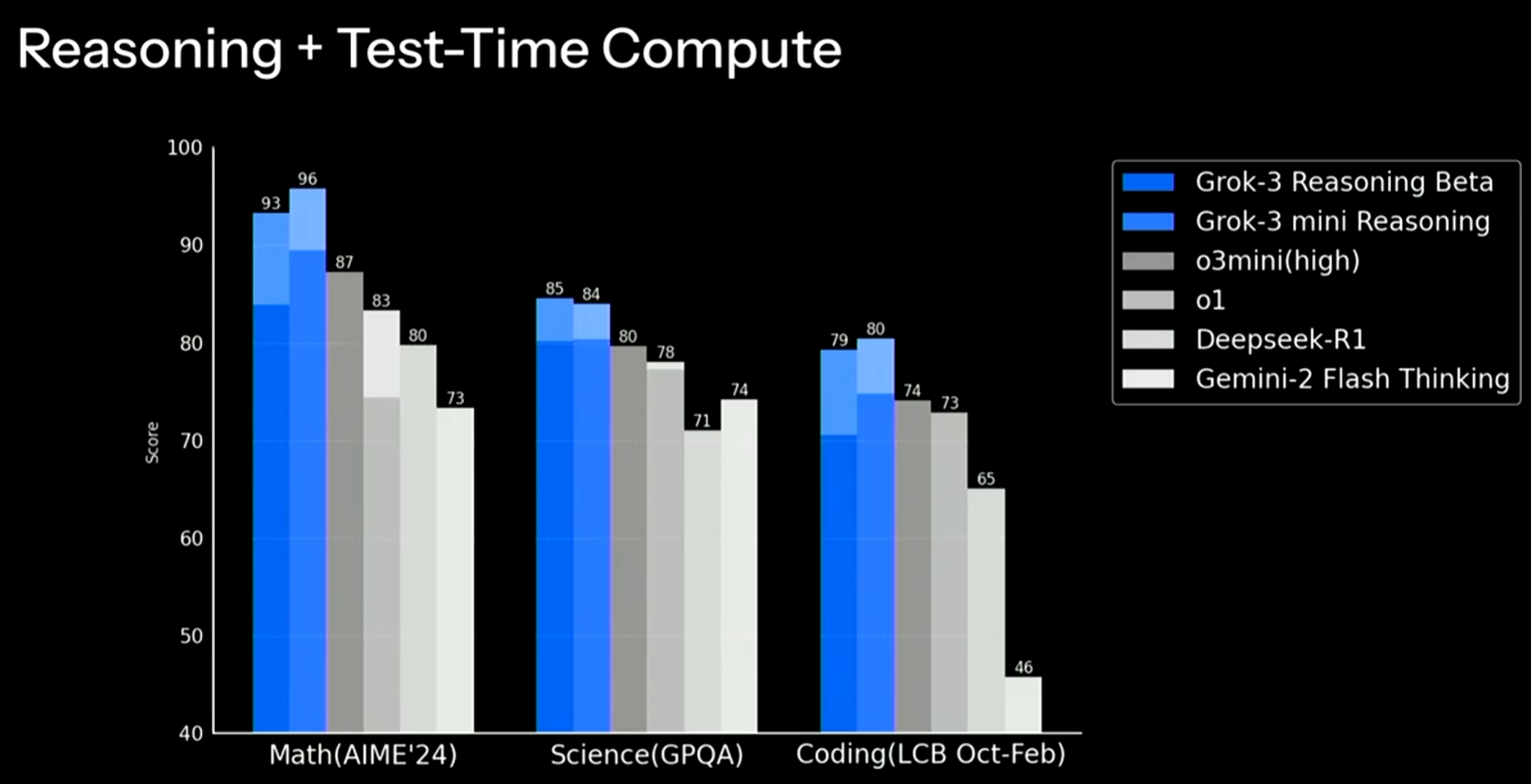
今天马斯克旗下的xAI公司发布了最新一代大语言模型Grok3,基于20万张GPU集群训练,各方面的提升都非常明显。在主流评测上都超过了现有的大模型。
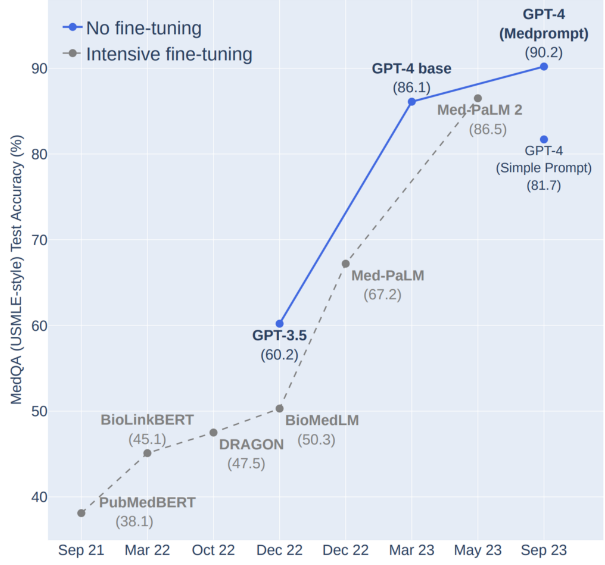
在GPT-4这种超大基座模型发布之后,一个非常活跃的方向是专有模型的发展。即一个普遍的观点认为,基座大模型虽然有很好的通用基础知识,但是对于专有的领域如医学、金融领域等,缺少专门的语料训练,因此可能表现并不那么好。如果我们使用专有数据训练一个领域大模型可能是一种非常好的思路,也是一种非常理想的商业策略。但是,微软最新的一个研究表明,通用基座大模型如果使用恰当的prompt,也许并不比专有模型差!同时,他们还提出了一个非常新颖的动态prompt生成策略,结合了领域数据,非常值得大家参考。
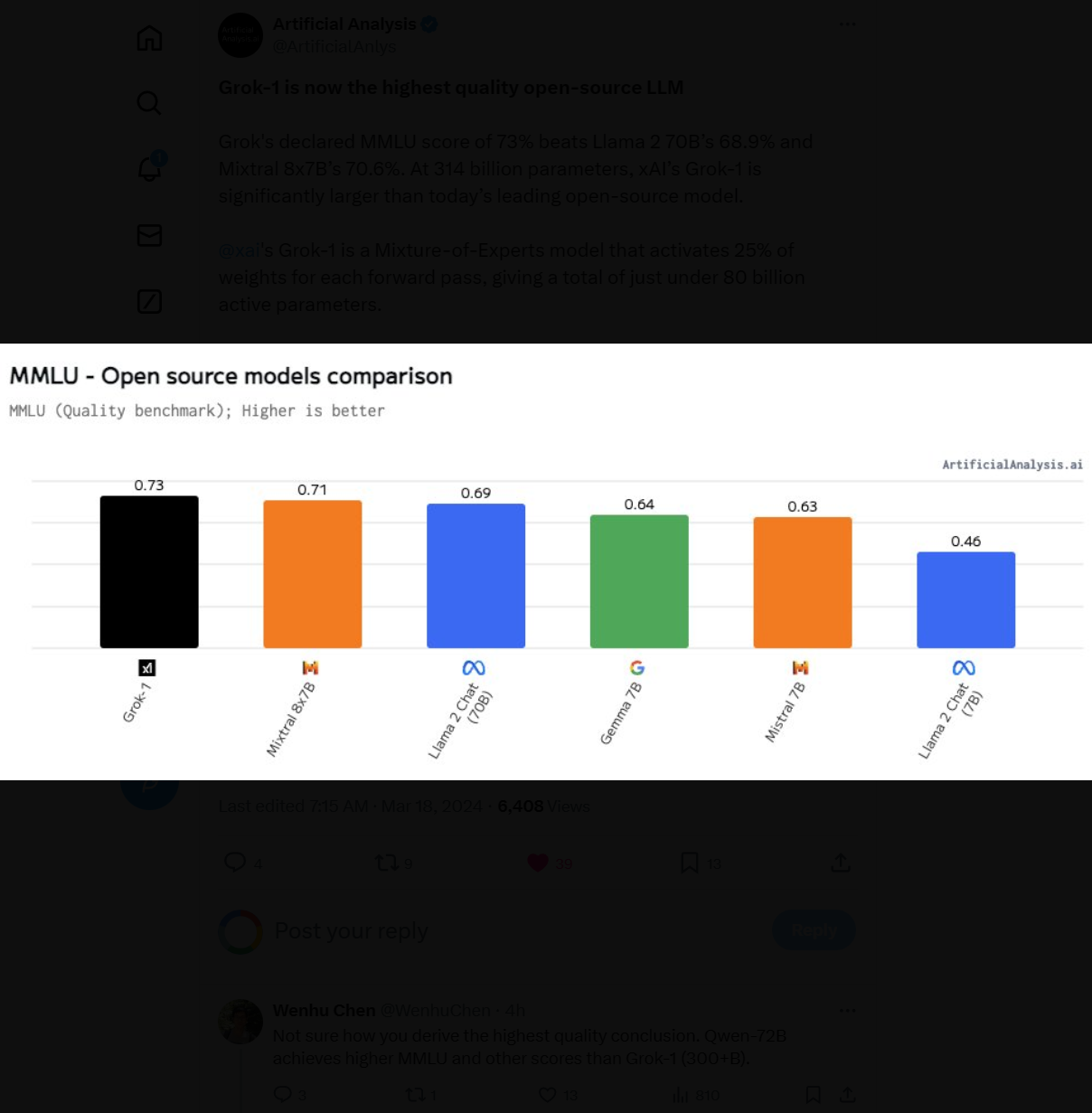
此前,马斯克在推特上宣布要开源旗下大模型公司开发的Grok-1大语言模型。一周后的现在,这个模型Grok-1正式宣布以Apache2.0开源协议开源,本文将针对Grok-1的技术部分进行介绍。

就在几个小时前,阿里巴巴开源了最新的一个推理大模型,QwQ-32B,该模型拥有类似o1、DeepSeek R1模型那样的推理能力,但是参数仅325亿,以Apache 2.0开源协议开源,这意味着大家可以完全免费商用。
预测在全球决策中发挥着关键作用。例如,关于COVID-19扩散的预测为国家封锁提供了信息,而经济预测则影响了利率的制定。这些预测通常依赖于人类专家的仔细判断,他们必须考虑来自各种来源的数据。由于人工智能系统能够处理大量的数据,它们在这个领域有可能非常有用。 为此,ML Safety举办了一个关于AI预测的竞赛,比赛的目的是建立一个机器学习模型,做出准确和校准的预测。
OpenAI发布了一个全新的针对逻辑推理优化的大语言模型o1模型。官方宣称其推理能力相比较当前的大语言模型(GPT-4o)有了大幅提升。OpenAI宣称o1模型在编程竞赛问题(Codeforces)中排名第89百分位,在美国数学奥林匹克(AIME)的资格赛中位列美国前500名,并且在物理、 生物和化学问题的基准测试(GPQA)上超越了人类博士水平的准确率。
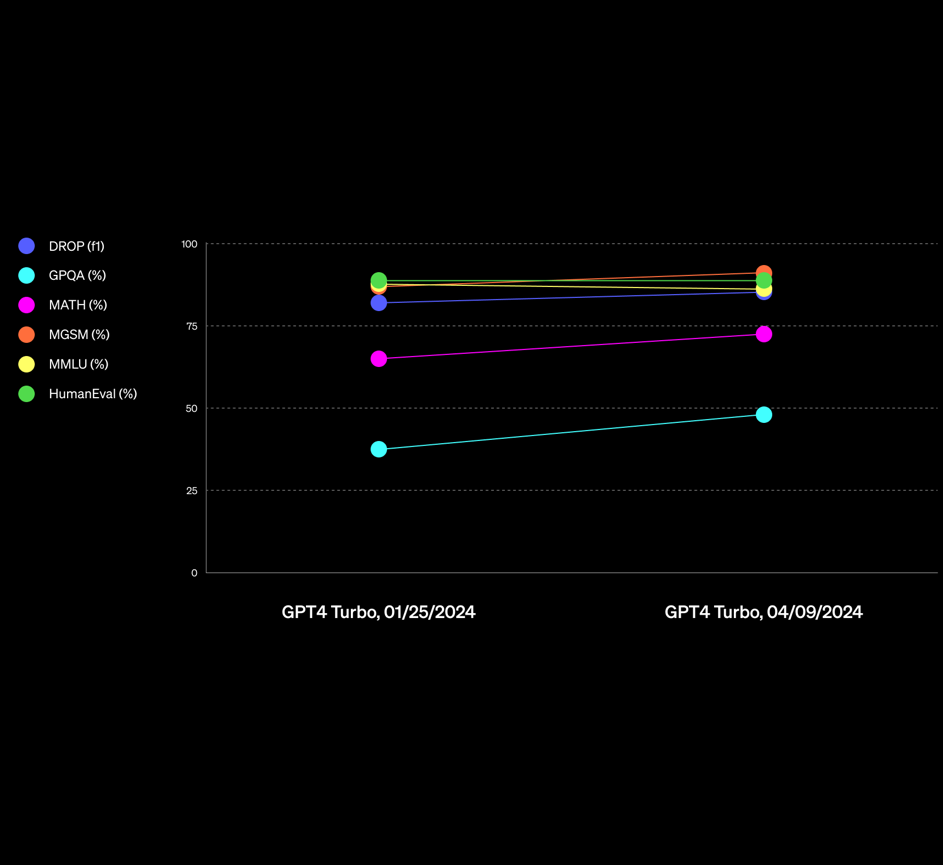
OpenAI的GPT-4一直是全球最强的大语言模型。但是在最近的一系列新模型对比中,已经有一些模型在某些领域被认为已经接近或者超过GPT-4了。而在前几天,OpenAI更新了一个新版本的GPT-4,是GPT-4-Turbo-2024-04-09,官方说该版本的GPT在推理和数学能力上有明显提升,而实测结果也很不错。在基准测试评测中,最高有19%的提升幅度!在GPT-4这样强的模型上有这样的提升幅度,十分不错!
今日推荐
谷歌官方高性能大规模高维数据处理库TensorStore发布!
【转载】全面解读ICML 2017五大研究热点 | 腾讯AI Lab独家解析
73亿参数顶级开源模型Mistral-7B升级到v0.2版本,性能与上下文长度均有增强。
加州大学欧文分校信息技术办公室开放基于GPT-4.5的ZotGPT服务测试
如何解决大模型微调过程中的知识遗忘?香港大学提出有监督微调新范式并开源新模型LLaMA Pro
70亿参数规模大模型新选择:Deci开源DeciLM-7B大模型,评测效果远超Llama2-7B,每秒可生成328个tokens。
腾讯发布了一个全新的大模型Hunyuan Turbo S:号称评测效果超过GTP-4o和DeepSeek V3等模型,但没有开源或者放开使用